Netty ByteBuf源码分析
Netty的ByteBuf是JDK中ByteBuffer的升级版,提供了NIO buffer和byte数组的抽象视图。
ByteBuf的主要类集成关系:
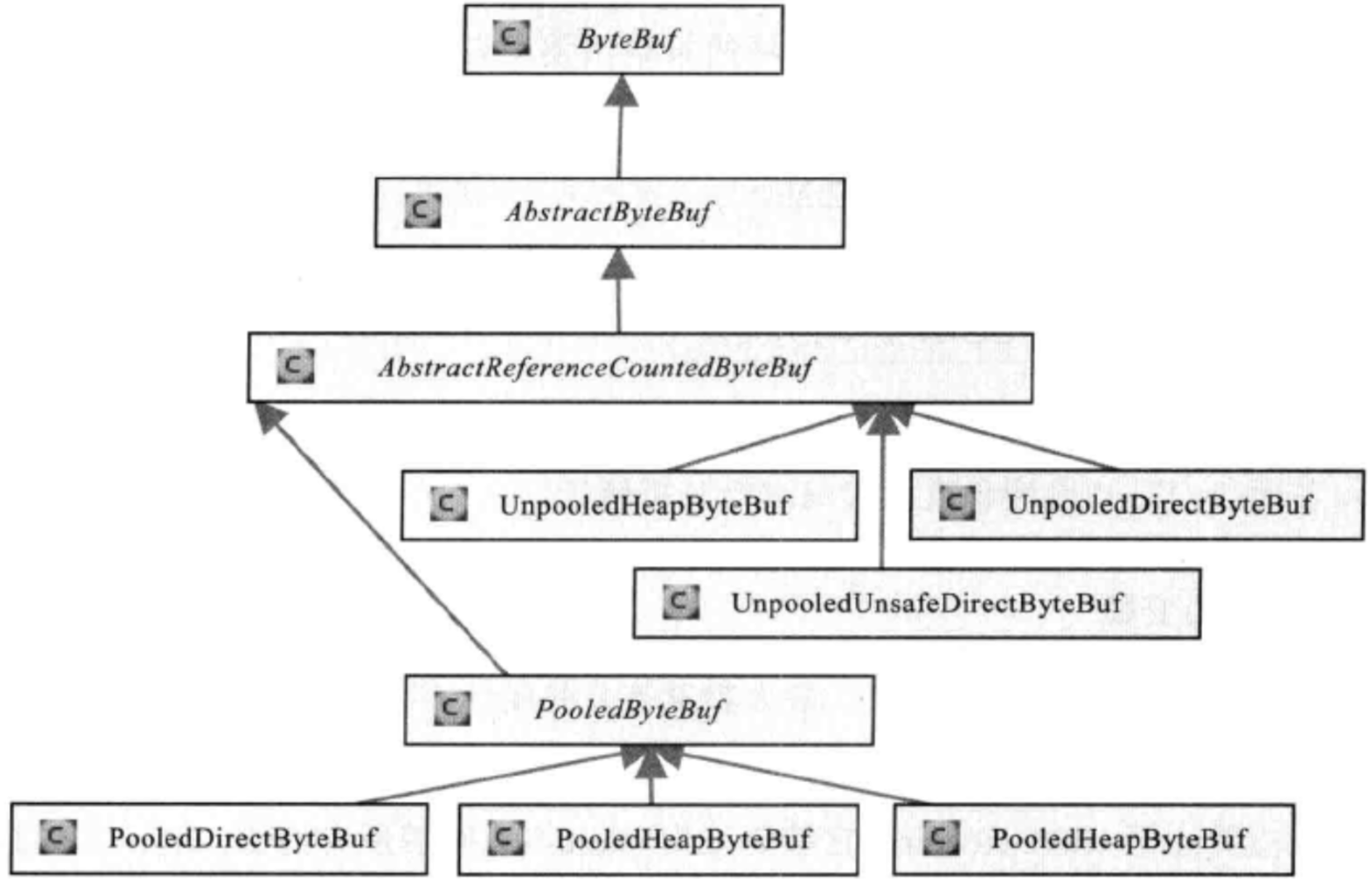
(图片来自Netty权威指南,图中有一个画错的地方是PooledByteBuf中的最后一个子类应该是PooledUnsafeDirectByteBuf)
从继承关系可以看出AbstractReferenceCountedByteBuf的子类分为两类:Pooled和Unpooled的ByteBuf。
Pooled ByteBuf是基于对象池的ByteBuf(会被缓存),Unpooled则是普通的ByteBuf对象。
无论是否基于内存池的ByteBuf,它的子类有分为DirectByteBuf和HeapByteBuf分别表示在堆外内存分配的缓冲区和在堆内存的缓冲区。
堆内存缓冲区的特点是分配和回收速度快,可以被JVM自动回收;缺点是如果进行Socket的IO读写,需要额外做一次内存复制。
堆外内存的缓冲区相对于堆内存的缓冲区,分配和回收的速度会慢一些,但是将它写入或从Socket Channel读取数据是,会少一次内存复制,速度比堆内存更快一些。
