Kafka学习笔记(3)----Kafka的数据复制(Replica)与Failover
1. CAP理论
1.1 Cosistency(一致性)
通过某个节点的写操作结果对后面通过其他节点的读操作可见。
如果更新数据后,并发访问的情况下可立即感知该更新,称为强一致性
如果允许之后部分或全部感知不到该更新,称为弱一致性。
若在之后的一段时间(通常该时间不是固定的)后,一定可以感知到该更新,称为最终一致性。
1.2 Availability(高可用性)
即是任何一个没有发生故障的节点必须在有限的时间内返回合理的结果(不论是正确的还是错误的)。
1.3 Partition tolerance(分区容错性)
部分节点宕机或者是无法与其他节点通信时,各分区间还可以保持分部式系统的功能,比如上海和北京两个网络分区,当上海分区光纤或其他原因导致网络不通时,北京上海两个分区之间不可通信,但是最起码要保证北京的分区中的分布式系统功能可用。
1.4 CAP理论
分布式系统中,一致性,可用性,分区容忍性最多只可同时满足两个,但是一般分区容错性都是需要保障的,因此很多时候都是在可用性和一致性之间做权衡。如下一幅图讲解了CP和AP的两种模式的具体表现形式:
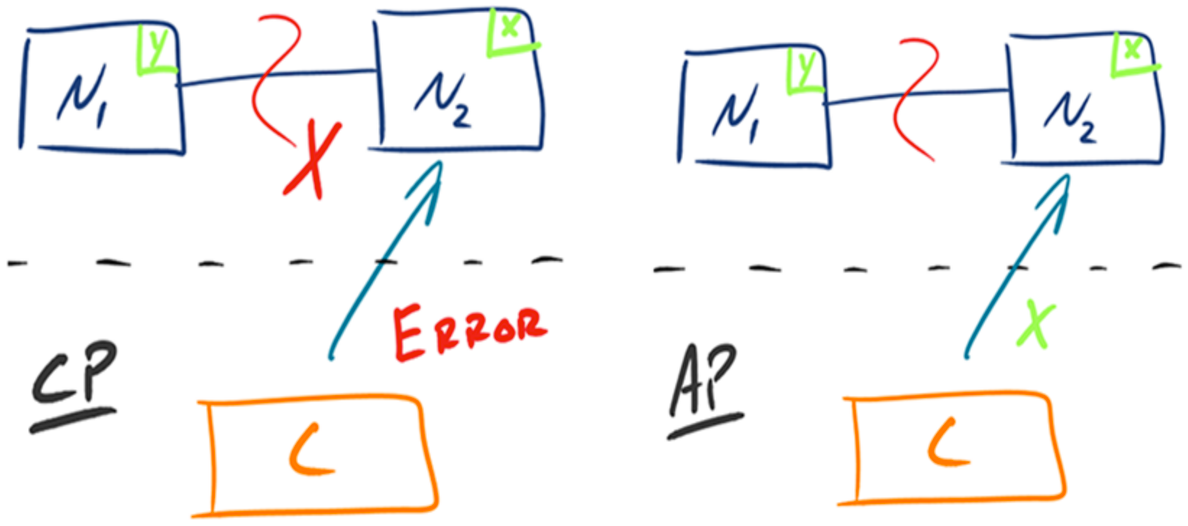
首先看CP模式,N1和N2之间代表了网络通信,C表示客户端,X表示新写入的数据,Y表示旧数据,当C向N2发起请求时,由于N2与N1之间网络通信异常,会导致N2不能同步到N1中的x,在保证一致性的情况下,此时N2不会正常返回处理结果,要么是等待网络连接成功,将N1的Y获取过来,保证数据一致,要么系统出现错误,这样的情况是不能保证高可用的,但是保证了数据一致性。
AP模式下,N1和N2之间代表了网络通信,C表示客户端,X表示新写入的数据,Y表示旧数据,当C向N2发起请求时,由于N2与N1之间网络通信异常,会导致N2不能同步到N1中的X,但是N2不会等待N1连接成功,或是返回错误信息,而是返回之前老的数据x,这样系统能够正常的运行,但是数据的一致性并没有保证,此时选择了系统的高可用方案。
1.5 一致性的方案
1.5.1 Master-slave(主从模式)
RDBMS的读写分离即为典型的Master-slave方案
同步复制可保证强一只性,但是会行影响性能(因为Master必须要等待所有的salve都接收到到更新才能返回)
