Flume推送数据到SparkStreaming案例实战和内幕源码解密
本期内容:
1. Flume on HDFS案例回顾
2. Flume推送数据到Spark Streaming实战
3. 原理绘图剖析
1. Flume on HDFS案例回顾
上节课要求大家自己安装配置Flume,并且测试数据的传输。我昨天是要求传送的HDFS上。
文件配置:
~/.bashrc:
export FLUME_HOME=/usr/local/flume/apache-flume-1.6.0-bin
export FLUME_CONF_DIR=$FLUME_HOME/conf
PATH中增加:${FLUME_HOME}/bin;
拷贝conf/flume-conf.properties.template,更名为conf/flume-cong.properties,只写以下内容:
agent1表示代理名称
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
#配置source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/usr/local/flume/tmp/TestDir
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = timestamp
#配置sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://master:9000/library/flume
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=1
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d
#agent1.sinks.sink1.type=avro
#agent1.sinks.sink1.channel=channel1
#agent1.sinks.sink1.hostname=Master
#agent1.sinks.sink1.port=9999
#配置channel1
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir=/usr/local/flume/tmp/checkpointDir
agent1.channels.channel1.dataDirs=/usr/local/flume/tmp/dataDirs
flume-env.sh配置:
# export JAVA_HOME=/usr/lib/jvm/java-6-sun
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60
# Give Flume more memory and pre-allocate, enable remote monitoring via JMX
# export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
建立文件夹 /usr/local/flume/tmp/TestDir。
在hdfs上建立/library/flume文件夹。
flume的bin文件夹下启动Flume:
./flume-ng agent -n agent1 -c conf -f /usr/local/flume/apache-flume-1.6.0-bin/conf/flume-conf.properties -Dflume.root.logger=DEBUG,console
在/usr/local/flume/tmp/TestDir下,拷入测试用的文件,比如:NOTICE
flume 控制台会有一些相关信息:
16/04/22 11:03:49 INFO avro.ReliableSpoolingFileEventReader: Preparing to move file /usr/local/flume/tmp/TestDir/NOTICE to /usr/local/flume/tmp/TestDir/NOTICE.COMPLETED
16/04/22 11:03:51 INFO hdfs.HDFSDataStream: Serializer = TEXT, UseRawLocalFileSystem = false
16/04/22 11:03:51 INFO hdfs.BucketWriter: Creating hdfs://master:9000/library/flume/2016-04-22.1461294231806.tmp
16/04/22 11:03:52 INFO hdfs.BucketWriter: Closing hdfs://master:9000/library/flume/2016-04-22.1461294231806.tmp
16/04/22 11:03:52 INFO hdfs.BucketWriter: Renaming hdfs://master:9000/library/flume/2016-04-22.1461294231806.tmp to hdfs://master:9000/library/flume/2016-04-22.1461294231806
可以发现本地的NOTICE文件更名为NOTICE.COMPLETED。
用浏览器查询:http://localhost:50070/explorer.html#/library/flume,可看到Flume把NOTICE文件传送到 HDFS的/library/flume下,文件名为 2016-04-22.1461294231806。打开文件看内容可以验证。说明当Flume指定的源文件夹中有新文件时,Flume会自动将此文件,导入到Flume配置时指定的HDFS文件夹中。