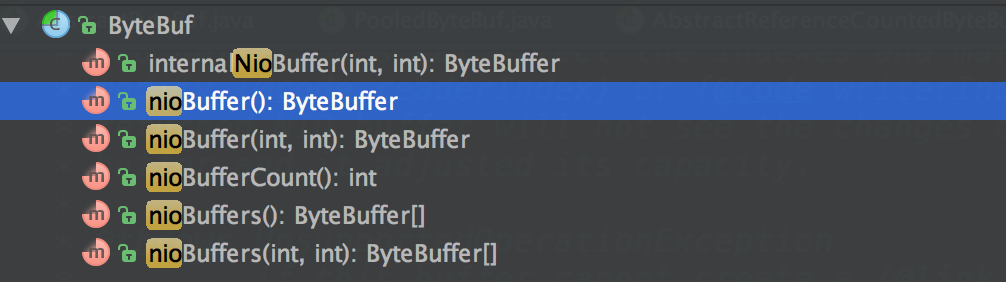
BufferBuf也提供了一类API来将自己转化成为ByteBuffer以便于在需要ByteBuffer的地方进行操作。
AbstractByteBuf
AbstractByteBuf定义了ByteBuf的基础属性和一些公用的方法。
主要成员变量有:
readerIndex
writerIndex
markedReaderIndex
markedWriterIndex
maxCapacity
可以看到ByteBuf中分别定义了读写游标,也就是说读游标和写游标是分离的,这相对于ByteBuffer只使用一个position,在读写操作时会便利很多。

一块缓冲区会被两个游标分隔为三块区域,分别是已经读取过的、可读的、剩余可写的。
在写入数据后可以直接开始读取,不需要flip操作。
另外AbstractByteBuf中的方法分为三类:
读取数据、写入数据、操作游标
读取操作分为readXXX和getXXX,以读取Long为例,
readLong()方法在当前readerIndex位置读取8个Byte并增加readerindex的值;
getLong(int index)则需要接收一个index参数,从index位置开始读取8个Byte,get操作不会改变readerIndex的值。