异步复制提高可用性,但是会降低一致性,因为Master只需要自己写操作完成,就立即返回,同时向Slave进行复制,这期间可能会出现某个或多个Slave由于网络或其他原因没有更新到数据,造成数据不一致性。
1.5.2 WNR
主要用于去中心化(P2P)的分布式系统中。DynamoDB与Cassandra即采用此方案,N代表副本数,W代表每次写操作要保证的最少写成功的副本数,R代表每次读至少读取的副本数,当W+R>N时,可保证每次读取的数据至少有一个副本具有最新的更新,多个写操作的顺序难以保证,可能导致多副本间的写操作顺序不一致,Dynamo通过向量时钟保证最终一致性。这里可以通过时间戳或者是自增主键之类的方式来保证过滤出读取的最新的数据。
1.5.3 Paxos及其变种
Google的Chubby,Zookeeper的Zab,RAFT等
2. Kafka的数据复制(Replica)
Kafka提供了Replica保证了数据一致性
2.1 Replica
当某个Topic的replication-factor为N切N大于1时,每个Partition都会有N个副本(Replica),Replica的个数小于等于Broker数,即对每个Partition而言每个Broker上只会有一个Replica,因此可用Broker ID表示Replica,所有Partition的所有Replica默认情况会均匀分布到所有Broker上,如图:
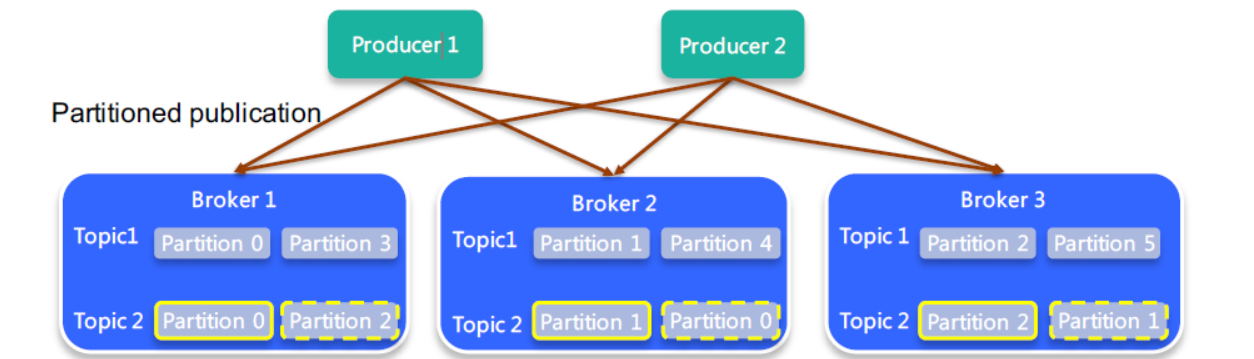
图中可以看到,Broker中存的是Topic2的Partition0和Topic2的Partition2的Replica,但是在Broker2中却存了Topic2的Partition1和Topic2的Partition0的Replica,所以默认的Partition都是分布在集群节点上的,replica也一样。这就可以保证到某个节点挂掉之后,其他的节点中保存的replica仍然可以向消费者推送或被拉取消息,保证消息不丢失。
注意:
假如当前我们搭建了三个Broker的集群,但是我此时指定4个Replica时,会出现org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 4 larger than available brokers: 3异常,如图:

2.2 Data Replication(数据复制)要解决的问题
2.2.1 如何Propagate(备份)消息