一般正常业务情况下,应该是把Flume的数据放到Kafka中,然后让不同的数据消费者去消费数据。如果要在Flume和Kafka两者间做选择的话,则要看业务中数据是否持续不断的产生。如果是这样,则应该选择Kafka。如果产生的数据时大时小,甚至有些时间没有数据,则没必要用Kafka,可以节省资源。
2. Flume推送数据到Spark Streaming实战
现在我们不把Flume的数据导入到HDFS中,而是把数据推送到Spark Streaming中。
修改conf/flume-cong.properties文件,改导入到HDFS,变为推送到Spark Streaming。
#配置sink1
#agent1.sinks.sink1.type=hdfs
#agent1.sinks.sink1.hdfs.path=hdfs://master:9000/library/flume
#agent1.sinks.sink1.hdfs.fileType=DataStream
#agent1.sinks.sink1.hdfs.writeFormat=TEXT
#agent1.sinks.sink1.hdfs.rollInterval=1
#agent1.sinks.sink1.channel=channel1
#agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d
agent1.sinks.sink1.type=avro
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hostname=Master
agent1.sinks.sink1.port=9999
编写Spark Streaming应用的Java程序:
public class FlumePushData2SparkStreaming {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("FlumePushDate2SparkStreaming");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(30));
JavaReceiverInputDStream lines = FlumeUtils.createStream(jsc,"Master", 9999);
// 注意此处输入的event类型是SparkFlumeEvent类型。
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<SparkFlumeEvent, String>() {
@Override
public Iterable<String> call(SparkFlumeEvent event) throws Exception {
String line = new String(event.event().getBody().array());
return Arrays.asList(line.split(" "));
}
});
JavaPairDStream<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairDStream<String, Integer> wordsCount = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
wordsCount.print();
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}
代码中用到了FlumeUtils。我们剖析一下代码中用到的FlumeUtils。
以上代码中FlumeUtil的方法createStream:
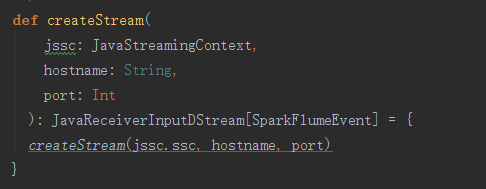
实际是调用以下createStream方法:
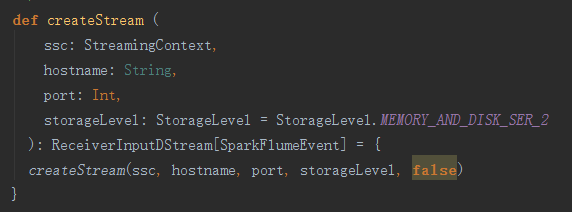
可以看到流处理默认的存储方式是,既在内存,又在磁盘中,同时做序列化,而且用两台机器。
继续看调用的createStream方法:

实际上返回的是FlumeInputDStream对象,而且事件是Flume所定义的事件SparkFlumeEvent。所以要注意,在以上Java代码做flatMap时,FlatMapFunction的输入类型必须是SparkFlumeEvent类型。
再看看FlumeInputDStream的代码:
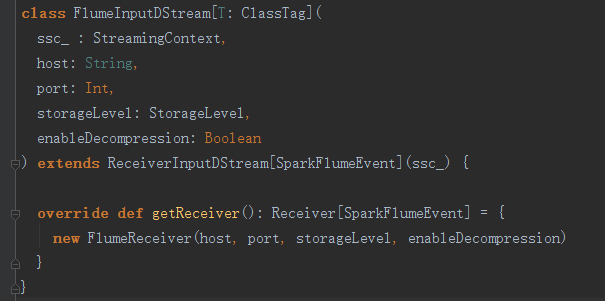
可以看到getReceiver返回的是用于接收数据的FlumeReceiver对象。再看FlumeReceiver:

可以发现Flume使用了Netty。如果搞分布式编程,要重视使用Netty。
把以上的应用Spark Streaming的Java程序运行起来。确认Flume也在运行。
我们找若干文件拷入TestDir文件夹,比如:flume下的若干文本文件。那么在Java运行的控制台,可以发现以下信息:

说明Flume推送数据到了Spark Streaming,Spark Streaming对数据及时进行了处理。
3. 原理绘图剖析

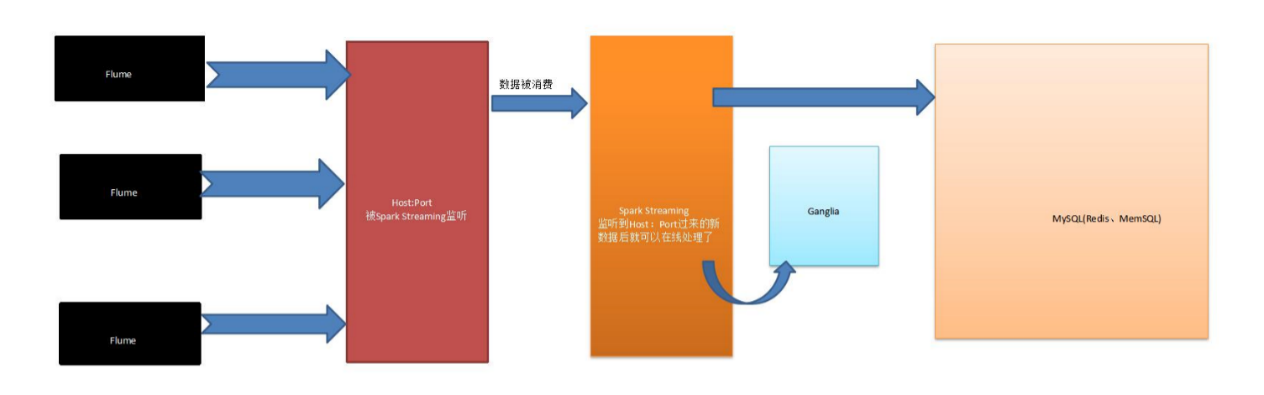
总结:
备注:87课
更多私密内容,请关注微信公众号:DT_Spark
Flume推送数据到SparkStreaming案例实战和内幕源码解密的更多相关文章
- 基于HDFS的SparkStreaming案例实战和内幕源码解密
一:Spark集群开发环境准备 启动HDFS,如下图所示: 通过web端查看节点正常启动,如下图所示: 2.启动Spark集群,如下图所示: 通过web端查看集群启动正常,如下图所示: 3.启动sta ...
