hive下UDF函数的使用
1、编写函数
[java] view plaincopyprint?
package com.example.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public final class LowerCase extends UDF {
public Text evaluate(final Text s) {
if (s == null) { return null; }
return new Text(s.toString().toLowerCase());
}
}
package com.example.hive.udf;
i
import org.apache.hadoop.hive.ql.exec.UDF;
i
import org.apache.hadoop.io.Text;
p
public final class LowerCase extends UDF {
public Text evaluate(final Text s) {
if (s == null) { return null; }
return new Text(s.toString().toLowerCase());
}
}
}
2、用eclipse下的fatjar插件进行打包
先下载net.sf.fjep.fatjar_0.0.31.jar插件包,cp至eclipse/plugins目录下,重启eclipse,右击项目选Export,选择用fatjar导出(可以删掉没用的包,不然导出的jar包很大)
3、将导出的hiveudf.jar复制到hdfs上
hadoop fs -copyFromLocal hiveudf.jar hiveudf.jar
4、进入hive,添加jar,
add jar hdfs://localhost:9000/user/root/hiveudf.jar
5、创建一个临时函数
create temporary function my_lower as 'com.example.hive.udf.LowerCase';
6、调用
select LowerCase(name) from teacher;
注:这种方法只能添加临时的函数,每次重新进入hive的时候都要再执行4-6,要使得这个函数永久生效,要将其注册到hive的函数列表
添加函数文件$HIVE_HOME/src/ql/src/java/org/apache/hadoop/hive/ql/udf/UDFLowerCase.java
修改$HIVE_HOME/src/ql/src/java/org/apache/hadoop/hive/ql/exec/FunctionRegistry.java文件
import org.apache.hadoop.hive.ql.udf.UDFLowerCase;
registerUDF(“LowerCase”, UDFLowerCase.class,false);
(上面这个方法未测试成功)
为了避免每次都有add jar 可以设置hive的'辅助jar路径'
在hive-env.sh中 export HIVE_AUX_JARS_PATH=/home/ckl/workspace/mudf/mudf_fat.jar;
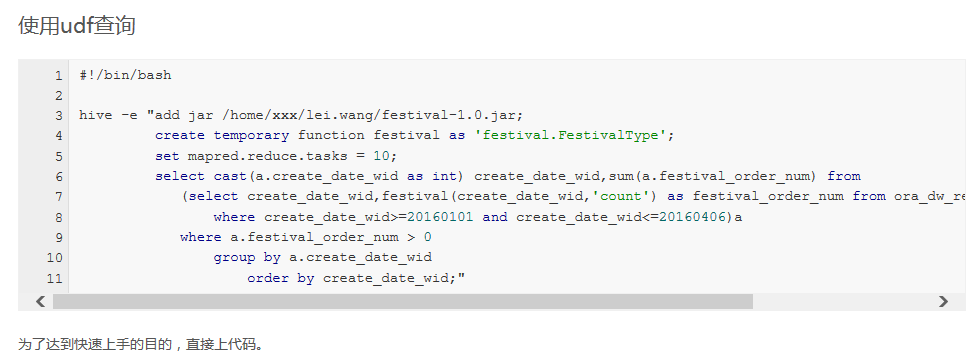
hive下UDF函数的使用的更多相关文章
- 如何编写自定义hive UDF函数
Hive可以允许用户编写自己定义的函数UDF,来在查询中使用.Hive中有3种UDF: UDF:操作单个数据行,产生单个数据行: UDAF:操作多个数据行,产生一个数据行. UDTF:操作一个数据行, ...
- hive UDF函数
虽然Hive提供了很多函数,但是有些还是难以满足我们的需求.因此Hive提供了自定义函数开发 自定义函数包括三种UDF.UADF.UDTF UDF(User-Defined-Function) ...
