Python读取MNIST数据集
MNIST数据集获取
MNIST数据集是入门机器学习/模式识别的最经典数据集之一。最早于1998年Yan Lecun在论文:
中提出。经典的LeNet-5 CNN网络也是在该论文中提出的。
数据集包含了0-9共10类手写数字图片,每张图片都做了尺寸归一化,都是28x28大小的灰度图。每张图片中像素值大小在0-255之间,其中0是黑色背景,255是白色前景。如下图所示:

MNIST共包含70000张手写数字图片,其中有60000张用作训练集,10000张用作测试集。原始数据集可在MNIST官网下载。
下载之后得到4个压缩文件:
train-images-idx3-ubyte.gz #60000张训练集图片 train-labels-idx1-ubyte.gz #60000张训练集图片对应的标签 t10k-images-idx3-ubyte.gz #10000张测试集图片 t10k-labels-idx1-ubyte.gz #10000张测试集图片对应的标签
将其解压,得到:
train-images-idx3-ubyte train-labels-idx1-ubyte t10k-images-idx3-ubyte t10k-labels-idx1-ubyte
MNIST二进制文件的存储格式
解压得到的四个文件都是二进制格式,我们如何获取其中的信息呢?这得首先了解MNIST二进制文件的存储格式(官网底部有介绍),以训练集图像文件train-images-idx3-ubyte为例:
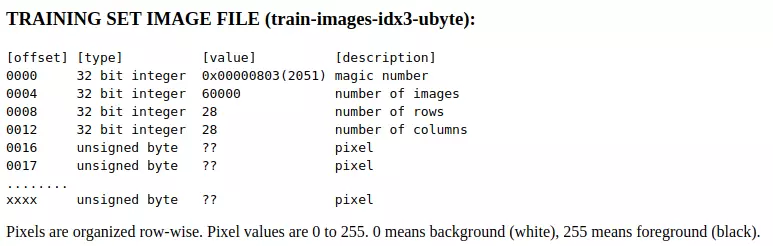
图像文件的
- 第1-4个byte(字节,1byte=8bit),即前32bit存的是文件的magic number,对应的十进制大小是2051;
- 第5-8个byte存的是number of images,即图像数量60000;
- 第9-12个byte存的是每张图片行数/高度,即28;
- 第13-16个byte存的是每张图片的列数/宽度,即28。
- 从第17个byte开始,每个byte存储一张图片中的一个像素点的值。
因为train-images-idx3-ubyte文件总共包含了60000张图片数据,按照以上的存储方式,我们算一下该文件的大小:
- 一张图片包含28x28=784个像素点,需要784bytes的存储空间;
- 60000张图片则需要784x60000=47040000 bytes的存储空间;
- 此外,文件开始处使用了16个bytes用于存储magic number、图像数量、图像高度和图像宽度,因此,训练集图像文件的大小应该是47040000+16=47040016 bytes。
我们查看解压后的train-images-idx3-ubyte文件的属性:
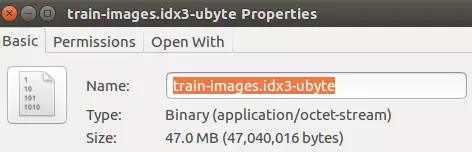
文件实际大小和我们计算的结果一致。
类似地,我们查看训练集标签文件train-labels-idx1-ubyte的存储格式:
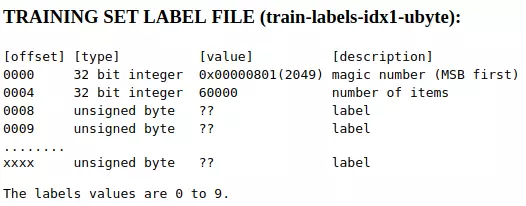
和图像文件类似:
- 第1-4个byte存的是文件的magic number,对应的十进制大小是2049;
- 第5-8个byte存的是number of items,即label数量60000;
- 从第9个byte开始,每个byte存一个图片的label信息,即数字0-9中的一个。
计算一下训练集标签文件train-labels-idx1-ubyte的文件大小:
- 1x60000+8=60008 bytes。
与该文件实际的大小一致:

另外两个文件,即测试集图像文件、测试集标签文件的存储方式和训练图像文件、训练标签文件相似,只是图像数量由60000变为10000。
使用python访问MNIST数据集文件内容
知道了MNIST二进制文件的存储方式,下面介绍如何使用python访问文件内容。同样以训练集图像文件train-images-idx3-ubyte为例:
import numpy as np
import matplotlib.pyplot as plt
'''试验transpose()
def back (a,b):
return a,b
if __name__ == '__main__':
a = np.array([[1,2,3],[11,12,13],[21,22,23]])
print(a)
b = np.array([[31,32,33],[41,42,43],[51,52,53]])
print(b)
a, b = transpose(back(a,b))
#a, b = back(a, b)
print(a)
print(b)
'''
# 数据加载器基类
class Loader(object):
def __init__(self, path, count):
'''
初始化加载器
path: 数据文件路径