写入操作也有两类,分别是setXXX和writeXXX,
writeLong(long value)方法在当前writerIndex位置开始写入一个Long值并增加writerIndex的值;
setLong(int index, long value)方法则接收一个index参数作为写入的位置,写入操作不修改writerIndex的值。
索引操作就是通过setReaderIndex之类的方法改变readerIndex的值来重新读取数据,非常简单,不做说明。
AbstractReferenceCountedByteBuf
从类名上看,AbstractReferenceCountedByteBuf主要是实现了对引用的计数,类似于JVM内存回收的对象引用计数器,用于跟踪对象的分配和销毁。

只有一个成员变量:refCnt,看命名也知道是用于计数的,并且用AtomicIntegerFieldUpdater来实现线程安全的计数。 
retain API用于增加引用的计数。

release则用于减少计数值。

定义deallocate方法让子类去实现当引用计数为0时的操作(由子类实现具体的“回收”操作)。
UnpooledHeapByteBuffer
UnpooledHeapByteBuffer是不适用对象池,且直接在堆内存上分配的缓冲区。 
ByteBufAllocator alloc:创建了这个缓冲区的分配器
byte[] array:底层存储
ByteBuffer tmpNioBuf:Nio ByteBuffer对象,用于将自身转换成一个ByteBuffer对象
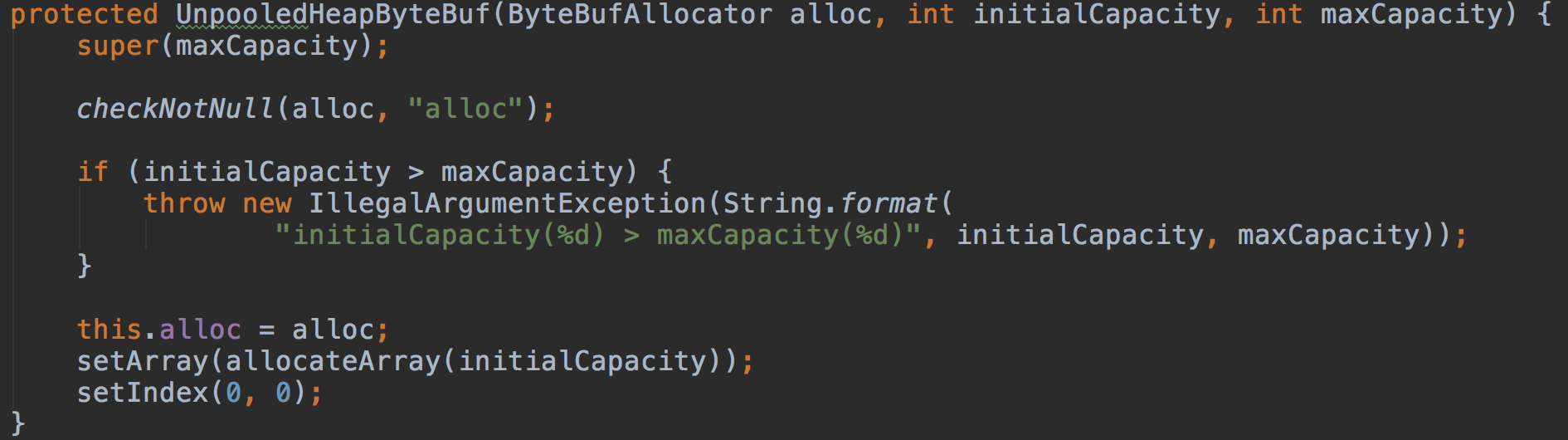
构造方法非常简单:
记录分配器alloc;
初始化数组;
将读写位置调整为0;
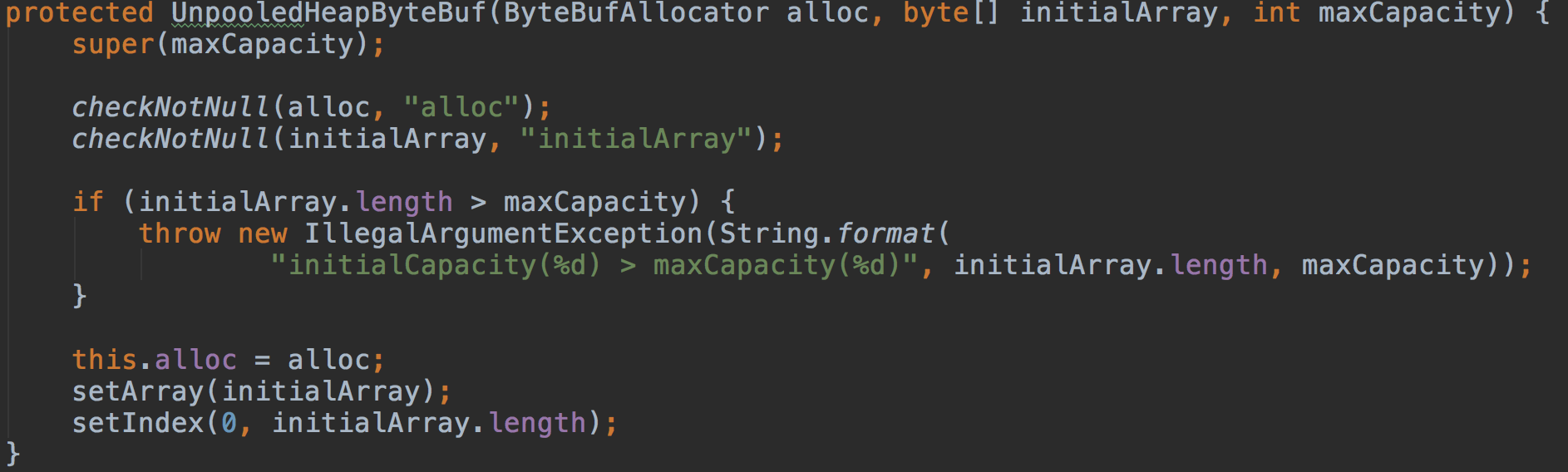
这个构造方法则是传入byte数组做初始化,writerIndex调整到数组后的第一个位置。
两个构造方法都有maxCapacity参数,且初始容量要么是initialCapacity要么是initalArray的长度,说明缓冲区的大小是可以调整的,最大不超过maxCapacity。
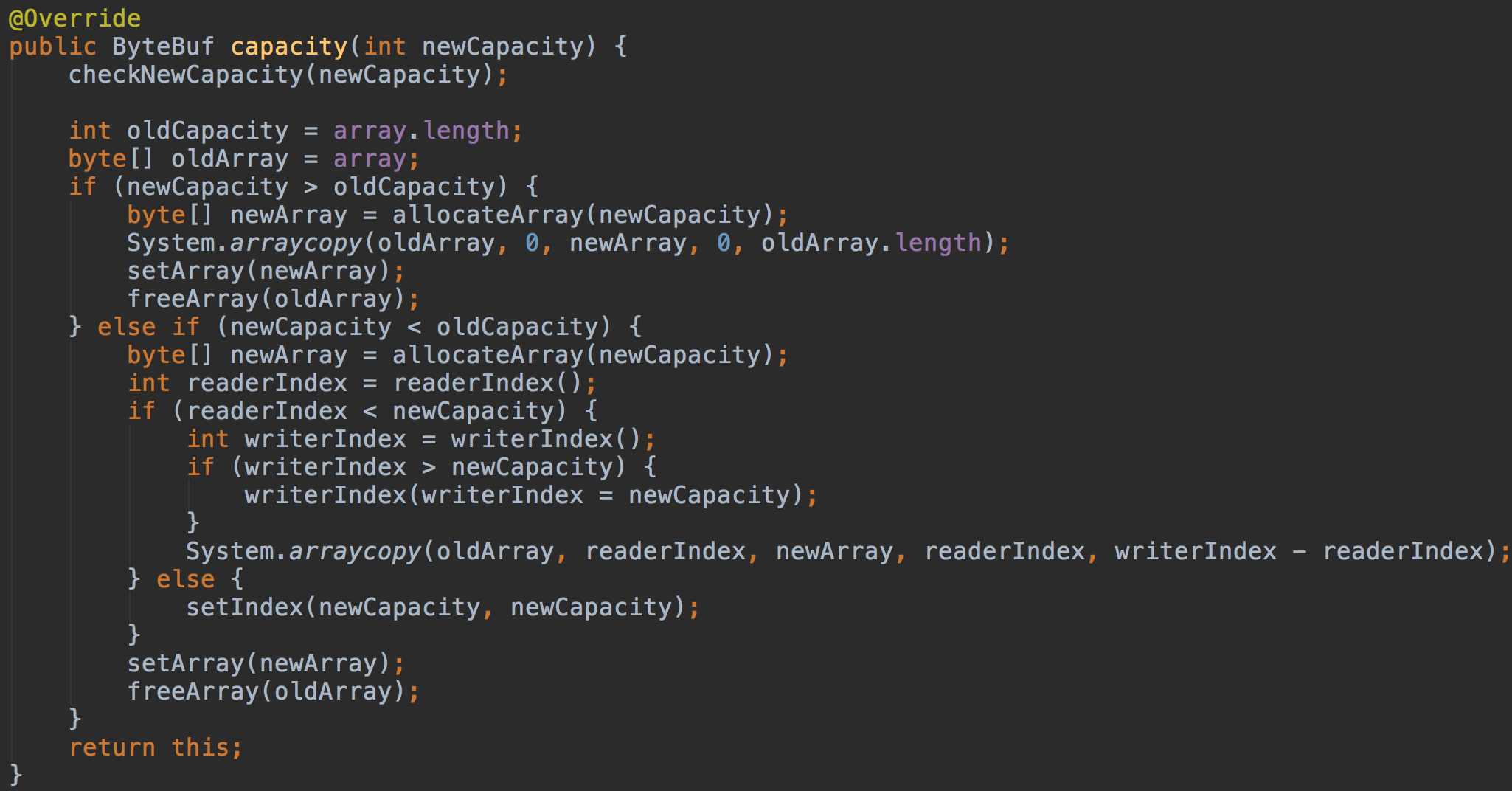
通过capacity来调整缓冲区的大小。如果newCapacity小于当前array的length,那么会有部分数据被丢弃。如果newCapacity超过array的length,那么新扩容的位置数据未空。
UnpooledDirectByteBuf

ByteBufAllocator alloc:使用的分配器