- hive 中简单的udf函数编写
.注册函数,使用using jar方式在hdfs上引用udf库. $hive.注销函数,只需要删除mysql的hive数据记录即可. delete from func_ru ; delete from ...
- Hadoop生态圈-Hive的自定义函数之UDF(User-Defined-Function)
Hadoop生态圈-Hive的自定义函数之UDF(User-Defined-Function) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hive的UDF(用户自定义函数)开发
当 Hive 提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function). 测试各种内置函数的快捷方法: 创建一个 dual 表 ...
- Hive扩展功能(三)--使用UDF函数将Hive中的数据插入MySQL中
软件环境: linux系统: CentOS6.7 Hadoop版本: 2.6.5 zookeeper版本: 3.4.8 主机配置: 一共m1, m2, m3这五部机, 每部主机的用户名都为centos ...
- Hive UDF函数构建
1. 概述 UDF函数其实就是一个简单的函数,执行过程就是在Hive转换成MapReduce程序后,执行java方法,类似于像MapReduce执行过程中加入一个插件,方便扩展.UDF只能实现一进一出 ...
- [转] Hive 内置函数
原文见:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF 1.内置运算符1.1关系运算符 运算符 类型 说明 A ...
- hive中UDF、UDAF和UDTF使用
Hive进行UDF开发十分简单,此处所说UDF为Temporary的function,所以需要hive版本在0.4.0以上才可以. 一.背景:Hive是基于Hadoop中的MapReduce,提供HQ ...
随机推荐
- java多线程(五)-访问共享资源以及加锁机制(synchronized,lock,voliate)
对于单线程的顺序编程而言,每次只做一件事情,其享有的资源不会产生什么冲突,但是对于多线程编程,这就是一个重要问题了,比如打印机的打印工作,如果两个线程都同时进行打印工作,那这就会产生混乱了.再比如说, ...
- IndentationError: unexpected indent
都知道python是对格式要求很严格的,写了一些python但是也没发现他严格在哪里,今天遇到了IndentationError: unexpected indent错误我才知道他是多么的严格. ...
- flex盒模型 详细解析
flex盒模型 详细解析 移动端页面布局,采用盒模型布局,效果很好 /* ============================================================ ...
- Vue自己写组件——Demo详细步骤
公司近期发力,同时开了四五个大项目,并且都是用Vue来做的,我很荣幸的被分到了写项目公用模块的组,所以需要将公用的部分提取成组件的形式,供几个项目共同使用,下面详细讲一下写Vue组件的具体步骤. 一. ...
- 用 Identity Server 4 (JWKS 端点和 RS256 算法) 来保护 Python web api
目前正在使用asp.net core 2.0 (主要是web api)做一个项目, 其中一部分功能需要使用js客户端调用python的pandas, 所以需要建立一个python 的 rest api ...
- PHP curl请求https遇到的坑
PHP里curl对https的证书配置默认是服务器端要求验证的,如果服务器端没有配置证书验证,则无法请求https路径.如果为了简便使用不需要配置https证书的话,配置curl时将以下两项设置为fa ...
- 配置不同环境下启用swagger,在生产环境关闭swagger
前言 Swagger使用起来简单方便,几乎所有的API接口文档都采用swagger了.使用示例:http://www.cnblogs.com/woshimrf/p/swagger.html, 现在开发 ...
- 带新手走进神秘的HTTP协议
在开发的时候经常需要访问网络,比如Android就有好多这方面的框架:Volley.OkHttp.Retrofit等,当你看这些框架源码时,可能会很好奇关于http的部分,它的首部字段是什么意思,ht ...
- C#学习笔记-工厂模式
题目:计算器 解析:工厂方法(Factory Method),定义一个用于创建对象的接口,让子类决定实例化哪一个类. 定义运算类: class Operation { ; ; public doubl ...
- [转]scp用法
从本地复制到远程 复制目录命令格式: scp -r local_folder remote_username@remote_ip:remote_folder 或者 scp -r local_folde ...