webMagic解析淘宝cookie 提示Invalid cookie header
webMagic解析淘宝cookie 提示Invalid cookie header
在使用webMagic框架做爬虫爬取淘宝极又家页面时候一直提醒cookie设置不可用如下图

淘宝的验证特别严重,cookie没有正常设置进去后面会频繁弹出验证页面,这是我们不想看到的。为了解决这个问题,debug进入源码。
/**
* 摘选自org.apache.http.impl.cookie.RFC2965Spec
*/
@Override
public List<Cookie> parse(
final Header header,
final CookieOrigin origin) throws MalformedCookieException {
Args.notNull(header, "Header");
Args.notNull(origin, "Cookie origin");
if (!header.getName().equalsIgnoreCase(SM.SET_COOKIE2)) {
throw new MalformedCookieException("Unrecognized cookie header '"
+ header.toString() + "'");
}
final HeaderElement[] elems = header.getElements();
return createCookies(elems, adjustEffectiveHost(origin));
}
/**
* 摘选自org.apache.http.impl.cookie.RFC2965Spec
*
*/
public interface SM {
public static final String COOKIE = "Cookie";
public static final String COOKIE2 = "Cookie2";
public static final String SET_COOKIE = "Set-Cookie";
public static final String SET_COOKIE2 = "Set-Cookie2";
}
走到这边就大概明白了,这边cookie的解析规则用的RFC2965Spec,而淘宝的cookie不是遵循此规则。
期间去网上找了一下资料,大概了解了一下CookieSpec到底是个什么玩意。了解完了问题,接下来就是解决问题。
解决的过程中,使用了各种骚操作,没有任何卵用,就不赘述。最后还是debug进入webMagic的源码,查找原因,看到HttpUriRequestConverter类时发现了问题
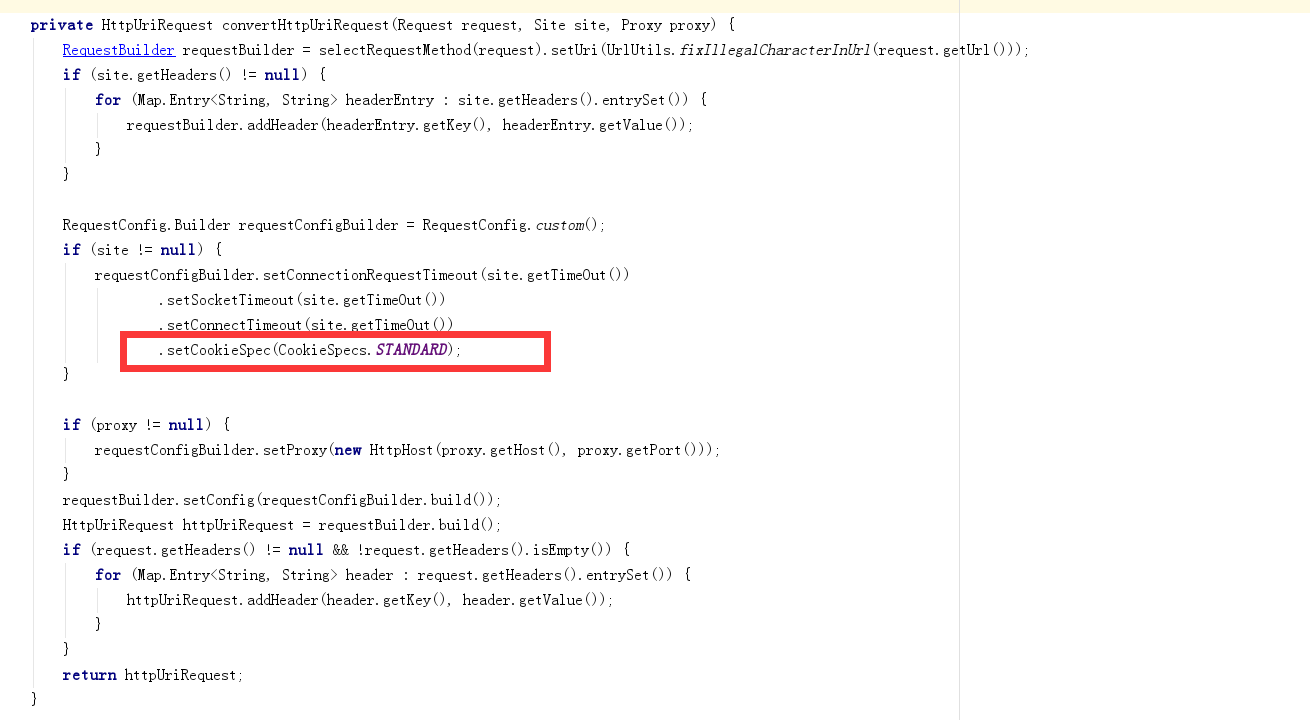
- -!这边写死了。使用标准模式解析其实和合理,然而并不是所有网站都是遵循标准来实现的。
if (site != null) {
requestConfigBuilder.setConnectionRequestTimeout(site.getTimeOut())
.setSocketTimeout(site.getTimeOut())
.setConnectTimeout(site.getTimeOut())
//爬虫Cookie不能识别
.setCookieSpec(CookieSpecs.BROWSER_COMPATIBILITY);
}
稍作修改,问题消失了。
然而这种将代码写死的做法并不推荐,应该做成可配置的,默认使用标准的CookieSpec才是比较合理。
webMagic解析淘宝cookie 提示Invalid cookie header的更多相关文章
- 模拟淘宝购物,运用cookie,记录登录账号信息,并且记住购物车内所选的商品
1.登录界面 <%@ page language="java" contentType="text/html; charset=UTF-8" pageEn ...
