利用模拟退火提高Kmeans的聚类精度
http://www.cnblogs.com/LBSer/p/4605904.html
Kmeans算法是一种非监督聚类算法,由于原理简单而在业界被广泛使用,一般在实践中遇到聚类问题往往会优先使用Kmeans尝试一把看看结果。本人在工作中对Kmeans有过多次实践,进行过用户行为聚类(MapReduce版本)、图像聚类(MPI版本)等。然而在实践中发现初始点选择与聚类结果密切相关,如果初始点选取不当,聚类结果将很差。为解决这一问题,本博文尝试将模拟退火这一启发式算法与Kmeans聚类相结合,实践表明这种方法具有较好效果,已经在实际工作中推广使用。
1 Kmeans算法原理
K-MEANS算法:输入:聚类个数k,以及包含 n个数据对象的数据。输出:满足方差最小标准的k个聚类。
处理流程:
(1) 从 n个数据对象选择 k 个对象作为初始聚类中心;
(2) 循环(3)到(4)直到每个聚类不再发生变化为止
(3) 根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
(4) 重新计算每个(有变化)聚类的均值(中心对象)
1.1 Step 1

1.2 Step 2
1.3 Step 3

1.4 Step 4
1.5 Step 5

2 初始点与聚类结果的关系
K means的结果与初始点的选择密切相关,往往陷于局部最优。

2.1 例子
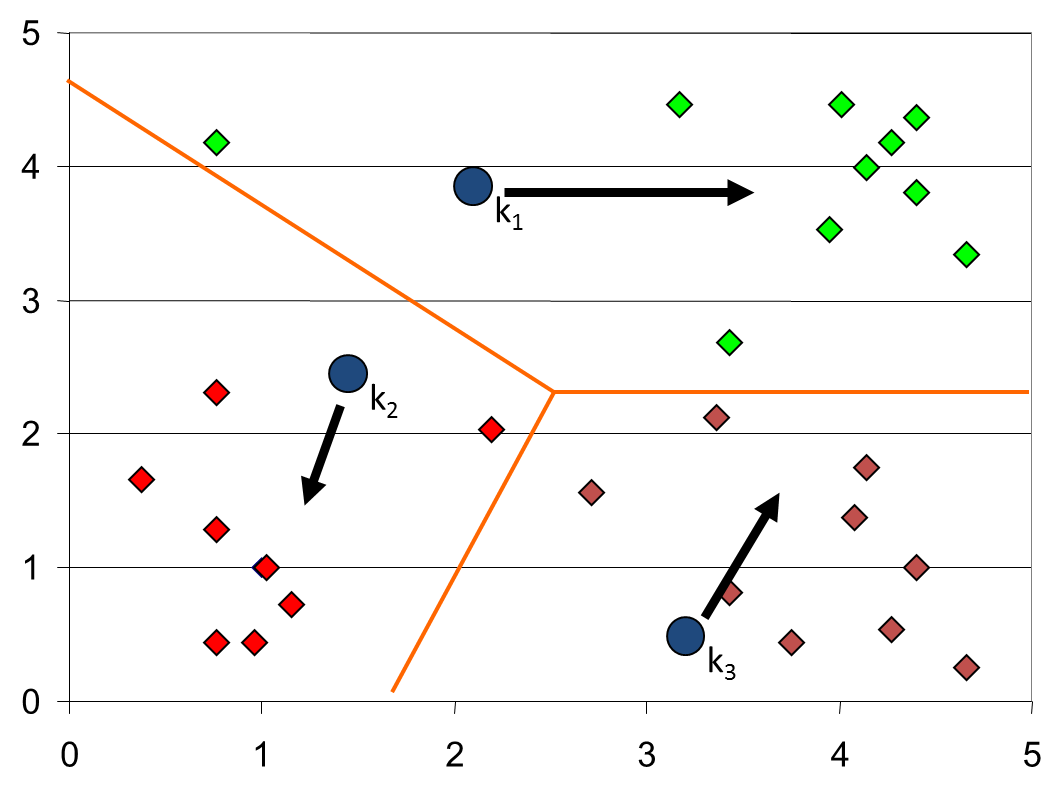
下面以一个实际例子来讲初始点的选择对聚类结果的影响。首先3个中心点(分别是红绿蓝三点)被随机初始化,所有的数据点都还没有进行聚类,默认全部都标记为红色,如下图所示:

迭代最终结果如下:

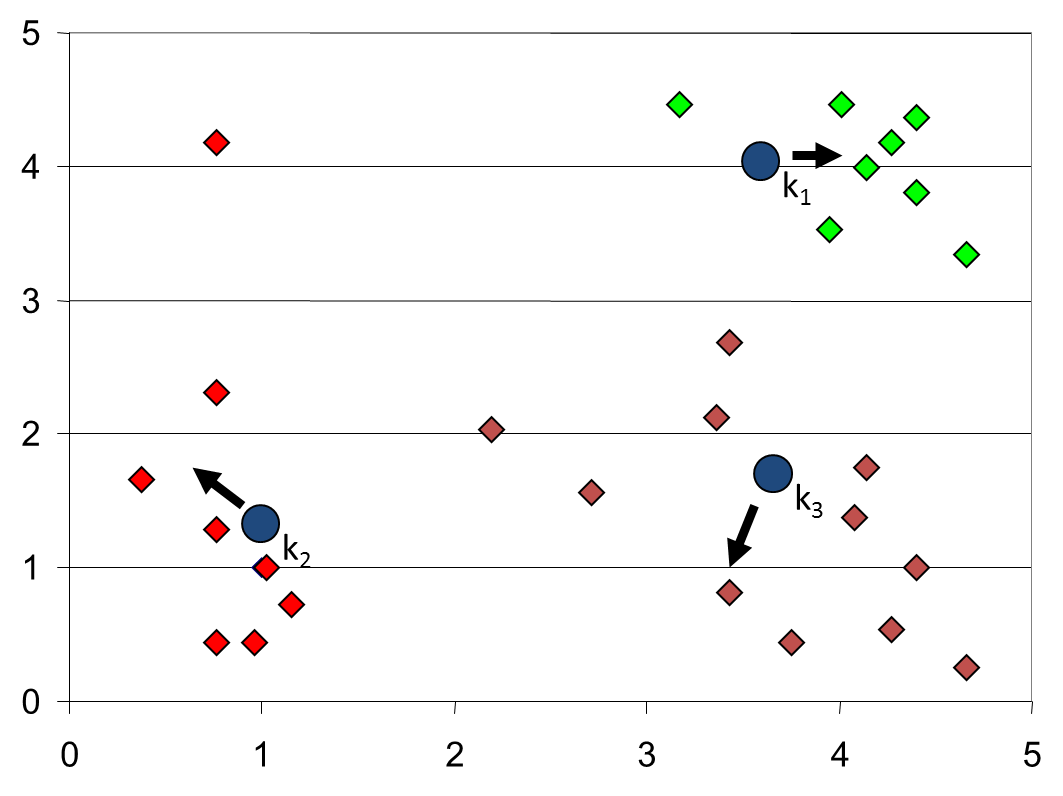
如果初始点为如下:
最终会收敛到这样的结果:
3 解决方法
那怎么解决呢?一般在实际使用中,我们会随机初始化多批初始中心点,然后对不同批次的初始中心点进行聚类,运行完后选择一个相对较优的结果。这种方法不仅不够自动,而且有较大概率得不到较优的结果。目前,研究较多的是将模拟退火、遗传算法等启发式算法与Kmeans聚类相结合,这样能大大降低陷于局部最优的困境。下图就是模拟退火的算法流程图。

4 实战
“纸上得来终觉浅,绝知此事要躬行”,仅知道原理而不去实践永远不能深刻掌握某一知识。本人实现了基于模拟退火的Kmeans算法以及普通的Kmeans算法,以便进行比较分析。
4.1 实验步骤