如下图:
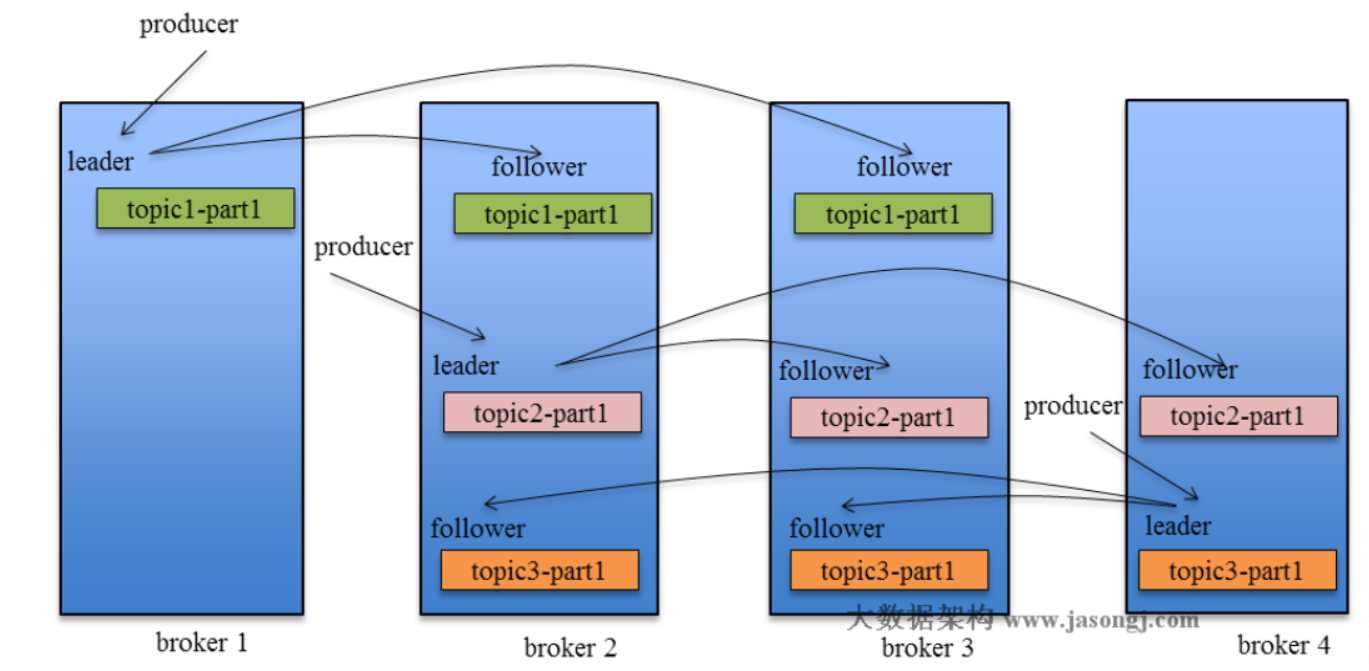
当producer想leader节点发送消息时,其余follower节点(个人理解跟slave类似)将会如其他mq的consumer一样去从主节点的topic中将数据拉取或被推送到自身节点中。这样当leader节点挂掉之后,consumer访问集群时,仍然可以从其他的follower中获取到最新数据,防止了数据丢失。
2.2.2 何时Commit
ISR: Leader会维护一个与其基本保持同步的Replica列表,该列表称为ISR(in-sync Replica),如果一个Follower比Leader落后太多,或者超过一定时间未发起数据复制请求,则Leader将其从ISR中移除,当ISR中所有Replica都向Leader发送ACK时,Leader即Commit(告诉Producer消息发送成功)。
Commit策略
1. 在Server中配置
replica.lag.time.max.ms:默认100000,最大未发起数据复制请求的时间。
replica.lag.max.messages:最大落后消息数,根据自身需要配置
2. Topic配置
min.insync.replicas=1: ISR列表最小个数,默认1,只有当request.required.acks为-1时才生效,如果ISR中的副本数少于min.insync.replicas配置的数量时,客户端会返回异常:org.apache.kafka.common.errors.NotEnoughReplicasExceptoin: Messages are rejected since there are fewer in-sync replicas than required。
3. Produce配置
request.required.acks=1,默认为1,roducer发送数据到leader,leader写本地日志成功,返回客户端成功;此时ISR中的副本还没有来得及拉取该消息,leader就宕机了,那么此次发送的消息就会丢失,当为-1时,当producer设置request.required.acks为-1时,min.insync.replicas指定replicas的最小数目(必须确认每一个repica的写数据都是成功的),如果这个数目没有达到,producer会产生异常。
2.2.3 如何处理Replica恢复