ByteBuffer buffer:内部用于存储数据的结构
ByteBuffer tmpNioBuf:临时的ByteBuffer,在将自己转换成ByteBuffer对象时会使用
int capacity:容量
doNotFree:标志ByteBuffer是否可以回收
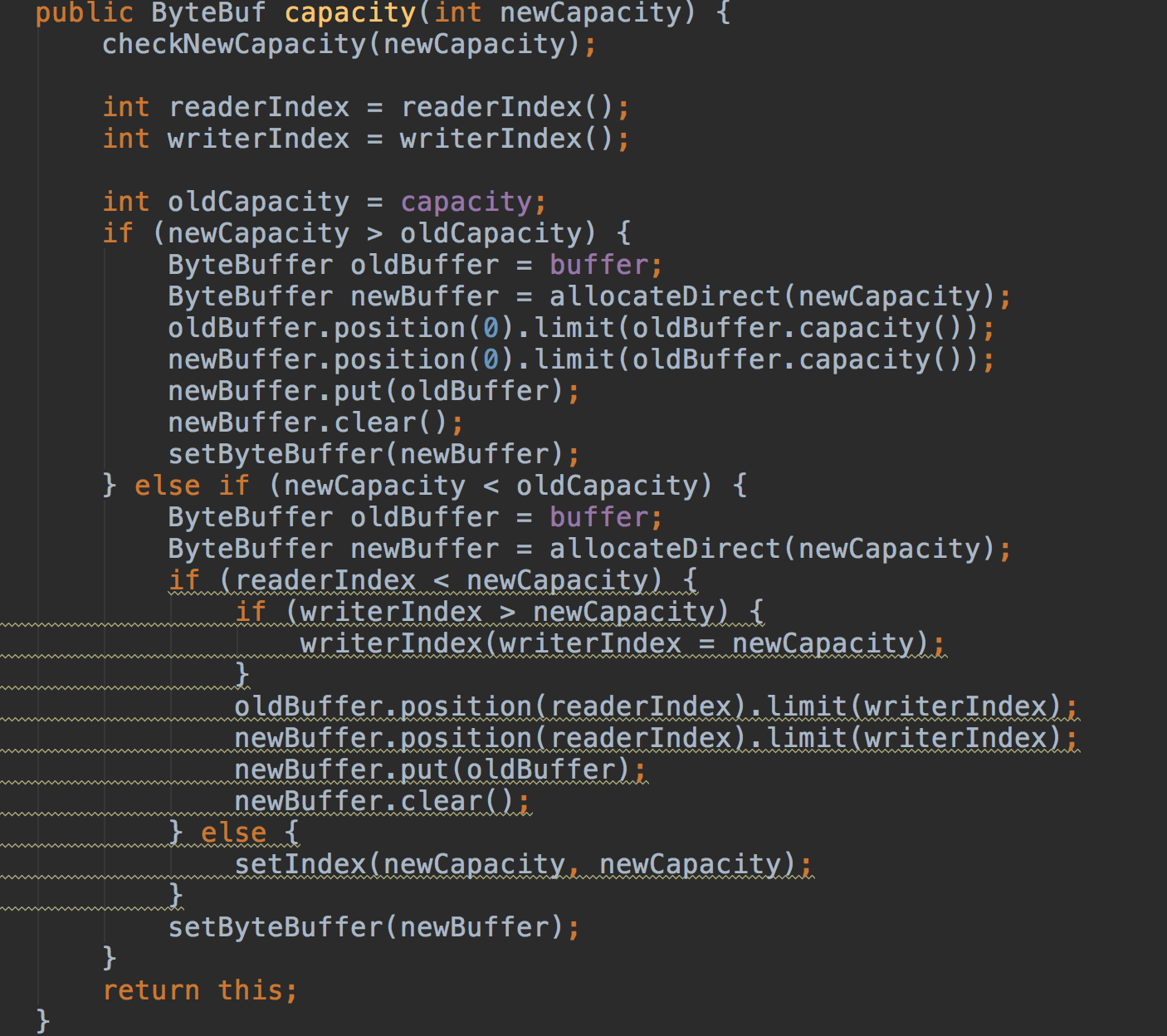
区别于UnpooledHeapByteBuf,UnpooledDirectByteBuf的扩容操作不在是申请数组进行数据拷贝,而是申请新的ByteBuffer之后进行收拷贝,而ByteBuffer一定是Direct的。
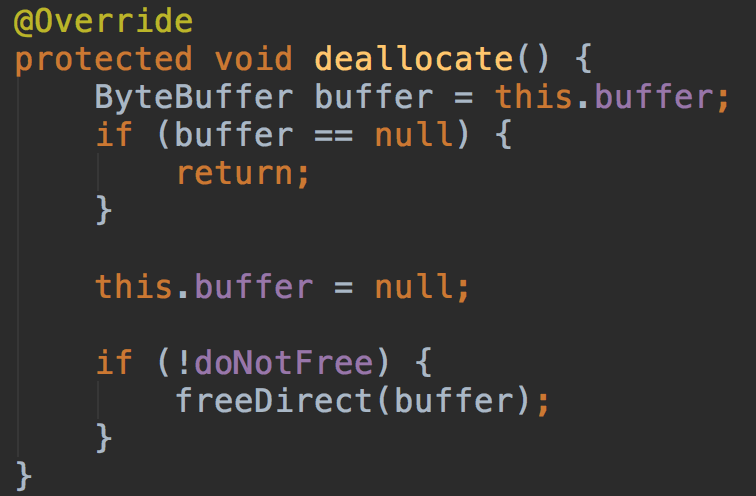
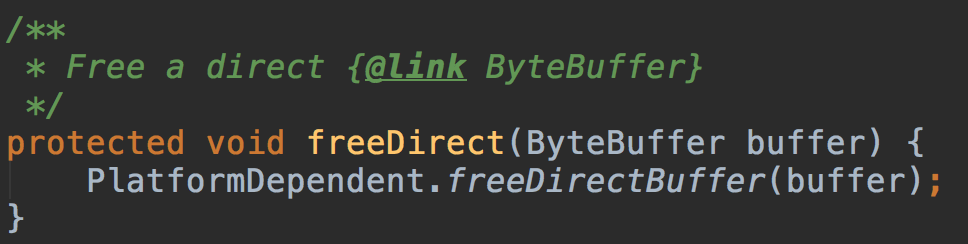
deallocate实现了底层存储ByteBuffer的回收操作,即在引用计数为0时将DirectByteBuffer回收掉(DirectByteBuffer的内存是由自己回收的,而不是JVM)。
UnpooledUnsafeDirectByteBuf