count: 文件中的样本个数
'''
self.path = path
self.count = count
def get_file_content(self):
'''
读取文件内容
'''
f = open(self.path, 'rb')
content = f.read()
f.close()
return content
def to_int(self, byte):
'''
将unsigned byte字符转换为整数
'''
#print(byte)
#return struct.unpack('B', byte)[0]
return byte
# 图像数据加载器
class ImageLoader(Loader):
def get_picture(self, content, index):
'''
内部函数,从文件中获取图像
'''
start = index * 28 * 28 + 16
picture = []
for i in range(28):
picture.append([])
for j in range(28):
picture[i].append(
self.to_int(content[start + i * 28 + j]))
return picture
def get_one_sample(self, picture):
'''
内部函数,将图像转化为样本的输入向量
'''
sample = []
for i in range(28):
for j in range(28):
sample.append(picture[i][j])
return sample
def load(self):
'''
加载数据文件,获得全部样本的输入向量
'''
content = self.get_file_content()
data_set = []
for index in range(self.count):
data_set.append(
self.get_one_sample(
self.get_picture(content, index)))
return data_set
# 标签数据加载器
class LabelLoader(Loader):
def load(self):
'''
加载数据文件,获得全部样本的标签向量
'''
content = self.get_file_content()
labels = []
for index in range(self.count):
labels.append(self.norm(content[index + 8]))
return labels
def norm(self, label):
'''
内部函数,将一个值转换为10维标签向量
'''
label_vec = []
label_value = self.to_int(label)
for i in range(10):
if i == label_value:
label_vec.append(0.9)
else:
label_vec.append(0.1)
return label_vec
def get_training_data_set():
'''
获得训练数据集
'''
image_loader = ImageLoader('train-images.idx3-ubyte', 60000)
label_loader = LabelLoader('train-labels.idx1-ubyte', 60000)
return image_loader.load(), label_loader.load()
def get_test_data_set():
'''
获得测试数据集
'''
image_loader = ImageLoader('t10k-images.idx3-ubyte', 10000)
label_loader = LabelLoader('t10k-labels.idx1-ubyte', 10000)
return image_loader.load(), label_loader.load()
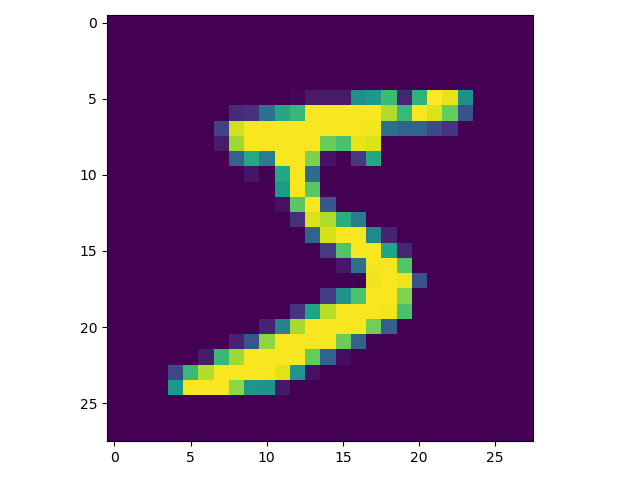
if __name__ == '__main__':
train_data_set, train_labels = get_training_data_set()
line = np.array(train_data_set[0])
img = line.reshape((28,28))
plt.imshow(img)
plt.show()
输出图片如下:
参考:
Python读取MNIST数据集的更多相关文章
- python读取mnist
python读取mnist 其实就是python怎么读取binnary file mnist的结构如下,选取train-images TRAINING SET IMAGE FILE (train-im ...
