.NET Core中文分词组件jieba.NET Core
.NET Core中文分词组件jieba.NET Core,由于实际的一些需求,需要做中文分词。
找到了一个 jieba.NET ,不过发现没有.NET Core 版本,看到有人在issue提.NET Core,便将jieba.NET 支持.NET Core。
jieba.NET Core版: https://github.com/linezero/jieba.NET
jieba分词特点
特点
- 支持三种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义。具体来说,分词过程不会借助于词频查找最大概率路径,亦不会使用HMM;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- 支持繁体分词
- 支持添加自定义词典和自定义词
jieba.NET Core 用法
下载代码使用VS 2017 打开,或者使用VS Code 打开项目。
选择jieba.NET 为起始项目,Program.cs 代码如下:
class Program
{
static void Main(string[] args)
{
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
var segmenter = new JiebaSegmenter();
var segments = segmenter.Cut("我来到北京清华大学", cutAll: true);
Console.WriteLine("【全模式】:{0}", string.Join("/ ", segments)); segments = segmenter.Cut("我来到北京清华大学"); // 默认为精确模式
Console.WriteLine("【精确模式】:{0}", string.Join("/ ", segments)); segments = segmenter.Cut("他来到了网易杭研大厦"); // 默认为精确模式,同时也使用HMM模型
Console.WriteLine("【新词识别】:{0}", string.Join("/ ", segments)); segments = segmenter.CutForSearch("小明硕士毕业于中国科学院计算所,后在日本京都大学深造"); // 搜索引擎模式
Console.WriteLine("【搜索引擎模式】:{0}", string.Join("/ ", segments)); segments = segmenter.Cut("结过婚的和尚未结过婚的");
Console.WriteLine("【歧义消除】:{0}", string.Join("/ ", segments));
Console.ReadKey();
}
}
运行程序结果如下:

JiebaSegmenter.Cut方法可通过cutAll来支持两种模式,精确模式和全模式。精确模式是最基础和自然的模式,试图将句子最精确地切开,适合文本分析;而全模式,把句子中所有的可以成词的词语都扫描出来, 速度更快,但是不能解决歧义,因为它不会扫描最大概率路径,也不会通过HMM去发现未登录词。
CutForSearch采用的是搜索引擎模式,在精确模式的基础上对长词再次切分,提高召回率,适合用于搜索引擎分词。
词性标注
词性标注采用和ictclas兼容的标记法,关于ictclas和jieba中使用的标记法列表,请参考:词性标记。
在TestDemo.cs 中PosCutDemo 方法为词性标注。
public void PosCutDemo()
{
var posSeg = new PosSegmenter();
var s = "一团硕大无朋的高能离子云,在遥远而神秘的太空中迅疾地飘移"; var tokens = posSeg.Cut(s);
Console.WriteLine(string.Join(" ", tokens.Select(token => string.Format("{0}/{1}", token.Word, token.Flag))));
}
调用结果如下:

关键词提取
现在来尝试提取其中的关键词。jieba.NET提供了TF-IDF和TextRank两种算法来提取关键词,TF-IDF对应的类是JiebaNet.Analyser.TfidfExtractor,TextRank的是JiebaNet.Analyser.TextRankExtractor。
public void ExtractTagsDemo()
{
var text =
"程序员(英文Programmer)是从事程序开发、维护的专业人员。一般将程序员分为程序设计人员和程序编码人员,但两者的界限并不非常清楚,特别是在中国。软件从业人员分为初级程序员、高级程序员、系统分析员和项目经理四大类。";
var extractor = new TfidfExtractor();
var keywords = extractor.ExtractTags(text);
foreach (var keyword in keywords)
{
Console.WriteLine(keyword);
}
} public void ExtractTagsDemo2()
{
var text = @"在数学和计算机科学/算学之中,算法/算则法(Algorithm)为一个计算的具体步骤,常用于计算、数据处理和自动推理。精确而言,算法是一个表示为有限长列表的有效方法。算法应包含清晰定义的指令用于计算函数。
算法中的指令描述的是一个计算,当其运行时能从一个初始状态和初始输入(可能为空)开始,经过一系列有限而清晰定义的状态最终产生输出并停止于一个终态。一个状态到另一个状态的转移不一定是确定的。随机化算法在内的一些算法,包含了一些随机输入。
形式化算法的概念部分源自尝试解决希尔伯特提出的判定问题,并在其后尝试定义有效计算性或者有效方法中成形。这些尝试包括库尔特·哥德尔、雅克·埃尔布朗和斯蒂芬·科尔·克莱尼分别于1930年、1934年和1935年提出的递归函数,阿隆佐·邱奇于1936年提出的λ演算,1936年Emil Leon Post的Formulation 1和艾伦·图灵1937年提出的图灵机。即使在当前,依然常有直觉想法难以定义为形式化算法的情况。"; var extractor = new TfidfExtractor();
var keywords = extractor.ExtractTags(text, , Constants.NounAndVerbPos);
foreach (var keyword in keywords)
{
Console.WriteLine(keyword);
}
}
ExtractTagsDemo 方法为提取所有关键词。