- 爬虫实战【8】Selenium解析淘宝宝贝-获取多个页面
作为全民购物网站的淘宝是在学习爬虫过程中不可避免要打交道的一个网站,而是淘宝上的数据真的很多,只要我们指定关键字,将会出现成千上万条数据. 今天我们来讲一下如何从淘宝上获取某一类宝贝的信息,比如今天我 ...
- solr入门之參考淘宝搜索提示功能优化拼音加汉字搜索功能
首先看一下从淘宝输入搜索keyword获取到的一些数据信息: 第一张:使用拼音的全程来查询 能够看到提示的是匹配的转换的拼音的方式,看最后一个提示项 这里另一个在指定分类文件夹下搜索的功能,难道后台还 ...
- 深入解析淘宝Diamond之客户端架构
转载:http://blog.csdn.net/u013970991/article/details/52088350 一.什么是Diamond diamond是淘宝内部使用的一个管理持久配置的系统, ...
- maven提示invalid LOC header (bad signature)的解决办法
今天执行mvn test的时候提示: 错误:读取 /home/subaochen/.m2/repository/org/slf4j/slf4j-api/1.6.1/slf4j-api-1.6.1.ja ...
- 爬虫实战【9】Selenium解析淘宝宝贝-获取宝贝信息并保存
通过昨天的分析,我们已经能到依次打开多个页面了,接下来就是获取每个页面上宝贝的信息了. 分析页面宝贝信息 [插入图片,宝贝信息各项内容] 从图片上看,每个宝贝有如下信息:price,title,url ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- 模拟淘宝登录和购物车功能:使用cookie记录登录名,下次登录时能够记得上次的登录名,使用cookie模拟购物车功能,使用session记住登录信息并验证是否登录,防止利用url打开网站,并实现退出登录功能
Login <%@ page language="java" contentType="text/html; charset=UTF-8" pageEnc ...
- scrapy框架携带cookie访问淘宝购物车
我们知道,有的网页必须要登录才能访问其内容.scrapy登录的实现一般就三种方式. 1.在第一次请求中直接携带用户名和密码. 2.必须要访问一次目标地址,服务器返回一些参数,例如验证码,一些特定的加密 ...
随机推荐
- SQL数据查询语句(一)
本文所用数据库为db_Test,数据表为Employee 一.SELECT语句基本结构 语句语法简单归纳为: SELECT select_list [INTO new_table_name] [FRO ...
- 三、第一个IDEA创建的MAVEN工程——JavaWeb点滴
一.Maven是什么? Maven是一个项目管理工具,它包含了一个项目对象模型 (Project Object Model),一组标准集合,一个项目生命周期(Project Lifecycle),一个 ...
- Lua中metatable和__index的联系
Lua中metatable和__index的联系 可以参考 http://blog.csdn.net/xenyinzen/article/details/3536708 来源 http://blog. ...
- 0_Simple__asyncAPI
关于CPU - GPU交互的简单接口函数. ▶ 源代码: // includes, system #include <stdio.h> // includes CUDA Runtime # ...
- 在ssm框架中前后台数据交互均使用json格式
前后台数据交互均使用json. 框架ssm(spring+springmvc+mybatis) @RequestBody注解实现接收http请求的json数据,将json数据转换为java对象,注解加 ...
- eclipse中删除多余的tomcat server
在eclipse菜单中选择Window--Show View--Server--Servers,打开这个服务窗口,将多余的服务删除即可. 如果每次启动中太卡没反应,那就是服务没选择好,或是端口冲突的原 ...
- 小米Java程序员第二轮面试10个问题,你是否会被刷掉?
近日,开发者头条上分享了一篇"小米java第二轮面经",有很多的java程序员表示非常有兴趣. 下面l就和各位分享小米java第二轮面经(华为java工程师笔试面试题可以看文章某尾 ...
- linux-echo
echo 更新时间: 2017-10-11-11:55:24 echo:打印输出内容 参数选择 -e 激活转义字符 命令:echo 123 ,此命令 就会输出123 命令: echo -e &q ...
- scrapy爬虫框架之理解篇(个人理解)
提问: 为什么使用scrapy框架来写爬虫 ? 在python爬虫中:requests + selenium 可以解决目前90%的爬虫需求,难道scrapy 是解决剩下的1 ...
- day2--SecureCRT的配置
生产中,我们是看不到虚拟机的工作界面,虚拟机的界面相当于机房显示屏的样子,实际上我们是在操作工具里面进行管理,这里使用SecureCRT远程连接虚拟机,SecureCRT的设置如下: 1.打开Secu ...