UnpooledUnsafeDirectByteBuf和UnpooledUnsafeDirectByteBuf的区别在于UnpooledUnsafeDirectByteBuf直接使用ByteBuffer来操作数据,而UnpooledUnsafeDirectByteBuf采用Unsafe来操作数据。
UnpooledUnsafeDirectByteBuf的_getLong实现:
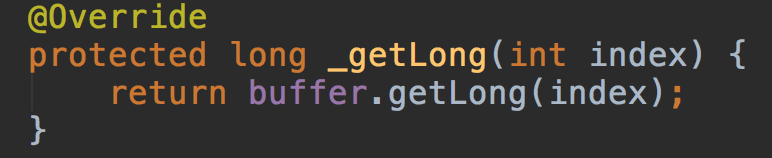
UnpooledUnsafeDirectByteBuf的_getLong实现:

AbstractReferenceCountedByteBuf子类的另一个分支是PooledByteBuf,即使用对象池,会被缓存的ByteBuffer。
PooledByteBuf有三个子类:
PooledHeapByteBuf
PooledDirectByteBuf
PooledUnsafeDirectByteBuf
他们分别和Unpooled的几个子类对应。
对于Pooled的实现,详见Netty对象池实现分析。
欢迎关注我的个人公众号,会写一些列关于消息中间件的文章,也欢迎交流任何技术问题,或者扯扯淡。

Netty ByteBuf源码分析的更多相关文章
- Netty学习篇⑥--ByteBuf源码分析
什么是ByteBuf? ByteBuf在Netty中充当着非常重要的角色:它是在数据传输中负责装载字节数据的一个容器;其内部结构和数组类似,初始化默认长度为256,默认最大长度为Integer.MAX ...
- netty : NioEventLoopGroup 源码分析
NioEventLoopGroup 源码分析 1. 在阅读源码时做了一定的注释,并且做了一些测试分析源码内的执行流程,由于博客篇幅有限.为了方便 IDE 查看.跟踪.调试 代码,所以在 github ...
- netty UnpooledHeapByteBuf 源码分析
UnpooledHeapByteBuf 是基于堆内存进行内存分配的字节缓冲区,没有基于对象池技术实现,这意味着每次I/O的读写都会创建一个新的UnpooledHeapByteBuf,频繁进行大块内存的 ...
- 【Netty】源码分析目录
前言 为方便系统的学习Netty,特整理文章目录如下. [Netty]第一个Netty应用 [Netty]Netty核心组件介绍 [Netty]Netty传输 [Netty]Netty之ByteBuf ...
- netty(六) buffer 源码分析
问题 : netty的 ByteBuff 和传统的ByteBuff的区别是什么? HeapByteBuf 和 DirectByteBuf 的区别 ? HeapByteBuf : 使用堆内存,缺点 ,s ...
