Elasticsearch之curl删除
扩展下,
Elasticsearch之curl删除索引库
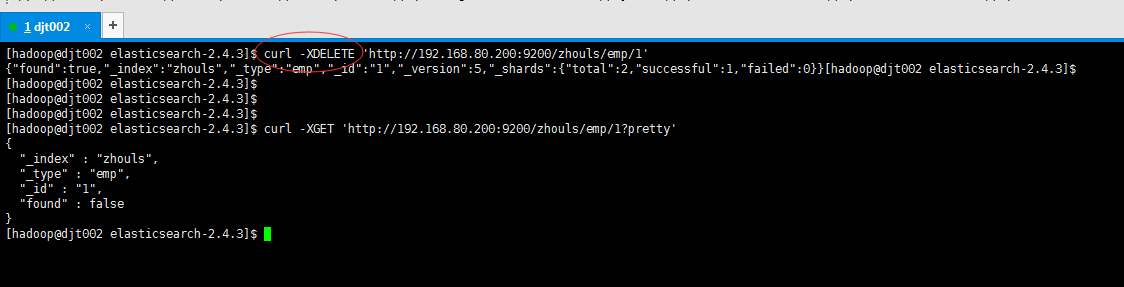
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XDELETE 'http://192.168.80.200:9200/zhouls/emp/1'
{"found":true,"_index":"zhouls","_type":"emp","_id":"1","_version":5,"_shards":{"total":2,"successful":1,"failed":0}}[hadoop@djt002 elasticsearch-2.4.3]$
[hadoop@djt002 elasticsearch-2.4.3]$
[hadoop@djt002 elasticsearch-2.4.3]$
[hadoop@djt002 elasticsearch-2.4.3]$
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/1?pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "1",
"found" : false
}
[hadoop@djt002 elasticsearch-2.4.3]$
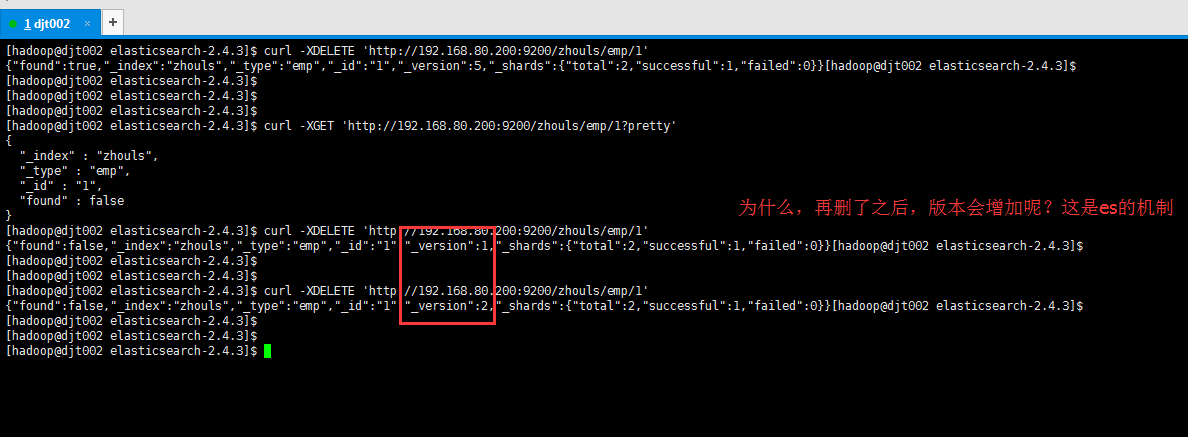
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XDELETE 'http://192.168.80.200:9200/zhouls/emp/1'
{"found":false,"_index":"zhouls","_type":"emp","_id":"1","_version":1,"_shards":{"total":2,"successful":1,"failed":0}}[hadoop@djt002 elasticsearch-2.4.3]$
[hadoop@djt002 elasticsearch-2.4.3]$
[hadoop@djt002 elasticsearch-2.4.3]$
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XDELETE 'http://192.168.80.200:9200/zhouls/emp/1'
{"found":false,"_index":"zhouls","_type":"emp","_id":"1","_version":2,"_shards":{"total":2,"successful":1,"failed":0}}[hadoop@djt002 elasticsearch-2.4.3]$
es的机制,第一次删除之后,在60秒之后,执行删除命令,则version变为1,又开始增加了。(作为了解,不必感到惊讶)
ES的删除操作补充知识
如果文档存在,es会返回200 ok的状态码,found属性值为true,_version属性的值+1。
如果文档不存在,es会返回404 Not Found的状态码,found属性值为false,但是_version属性的值依然会+1,这个就是内部管理的一部分,它保证了我们在多个节点间的不同操作的顺序都被正确标记了。
注意:删除一个文档也不会立即生效,它只是被标记成已删除。Elasticsearch将会在你之后添加更多索引的时候才会在后台进行删除内容的清理。
ES删除总结
ES的删除操作,也是不会立即生效,跟更新操作类似。只是会被标记为已删除状态,ES后期会自动删除。
好比,你删除的操作一步一步累积,当达到它上限时,等你删除几十条数据后,ES我一次性删除,这样可以节省磁盘IO。
这些简单的es删除操作,容易的就在生产环境里,手动输入。复杂的,用java代码去实现。
Elasticsearch之curl删除的更多相关文章
- Elasticsearch之curl删除索引库
关于curl创建索引库的介绍,请移步 Elasticsearch之curl创建索引库 [hadoop@djt002 elasticsearch-2.4.3]$ curl -XPUT 'http://1 ...