- mnist的格式说明,以及在python3.x和python 2.x读取mnist数据集的不同
有一个关于mnist的一个事例可以参考,我觉得写的很好:http://www.cnblogs.com/x1957/archive/2012/06/02/2531503.html #!/usr/bin/ ...
- python 将Mnist数据集转为jpg,并按比例/标签拆分为多个子数据集
现有条件:Mnist数据集,下载地址:跳转 下载后的四个.gz文件解压后放到同一个文件夹下,如:/raw Step 1:将Mnist数据集转为jpg图片(代码来自这篇博客) 1 import os 2 ...
- C++读取MNIST数据集
MNIST是一个标准的手写字符测试集. Mnist数据集对应四个文件: train-images-idx3-ubyte: training set images train-labels-idx1- ...
- python读取,显示,保存mnist图片
python处理二进制 python的struct模块可以将整型(或者其它类型)转化为byte数组.看下面的代码. # coding: utf-8 from struct import * # 包装成 ...
- C++基于文件流和armadillo读取mnist
发现网上大把都是用python读取mnist的,用C++大都是用opencv读取的,但我不怎么用opencv,因此自己摸索了个使用文件流读取mnist的方法,armadillo仅作为储存矩阵的一种方式 ...
- 深度学习(一)之MNIST数据集分类
任务目标 对MNIST手写数字数据集进行训练和评估,最终使得模型能够在测试集上达到\(98\%\)的正确率.(最终本文达到了\(99.36\%\)) 使用的库的版本: python:3.8.12 py ...
- 利用Python读取外部数据文件
不论是数据分析,数据可视化,还是数据挖掘,一切的一切全都是以数据作为最基础的元素.利用Python进行数据分析,同样最重要的一步就是如何将数据导入到Python中,然后才可以实现后面的数据分析.数 ...
- MNIST数据集转化为二维图片
#coding: utf-8 from tensorflow.examples.tutorials.mnist import input_data import scipy.misc import o ...
随机推荐
- AJAX--XMLHttpRequest对象
创建XMLHttpRequest对象 XMLHttpRequest是AJAX的基础. 所有现代浏览器(IE7+.Firefox.Chrome.Safari以及Opera)均内建XMLHttpReque ...
- C++ - cpprestsdk
Windows 安装方法: CMake 1.32+,生成过程会将 vcpkg 下载好,配置到系统环境变量,然后用 vcpkg 安装依赖库(github 上有列出需要的依赖库). Github 上的示例 ...
- Visual Studio 2017:SQLite/SQL Server Compact ToolBox使用
1.首先是下载安装插件:SQLite/SQL Server Compact Toolbox,也可以从工具-->扩展和更新-->联机-->搜索:SQLite/SQL Server Co ...
- MySQL-THINKPHP 商城系统一 商品模块的设计
在此之前,先了解下关于SPU及SKU的知识 SPU是商品信息聚合的最小单位,是一组可复用.易检索的标准化信息的集合,该集合描述了一个产品的特性.通俗点讲,属性值.特性相同的商品就可以称为一个SPU. ...
- 8.14-T1村通网(pupil)
题目大意 要建设一个村庄的网络 有两种操作可选 1.给中国移动交宽带费,直接连网,花费为 A. 2.向另外一座有网的建筑,安装共享网线,花费为 B×两者曼哈顿距离. 题解 显然的最小生成树的题 见 ...
- AcWing 852. spfa判断负环 边权可能为负数。
#include <cstring> #include <iostream> #include <algorithm> #include <queue> ...
- MySQL必知必会(第4版)整理笔记
参考书籍: BookName:<SQL必知必会(第4版)> BookName:<Mysql必知必会(第4版)> Author: Ben Forta 说明:本书学习笔记 1.了解 ...
- java.lang.IllegalStateException: Illegal access: this web application instance has been stopped already. Could not load [META-INF/services/com.alibaba.druid.filter.Filter].
九月 11, 2019 2:56:36 下午 org.apache.catalina.loader.WebappClassLoaderBase checkStateForResourceLoading ...
- Windows系统重装记录
材料: u盘(需4g以上) windows官方镜像 附:windows个版本比较 步骤: u盘格式化(为了装启动盘系统需要清空数),备份系统盘所需要的的数据 下载适合自己的官方镜像,可从该网站下载(官 ...
- 最新版的 vscode 怎么配置 Python?
请进 -- > https://www.zhihu.com/question/322530705/answer/860418884