scrapy爬虫框架之理解篇(个人理解)
提问: 为什么使用scrapy框架来写爬虫 ?
在python爬虫中:requests + selenium 可以解决目前90%的爬虫需求,难道scrapy 是解决剩下的10%的吗?显然不是。scrapy框架是为了让我们的爬虫更强大、更高效。接下来我们一起学习一下它吧。
1.scrapy 的基础概念:
scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容。Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html

2. scrapy 的工作流程:
之前我们所写爬虫的流程:
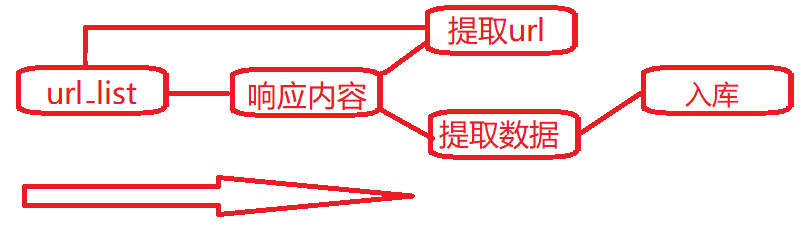
那么 scrapy是如何帮助我们抓取数据的呢?
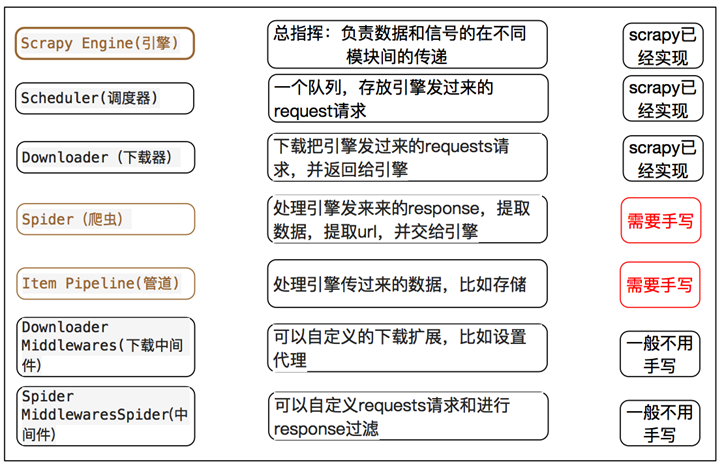
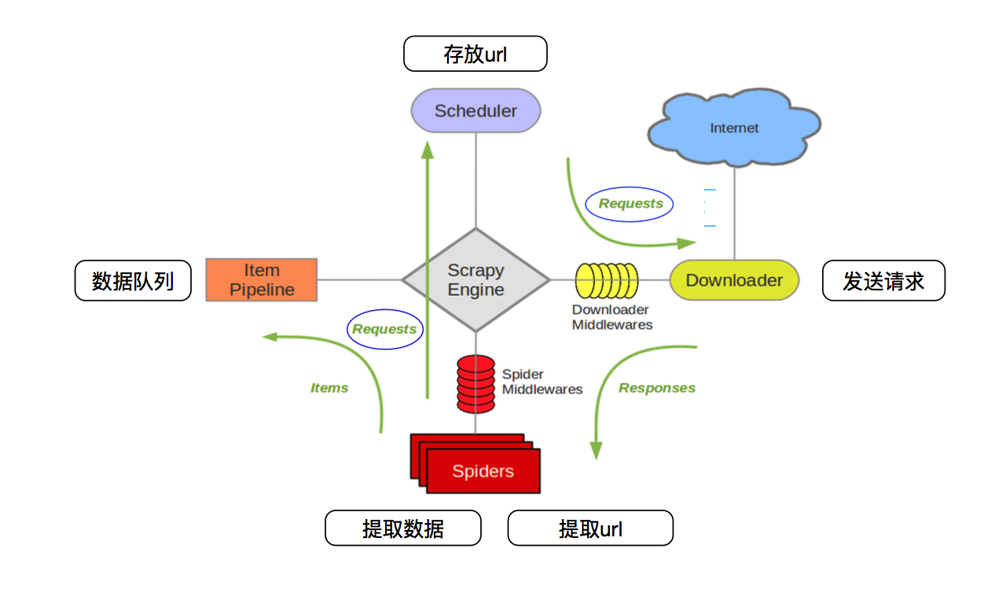
scrapy框架的工作流程:1.首先Spiders(爬虫)将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器)。
2.Scheduler(排序,入队)处理后,经ScrapyEngine,DownloaderMiddlewares(可选,主要有User_Agent, Proxy代理)交给Downloader。
3.Downloader向互联网发送请求,并接收下载响应(response)。将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders。
4.Spiders处理response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存(可以是本地,可以是数据库)。
提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
scrapy爬虫框架之理解篇(个人理解)的更多相关文章
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
随机推荐
- 【bzoj2761】[JLOI2011]不重复数字
给出N个数,要求把其中重复的去掉,只保留第一次出现的数. 例如,给出的数为1 2 18 3 3 19 2 3 6 5 4,其中2和3有重复,去除后的结果为1 2 18 3 19 6 5 4. Inpu ...
- Python调用C# Com dll组件实战
之前公司有套C# AES加解密方案,但是方案加密用的是Rijndael类,而非AES的四种模式(ECB.CBC.CFB.OFB,这四种用的是RijndaelManaged类),Python下Crypt ...
- Parallel.Invoke 并行的使用
Parallel类 在System.Threading.Tasks 命名空间下 下面有几个方法,这里讲一下Invoke的用法 下面我们定义几个方法方便测试 先自定义Response 防止并行的时候占 ...
- NOIP初赛 之 哈夫曼树
哈夫曼树 种根据我已刷的初赛题中基本每套的倒数第五或第六个不定项选择题就有一个关于哈夫曼树及其各种应用的题,占:0-1.5分:然而我针对这个类型的题也多次不会做,so,今晚好好研究下哈夫曼树: 概念: ...
- 正则表达式与grep和sed
正则表达式与grep和sed 目录 1.正则表达式 2.grep 3.sed grep和sed需要正则表达式,我们需要注意的正则表达式与通配符用法的区分. 1.正则表达式 REGEXP,正则表达式:由 ...
- 微信小程序- 生成二维码
wx.request({ // 获取token url: 'https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential', ...
- 简说chart2.4的应用,以及Uncaught ReferenceError : require is not defined的解决
51呢最近在学习chart.js,然后呢就照着中文的帮助文档来然后就一直出Uncaught ReferenceError : require is not defined的问题查了挺多才知道是帮助文档 ...
- Javascript常见浏览器兼容问题
常见浏览器原生javascript兼容性问题主要分为以下几类: 一.Dom 1.获取HTML元素,兼容所有浏览器方法:document.getElementById("id")以I ...
- JavaScript正则表达式实例汇总
本文会持续更新 -------------------------------------------------------------------------------------------- ...
- asp.net C# 实现微信接口权限开发类
当前微信接口类已实现以下接口,代码上如果不够简洁的,请自行处理. 1.获取access_token 2.获取用户基本信息 3.生成带参数二维码 4.新增永久素材 5.新增临时素材 6.发送微信模版 7 ...