- Elasticsearch之CURL命令的DELETE
也可以看我写的下面的博客 Elasticsearch之curl删除 Elasticsearch之curl删除索引库 删除,某一条数据,如下 [hadoop@master elasticsearch-] ...
- ElasticSearch之CURL操作(有空再去整理)
https://www.cnblogs.com/jing1617/p/8060421.html ElasticSearch之CURL操作 CURL的操作 curl是利用URL语法在命令行方式下工 ...
- Elasticsearch之curl创建索引库
关于curl的介绍,请移步 Elasticsearch学习概念之curl 启动es,请移步 Elasticsearch的前后台运行与停止(tar包方式) Elasticsearch的前后台运行与停止( ...
- Elasticsearch之CURL命令的UPDATE
对于,Elasticsearch之CURL命令的UPDATE包括局部更新和全部更新.可以去看我写的另一篇博客. Elasticsearch之更新(全部更新和局部更新) 总结: ES全部更新,使用PUT ...
- Elasticsearch之curl创建索引
前提,是 Elasticsearch之curl创建索引库 [hadoop@djt002 elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.200: ...
- Elasticsearch之CURL命令的GET
这是个查询命令. 前期博客 Elasticsearch之CURL命令的PUT和POST对比 1. 以上是根据员工id查询. 即在任意的查询字符串中添加pretty参数,es可以得到易于我们识别的jso ...
- Elasticsearch之curl创建索引库和索引时注意事项
前提, Elasticsearch之curl创建索引库 Elasticsearch之curl创建索引 注意事项 1.索引库名称必须要全部小写,不能以下划线开头,也不能包含逗号 2.如果没有明确指定索引 ...
- Elasticsearch索引自动删除
简介 脚本分2部分,1部分查找符合条件的索引名,2脚本调用1脚本,进行删除操作 脚本 查找符合条件的,默认大于30天 # coding:utf-8 __author__ = 'Jipu FANG' f ...
随机推荐
- logback日志配置文件
application.properties application.properties logback-spring.xml <?xml version="1.0" en ...
- altera quartus 百度云分享 quartus prime 17.1 16.1 13.0
quartus prime 17.1 标准版 链接:https://pan.baidu.com/s/10QWejKdDobVxDSqnVPJ0xQ 提取码:hhvj 复制这段内容后打开百度网盘手机Ap ...
- 【python】详解numpy库与pandas库axis=0,axis= 1轴的用法
对数据进行操作时,经常需要在横轴方向或者数轴方向对数据进行操作,这时需要设定参数axis的值: axis = 0 代表对横轴操作,也就是第0轴: axis = 1 代表对纵轴操作,也就是第1轴: nu ...
- [系统资源攻略]CPU使用率和负载
我们在搞性能测试的时候,对后台服务器的CPU利用率监控是一个常用的手段.服务器的CPU利用率高,则表明服务器很繁忙.如果前台响应时间越来越大,而后台CPU利用率始终上不去,说明在某个地方有瓶颈了,系统 ...
- discourse论坛迁移
在源设备的操作备份数据文件tar -czvf discoursefile716.tar.gz /var/discourse然后把此discoursefile716.tar.gz文件传到需要迁移的设备上 ...
- 《零压力学Python》 之 第一章知识点归纳
第一章(初识Python)知识点归纳 Python是从ABC语言衍生而来的 ABC语言是Guido参与设计的一种教学语言,为非专业编程人员所开发的. Python是荷兰程序员 Guido Van Ro ...
- tensorflow的数据输入
tensorflow有两种数据输入方法,比较简单的一种是使用feed_dict,这种方法在画graph的时候使用placeholder来站位,在真正run的时候通过feed字典把真实的输入传进去.比较 ...
- Tkinter图形界面设计(GUI)
[因为这是我第一个接触的GUI图形界面python库,现在也不用了,所以大多数内容都来自之前花 钱买的一些快速入门的内容,可以当作简单的知识点查询使用] 在此声明:内容来自微信公众号GitChat,付 ...
- 【codeforces 767B】The Queue
[题目链接]:http://codeforces.com/contest/767/problem/B [题意] 排队去办护照; 给你n个人何时来的信息; 然后问你应该何时去才能在队伍中等待的时间最短; ...
- extjs 4 chart 时间轴格式的处理
var dayStore = Ext.create('Ext.data.JsonStore', { fields: [{ name: 'name', type: 'date', dateFormat: ...