- Spark Streaming updateStateByKey案例实战和内幕源码解密
本节课程主要分二个部分: 一.Spark Streaming updateStateByKey案例实战二.Spark Streaming updateStateByKey源码解密 第一部分: upda ...
- Spark Streaming从Flume Poll数据案例实战和内幕源码解密
本节课分成二部分讲解: 一.Spark Streaming on Polling from Flume实战 二.Spark Streaming on Polling from Flume源码 第一部分 ...
- SQL Server 2000向SQL Server 2008 R2推送数据
[文章摘要]最近做的一个项目要获取存在于其他服务器的一些数据,为了安全起见,采用由其他“服务器”向我们服务器推送的方式实现.我们服务器使用的是SQL Server 2008 R2,其他“服务器”使用的 ...
- WebService推送数据,数据结构应该怎样定义?
存放在Session有一些弊端,不能实时更新.server压力增大等... 要求:将从BO拿回来的数据存放在UI Cache里面,数据库更新了就通过RemoveCallback "告诉&qu ...
- java接口对接——调用别人接口推送数据
实际开发中经常会遇到要和其他平台或系统对接的情况,实际操作就是互相调用别人的接口获取或者推送数据, 当我们调用别人接口推送数据时,需要对方给一个接口地址以及接口的规范文档,规范中要包括接口的明确入参及 ...
- SuperSocket主动从服务器端推送数据到客户端
关键字: 主动推送, 推送数据, 客户端推送, 获取Session, 发送数据, 回话快照 通过Session对象发送数据到客户端 前面已经说过,AppSession 代表了一个逻辑的 socke ...
- httpclient post推送数据
客户端代码 /** * 从接口获取数据 * @param url 服务器接口地址 * @param json 传入的参数 若获取全部,此项为空 * @return 返回查询到的数据 * @throws ...
- Asp.net Core3.1+Vue 使用SignalR推送数据
本文就简单使用 往前端页面推送消息 SignalR 是什么 SignalR是一个.NET Core/.NET Framework的开源实时框架. SignalR的可使用Web Socket, Serv ...
随机推荐
- linux下源代码分析和阅读工具比较
Windows下的源码阅读工具Souce Insight凭借着其易用性和多种编程语言的支持,无疑是这个领域的“带头大哥”.Linux/UNIX环境下呢?似乎仍然是处于百花齐放,各有千秋的春秋战国时代, ...
- 【CZY选讲·Hja的棋盘】
题目描述 Hja特别有钱,他买了一个×的棋盘,然后Yjq到这个棋盘来搞事.一开始所有格子都是白的,Yjq进行次行操作次列操作,所谓一次操作,是将对应的行列上的所有格子颜色取反.现在Yjq希望搞事之后 ...
- bzoj1630/2023 [Usaco2007 Demo]Ant Counting
传送门:http://www.lydsy.com/JudgeOnline/problem.php?id=1630 http://www.lydsy.com/JudgeOnline/problem.ph ...
- week01-绪论报告
一.作业题目: 仿照三元组或复数的抽象数据类型写出有理数抽象数据类型的描述 (有理数是其分子.分母均为整数且分母不为零的分数). 有理数基本运算: 构造有理数T,元素e1,e2分别被赋以分子.分母值 ...
- c# tcplistener 与 client通信 服务端 今天写一下
using System; using System.Collections.Generic; using System.Data; using System.IO; using System.Lin ...
- SQL 整理
批量插入 insert into table select ... union all select... insert into table (...) values (...) , (...) i ...
- luogu 2709 小B的询问 莫队
题目链接 Description 小B有一个序列,包含\(N\)个\(1-K\)之间的整数.他一共有\(M\)个询问,每个询问给定一个区间\([L..R]\),求\(\sum_{i=1}^{K}c_i ...
- 基于Xen实现一种domain0和domainU的应用层数据交互高效机制
项目里有一个需求,domain0的应用层需要定时给domainU(hvm windows)的应用层传递一块数据,原来的方案是在domainU的应用层架设一个http服务器,监听在某个端口,然后需要塞数 ...
- Linux安转scala
1. 创建目录 > mkdir /opt/scala > cd /opt/scala 2. 下载scala压缩包到上述目录 scala-2.12.6.tgz 3. 解压缩.建立软连接 ...
- 【linux高级程序设计】(第九章)进程间通信-管道 1
Linux操作系统所支持的主要进程间的通信机制. 无名管道 PIPE cat test.txt| grep hello 上面这种管道,将一个命令的输出作为另一个命令的输入,而这种管道是临时的,命令执行 ...