如图:
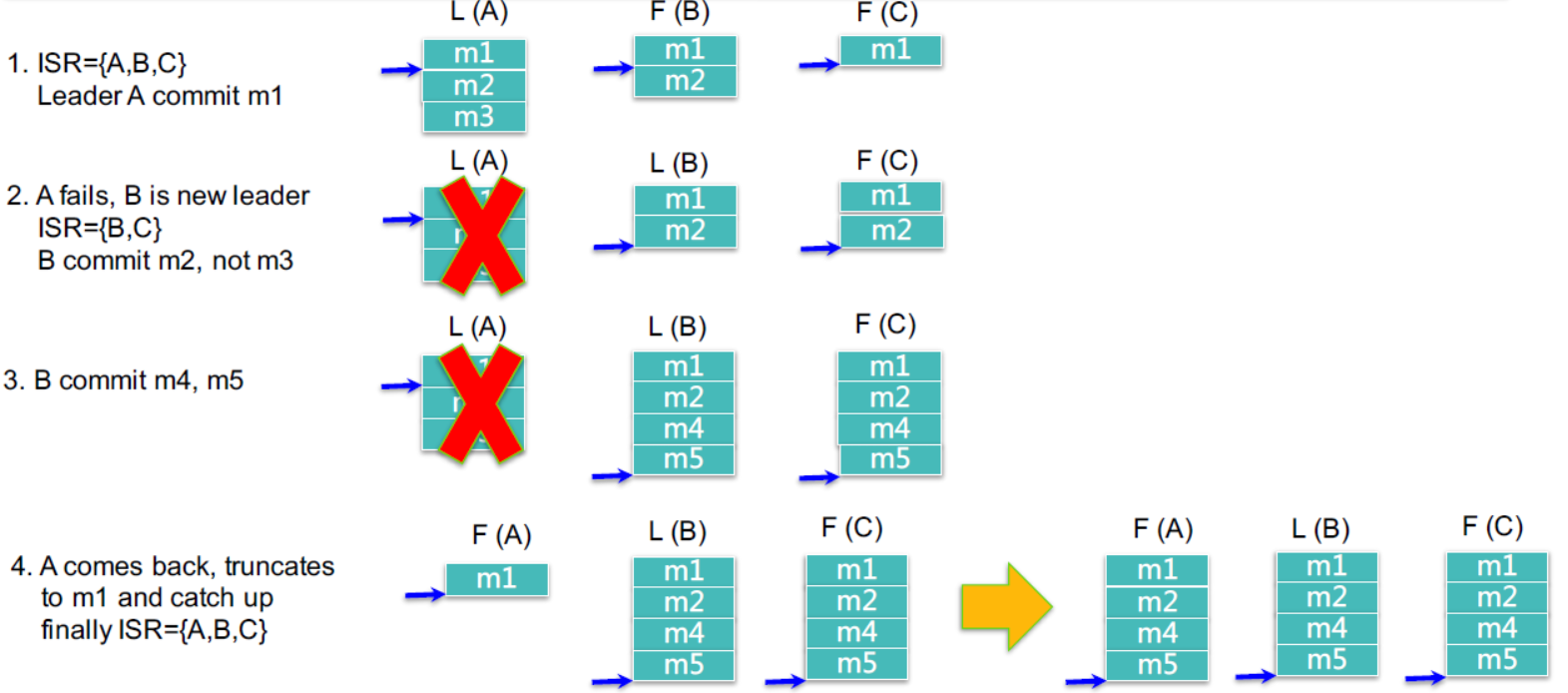
1. 可以看到SR={A,B,C},Leader(A)节点中存在m1,m2,m3三条消息,F(B)存在m1,m2两条消息,f(c)只存在m1一消息,所以这里只会提交m1这条消息,因为m2这条消息还没有在ISR中完成复制。它只会提交三个ISR中都存在的消息。
2. 当L(A)在将消息m2复制到B,C之后挂掉,此时ISR中只有{B,C},B被选举成为新的主节点,当m2,m1都存在于B,C节点中时,B将会提交m1,m2两条消息,不会提交m3消息。
3. 此时消息将都会发送到B节点上,C节点同步了B节点中的新发的消息m4,m5之后,将会提交m4,m5.
5.此时A节点连接集群成功或重启,可以使用了,它会从B节点中同步从m1,到m5的消息,直到它的消息与B和C中的一致为止,此时的Replica将会变成ISR={A,B,C},完成了Replica的恢复。这里我们发现m3并没有存在了,这里并不是丢失了,只是当没有主节点提交m3这条消息时,它将会自动反馈到Producer,Producer会重试,或做其他处理,当重试成功后可能m3消息将会append到m5的后面,所以consumer消费消息时,我们保证的顺序性不是producer发送消息的顺序,而是commit时的顺序。
2.2.4 如何处理Replica全部宕机
当ISR中的Replica全部宕机时,可以通过如下方式处理:
1. 等待ISR中任一Replica恢复,并选它为Leader。
缺点:等待时间较长,降低可用性(因为不能使用所有集群节点),因此或ISR中的所有Replica都无法恢复或者数据丢失,则该Partition将永不可用。
2. 选择第一个恢复的Replica为新的Leader,无论它是否在ISR中。
缺点:并未包含所有已被之前Leader Commit过的消息(因为它不在之前的ISR中),因此会造成数据丢失,但是它提高了可用节点的范围,可用性比较高。
Kafka学习笔记(3)----Kafka的数据复制(Replica)与Failover的更多相关文章
- Kafka学习笔记之Kafka性能测试方法及Benchmark报告
0x00 概述 本文主要介绍了如何利用Kafka自带的性能测试脚本及Kafka Manager测试Kafka的性能,以及如何使用Kafka Manager监控Kafka的工作状态,最后给出了Kafka ...