ExtractTagsDemo2 方法为提取前十个仅包含名词和动词的关键词

ExtractTagsWithWeight方法的返回结果中除了包含关键词,还包含了相应的权重值。
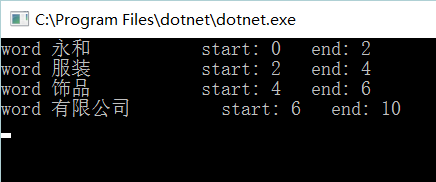
返回词语在原文的起止位置
public void TokenizeDemo()
{
var segmenter = new JiebaSegmenter();
var s = "永和服装饰品有限公司";
var tokens = segmenter.Tokenize(s);
foreach (var token in tokens)
{
Console.WriteLine("word {0,-12} start: {1,-3} end: {2,-3}", token.Word, token.StartIndex, token.EndIndex);
}
}
调用 TokenizeDemo 方法会返回对应位置
新词加入
代码加入
var segmenter = new JiebaSegmenter();
var segments = segmenter.Cut(@".NETCore2.0的发布时间,.NET Core 2.0预览版及.NET Standard 2.0 Preview大概在5月中旬或下旬发布。");
Console.WriteLine("【精确模式】:{0}", string.Join("/ ", segments));
segmenter.AddWord("发布时间");
segmenter.AddWord(".NETCore2.0");
segments = segmenter.Cut(@".NETCore2.0的发布时间,.NET Core 2.0预览版及.NET Standard 2.0 Preview大概在5月中旬或下旬发布。");
Console.WriteLine("【精确模式】:{0}", string.Join("/ ", segments));
调用 segmenter.AddWord添加新词,这里添加了发布时间及.NETCore2.0