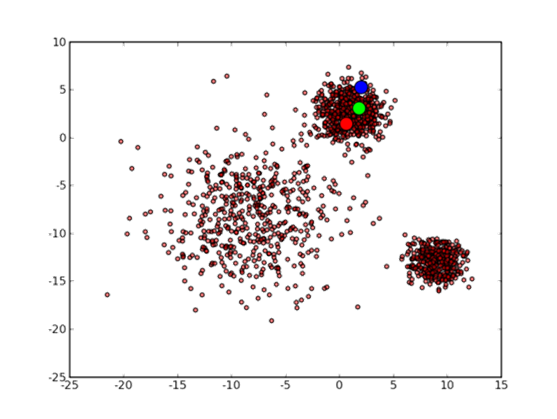
1)首先我们随机生成二维数据点以便用于聚类。

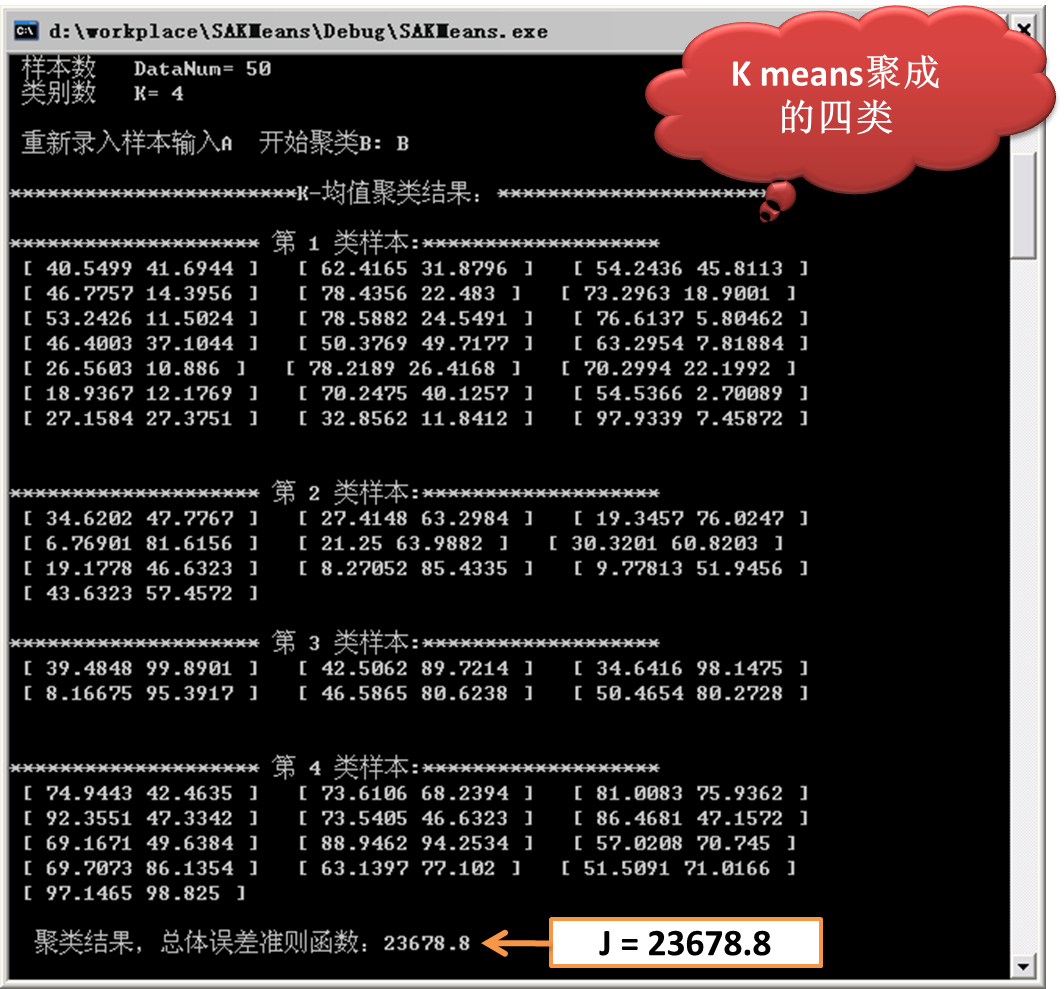
2)基于原生的Kmeans得到的结果。
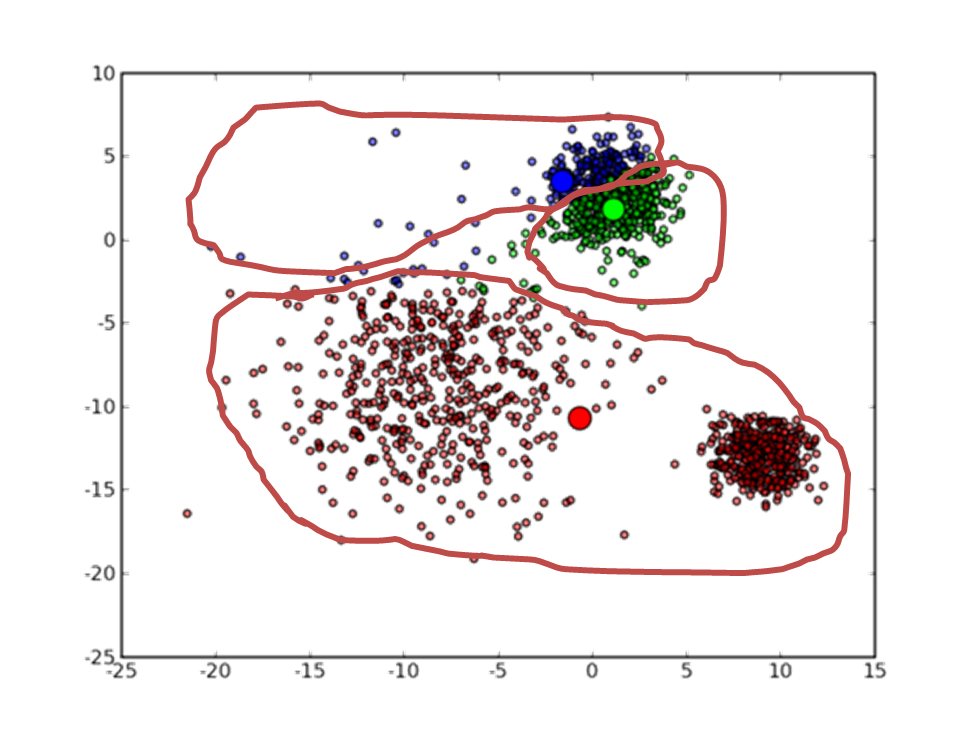
3)基于模拟退火的Kmeans得到的结果
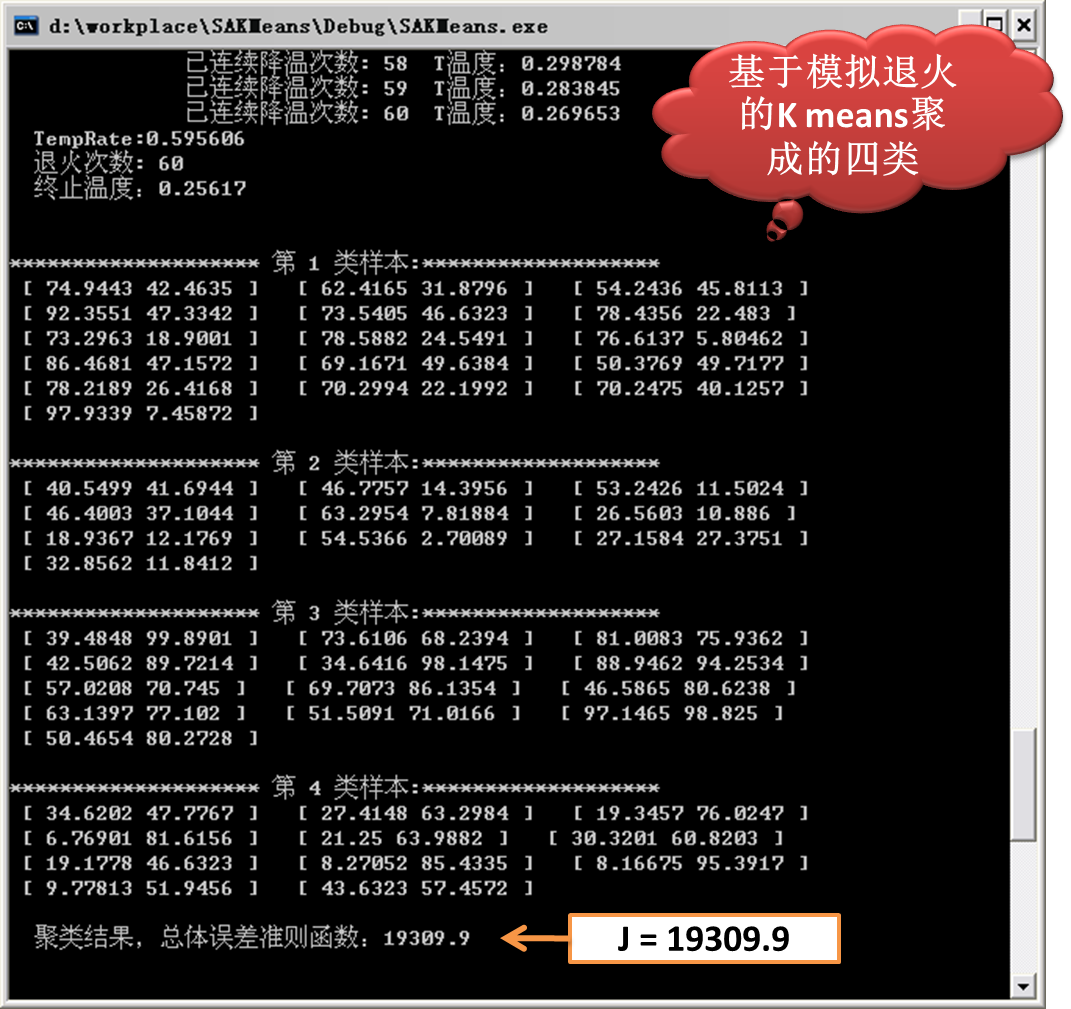
4.2 结论
由上图的实验结果可以看出,基于模拟退火的Kmeans所得的总体误差准则结果为:19309.9。
而普通的Kmeans所得的总体误差准则结果为:23678.8。
可以看出基于模拟退火的Kmeans所得的结果较好,当然,此算法的复杂度较高,收敛所需的时间较长,尤其是在大数据环境下。
利用模拟退火提高Kmeans的聚类精度的更多相关文章
- [.net 面向对象程序设计进阶] (18) 多线程(Multithreading)(三) 利用多线程提高程序性能(下)
[.net 面向对象程序设计进阶] (18) 多线程(Multithreading)(二) 利用多线程提高程序性能(下) 本节导读: 上节说了线程同步中使用线程锁和线程通知的方式来处理资源共享问题,这 ...
- [.net 面向对象程序设计进阶] (17) 多线程(Multithreading)(二) 利用多线程提高程序性能(中)
[.net 面向对象程序设计进阶] (17) 多线程(Multithreading)(二) 利用多线程提高程序性能(中) 本节要点: 上节介绍了多线程的基本使用方法和基本应用示例,本节深入介绍.NET ...