- Kafka学习笔记之Kafka High Availability(上)
0x00 摘要 Kafka在0.8以前的版本中,并不提供High Availablity机制,一旦一个或多个Broker宕机,则宕机期间其上所有Partition都无法继续提供服务.若该Broker永 ...
- Kafka学习笔记1——Kafka的安装和启动
一.准备工作 1. 安装JDK 可以用命令 java -version 查看版本
- Kafka学习笔记之Kafka Consumer设计解析
0x00 摘要 本文主要介绍了Kafka High Level Consumer,Consumer Group,Consumer Rebalance,Low Level Consumer实现的语义,以 ...
- Kafka学习笔记之Kafka背景及架构介绍
0x00 概述 本文介绍了Kafka的创建背景,设计目标,使用消息系统的优势以及目前流行的消息系统对比.并介绍了Kafka的架构,Producer消息路由,Consumer Group以及由其实现的不 ...
- Kafka学习笔记之Kafka三款监控工具
0x00 概述 在之前的博客中,介绍了Kafka Web Console这 个监控工具,在生产环境中使用,运行一段时间后,发现该工具会和Kafka生产者.消费者.ZooKeeper建立大量连接,从而导 ...
- Kafka学习笔记之Kafka自身操作日志的清理方法(非Topic数据)
0x00 概述 本文主要讲Kafka自身操作日志的清理方法(非Topic数据),Topic数据自己有对应的删除策略,请看这里. Kafka长时间运行过程中,在kafka/logs目录下产生了大量的ka ...
- Kafka学习笔记之Kafka High Availability(下)
0x00 摘要 本文在上篇文章基础上,更加深入讲解了Kafka的HA机制,主要阐述了HA相关各种场景,如Broker failover,Controller failover,Topic创建/删除,B ...
- 【kafka学习笔记】kafka的基本概念
在了解了背景知识后,我们来整体看一下kafka的基本概念,这里不做深入讲解,只是初步了解一下. kafka的消息架构 注意这里不是设计的架构,只是为了方便理解,脑补的三层架构.从代码的实现来看,kaf ...
- Kafka学习笔记之Kafka日志删出策略
0x00 概述 kafka将topic分成不同的partitions,每个partition的日志分成不同的segments,最后以segment为单位将陈旧的日志从文件系统删除. 假设kafka的在 ...
随机推荐
- [luogu3244 SHOI2016] 黑暗前的幻想乡(容斥原理+矩阵树定理)
传送门 Description 给出 n 个点和 n−1 种颜色,每种颜色有若干条边.求这张图多少棵每种颜色的边都出现过的生成树,答案对 109+7 取模. Input 第一行包含一个正整数 N(N& ...
- Python 爬虫的代理 IP 设置方法汇总
本文转载自:Python 爬虫的代理 IP 设置方法汇总 https://www.makcyun.top/web_scraping_withpython15.html 需要学习的地方:如何在爬虫中使用 ...
- GOF23设计模式之原型模式
GOF23设计模式之原型模式 1)通过 new 产生一个对象需要飞船繁琐的数据准备或访问权限,则可以使用原型模式. 2)就算 java 中的克隆技术,以某个对象为原型,复制出新的对象.显然,新的对象具 ...
- AM335X开发板+4G模块 调试小结
1.找到开发版配套资料中的linux内核源码包linux-3.2.0-Litev2.3-nand-2017-3-24.tar.gz 2.解压内核源码包,打开内核源码文件 option.c(路径为 dr ...
- Orcale用户管理
类 ------表 对象----行 属性----列 软件开发流程: 需求调研 需求分析 概要分析 详细分析 编码 测试 上线 维护 论坛: 1.注册和登录 2.发帖,回帖(关注,浏览数) 用户:(昵称 ...
- PCA降维技术
PCA降维技术 PCA 降维 Fly Time: 2017-2-28 主成分分析(PCA) PCA Algorithm 实例 主成分分析(PCA) 主成分分析(Principal Component ...
- HDOJ1796 How many integers can you find(dfs+容斥)
How many integers can you find Time Limit: 12000/5000 MS (Java/Others) Memory Limit: 65536/32768 ...
- IOS算法(二)之选择排序
选择排序: 每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在已排好序的数列的最后.直到所有待排序的数据元素排完. 选择排序是不稳定的排序方法. 一. 算法描写叙述 选择排序:比方在一 ...
- php连接符
php连接符 很多时候我们需要将几个字符串连接起来显示,在PHP中,字符串之间使用 “点” 来连接,也就是英文中的半角句号 " . " ." . " 是字符串连 ...
- php如何将网上的图片下载到本地
<?phpheader("Content-Type: application/force-download");header("Content-Dispositio ...