- NIO-EPollSelectorIpml源码分析
目录 NIO-EPollSelectorIpml源码分析 目录 前言 初始化EPollSelectorProvider 创建EPollSelectorImpl EPollSelectorImpl结构 ...
- Netty源码分析第5章(ByteBuf)---->第1节: AbstractByteBuf
Netty源码分析第五章: ByteBuf 概述: 熟悉Nio的小伙伴应该对jdk底层byteBuffer不会陌生, 也就是字节缓冲区, 主要用于对网络底层io进行读写, 当channel中有数据时, ...
- Netty源码分析第5章(ByteBuf)---->第2节: ByteBuf的分类
Netty源码分析第五章: ByteBuf 第二节: ByteBuf的分类 上一小节简单介绍了AbstractByteBuf这个抽象类, 这一小节对其子类的分类做一个简单的介绍 ByteBuf根据不同 ...
- Netty源码分析第5章(ByteBuf)---->第3节: 缓冲区分配器
Netty源码分析第五章: ByteBuf 第三节: 缓冲区分配器 缓冲区分配器, 顾明思议就是分配缓冲区的工具, 在netty中, 缓冲区分配器的顶级抽象是接口ByteBufAllocator, 里 ...
随机推荐
- PHP中array_merge函数与array+array的区别
在PHP中可以使用array_merge函数和两个数组相加array+array的方式进行数组合并,但两者效果并不相同,下面为大家介绍两者具体的使用区别. 区别如下: 当下标为数值时,array_me ...
- python的列表(二)
1.遍历整个列表 #for 循环 # >>> name_list['faker', 'dopa', 'gogoing', 'uzi'] >>> for LOL_ ...
- iOS系统原生 二维码的生成、扫描和读取(高清、彩色)
由于近期工作中遇到了个需求:需要将一些固定的字段 在多个移动端进行相互传输,所以就想到了 二维码 这个神奇的东东! 现在的大街上.连个摊煎饼的大妈 都有自己的二维码来让大家进行扫码支付.可见现在的二维 ...
- MVC+Bootstrap+Drapper使用PagedList.Mvc支持多查询条件分页
前几天做一个小小小项目,使用了MVC+Bootstrap,以前做分页都是异步加载Mvc部分视图的方式,因为这个是小项目,就随便一点.一般的列表页面,少不了有查询条件,下面分享下Drapper+Page ...
- NFS文件共享
NFS文件共享 简介 NFS即网络文件系统(network file system),监听在TCP 2049端口. 服务器需要记住客户端的ip地址以及相应的端口信息,这些信息可以委托给RPC(remo ...
- setTimeout异步加载
两道经典的面试题,直接上代码 for(var i=0; i<3; i++){ setTimeout(function(){ i+=i; console.log(i); },1000) } var ...
- Java中设计模式之生产者消费者模式-4
引言 生产者-消费者(producer-consumer)问题,也称作有界缓冲区(bounded-buffer)问题,两个进程共享一个公共的固定大小的缓冲区.其中一个是生产者,用于将消息放入缓冲区:另 ...
- oracle 体系结构简介
1.1.SGA(system global area) SGA是oracle Instance的基本组成部分,在示例启动是分配.是一组包含一个oracle实例的数据和控制信息的共享内存结构.主要用于存 ...
- 关于dedecms的操作
系统基本参数的配置 如图 上面是设置系统的基本参数 操作是进入系统后台>点击系统>点击系统基本参数 然后右边就是系统参数等等基本参数了 记住修改后要点击确定哟 ☺ 数据库备份 如图: ...
- 懵懂oracle之存储过程2
上篇<懵懂oracle之存储过程>已经给大家介绍了很多关于开发存储过程相关的基础知识,笔者尽最大的努力总结了所有接触到的关于存储过程的知识,分享给大家和大家一起学习进步.本篇文章既是完成上 ...