- [.net 面向对象程序设计进阶] (16) 多线程(Multithreading)(一) 利用多线程提高程序性能(上)
[.net 面向对象程序设计进阶] (16) 多线程(Multithreading)(一) 利用多线程提高程序性能(上) 本节导读: 随着硬件和网络的高速发展,为多线程(Multithreading) ...
- [转]利用/*+Ordered*/提高查询性能
[转]利用/*+Ordered*/提高查询性能 2009-02-06 10:46:27| 分类: Oracle | 标签: |字号大中小 订阅 消耗在准备利用Oracle执行计划机制提高查询性能 ...
- 利用mock提高效率
利用mock提高效率 谈到mock,就不得不讲前后端分离.理想情况下前后端不分离,由全栈的人以product和infrastructure的维度进行开发,效率是最高的.近些年来业务的复杂度越来越高,真 ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 利用sklearn实现k-means
基于上面的一篇博客k-means利用sklearn实现k-means #!/usr/bin/env python # coding: utf-8 # In[1]: import numpy as np ...
- 利用元数据提高 SQLFlow 血缘分析结果准确率
利用元数据提高 SQLFlow 血缘分析结果准确率 一.SQLFlow--数据治理专家的一把利器 数据血缘属于数据治理中的一个概念,是在数据溯源的过程中找到相关数据之间的联系,它是一个逻辑概念.数据治 ...
- 【转】利用python的KMeans和PCA包实现聚类算法
转自:https://www.cnblogs.com/yjd_hycf_space/p/7094005.html 题目: 通过给出的驾驶员行为数据(trip.csv),对驾驶员不同时段的驾驶类型进行聚 ...
随机推荐
- 上传文件时$_FILES为空的解决方法
上传视频的时候打印$_FILES为空,小的文件就没问题,后来发现是因为传的文件太大, 出现这个问题的原因主要有两个:表单原因或者php设置原因: 1,表单类型: 上传文件的表单编码类型必须设置成 en ...
- window的git extensions保存密码
git extensions每次pull与push均要输入密码,为解决该问题,执行以下操作: win+r,在运行中输入:%USERPROFILE% 找到其中的.gitconfig文件,找到[crede ...
- SQLServer语句 汇总
SQL Server语句 序号 功能 语句 1 创建数据库(创建之前判断该数据库是否存在) if exists (select * from sysdatabases where name='data ...
- search--搜索引擎的使用笔记
重度使用 完全匹配搜索 “”把搜索词放在双引号中 搜索不包含该词 减号- 常用的通配符 星号* 站内搜索site docker site:http://blog.daocloud.io/ 扩大范围搜索 ...
- Servlet调用过程整理
- SAS文档:简单的随机点名器
本次实验,我们设计了一个简单的随机点名系统,下面我来介绍一下它的SRS文档. 1.功能需求: 1.1 模块1 在此模块中,我们设置了RandomName类,创建一个随机点名器,里面加入了所在课程的名单 ...
- SD-WAN技术分析
1.概述 转载须注明来自 SDNLAB并附上本文链接. 本文链接:http://www.sdnlab.com/17810.html 宽带接入以及Internet骨干网容量的持续提升,促使企业WAN技术 ...
- 前端利器:SASS基础与Compass入门
SASS是Syntactically Awesome Stylesheete Sass的缩写,它是css的一个开发工具,提供了很多便利和简单的语法,让css看起来更像是一门语言,这种特性也被称为“cs ...
- oracle学习
在平时的工作学习中,经常需要使用到oracle数据库,将平时用到的一些技巧记录在这里,以便以后随时可以翻阅. 1.日期类型的比较 插入日期时,经常会使用sysdate来插入数据,但sysdate插入的 ...
- MySQL 半同步复制
在主库初次启动时,执行如下语句加载semisync_master插件: mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_m ...