可以看到新加入的词被识别出来。
词典加入
词典格式如下:词典格式与主词典格式相同,即一行包含:词、词频(可省略)、词性(可省略),用空格隔开。词频省略时,分词器将使用自动计算出的词频保证该词被分出。
创新办 i
云计算
凱特琳 nz
台中
机器学习
深度学习
linezero
然后使用segmenter.LoadUserDict() 方法,传入词典路径。
更多详细内容,可以查看代码及readme.md
参考文档:http://www.cnblogs.com/anderslly/p/jiebanet.html
如果你觉得本文对你有帮助,请点击“推荐”,谢谢。
.NET Core中文分词组件jieba.NET Core的更多相关文章
- Python中文分词组件 jieba
jieba "结巴"中文分词:做最好的Python中文分词组件 "Jieba" Feature 支持三种分词模式: 精确模式,试图将句子最精确地切开,适合文本分 ...
- python安装Jieba中文分词组件并测试
python安装Jieba中文分词组件 1.下载http://pypi.python.org/pypi/jieba/ 2.解压到解压到python目录下: 3.“win+R”进入cmd:依次输入如下代 ...
- 推荐十款java开源中文分词组件
1:Elasticsearch的开源中文分词器 IK Analysis(Star:2471) IK中文分词器在Elasticsearch上的使用.原生IK中文分词是从文件系统中读取词典,es-ik本身 ...
- 全文检索引擎Solr系列——整合中文分词组件mmseg4j
默认Solr提供的分词组件对中文的支持是不友好的,比如:“VIM比作是编辑器之神”这个句子在索引的的时候,选择FieldType为”text_general”作为分词依据时,分词效果是: 它把每一个词 ...
- 全文检索引擎Solr系列——整合中文分词组件IKAnalyzer
IK Analyzer是一款结合了词典和文法分析算法的中文分词组件,基于字符串匹配,支持用户词典扩展定义,支持细粒度和智能切分,比如: 张三说的确实在理 智能分词的结果是: 张三 | 说的 | 确实 ...
- 中文分词工具——jieba
汉字是智慧和想象力的宝库. --索尼公司创始人井深大 简介 在英语中,单词就是"词"的表达,一个句子是由空格来分隔的,而在汉语中,词以字为基本单位,但是一篇文章的表达是以词来划分的 ...
- 中文分词组件:thulac及jieba试用手记
一.THULAC THULAC由<清华大学自然语言处理与社会人文计算实验室>研制推出的一套中文词法分析工具包.官网地址:http://thulac.thunlp.org,该项目提供了多种语 ...
- nlp中文分词(jieba和pyltp)
分词是中文自然语言处理的基础.目前常用的分词算法有 1.张华平博士的NShort中文分词算法. 2.基于条件随机场(CRF)的中文分词算法. 这两种算法的代表工具包分别是jieba分词系统和哈工大的L ...
- python基础===jieba模块,Python 中文分词组件
api参考地址:https://github.com/fxsjy/jieba/blob/master/README.md 安装自行百度 基本用法: import jieba #全模式 word = j ...
随机推荐
- Jquery中的重置
提交表单是像下面这样的:代码 $('#myform').submit() $('#myform').submit() 所以,想当然的认为,重置表单,当然就是像下面这样子喽:代码 $('#myform ...
- Spring IOC以及三种注入方式
IOC是spring的最基础部分,也是核心模块,Spring的其他组件模块和应用开发都是以它为基础的.IOC把spring的面向接口编程和松耦合的思想体现的淋漓尽致. IOC概念 IOC(Invers ...
- mac环境,搭建python+selenium遇到的问题
安装过程: 1.下载安装pip,下载并且解压文件(默认路径即可),打开终端,执行sudo python setup.py install,系统自带python,也可以不安装 2.执行 sudo eas ...
- BOM基础(三)
在我之前关于DOM的文章里,其实已经有提到过事件的概念.在讲事件之前,首先要知道的就是javascript是由事件驱动的.什么叫事件驱动呢?打个比方,比如我们在页面中点击一个按钮,才会跳出一个窗口或者 ...
- BOM基础(一)
学完了js的基础语法和DOM之后,就要要看看javascript中最后一项BOM了.BOM,全称brower document model,翻译过来就是浏览器对象模型.DOM是文档对象模型,属于BOM ...
- c语言二叉树的递归建立
#include <stdio.h> #include <string.h> #include <stdlib.h> #include <malloc.h&g ...
- Robot Framework自动化测试环境部署
文档版本:v1.0 作者:令狐冲 如有问题请发邮件到:1146009864@qq.com 使用Robot Framework框架(以下简称RF)来做自动化测试. 模块化设计 1.所需环境一览表 软件 ...
- UI 自定义视图 ,视图管理器
一>自定义label - textField 视图 自定义视图:系统标准UI之外,自己组合而出的新的视图 iOS 提供了很多UI组件 ,借助它们,我们可以做各种程序 尽管如此,实际开发中,我们还 ...
- C++primer拾遗(第二章:变量和基本类型)
这是我对c++primer第二章的一个整理总结,算是比较适用于我自己吧,一小部分感觉不用提及的就省略了,只提了一下平时不注意,或者不好记住的内容. 排版太费劲了,直接放了图片格式.从自己的oneNot ...
- php文件基本操作与文件管理功能
文件的基本操作 先来看一下PHP文件基础操作,请看强大注释 <body> <?php var_dump(filetype("./img/11.png")); // ...