最大信息系数(MIC)——Detecting Novel Associations in Large Data Sets
本文介绍了一种发现两个随机变量之间依赖关系强度的度量MIC(最大信息系数,类似于相关系数的作用)。MIC具有以下性质和优势:
MIC度量具有普适性。其不仅可以发现变量间的线性函数关系,还能发现非线性函数关系(指数的,周期的);不仅能发现函数关系,还能发现非函数关系(比如函数关系的叠加,或者有趣的图形模式)。
MIC度量具有均衡性。对于相同噪声水平的函数关系或者非函数关系,MIC度量具有近似的值。所以MIC度量不仅可以用来纵向比较同一相关关系的强度,还可以用来横向比较不同关系的强度。
MIC度量计算的方法。具有两个属性的数据点的集合分布在两维的空间中,使用m乘以n的网格划分数据空间,使落在第(x,y)格子中的数据点的频率作为P(x,y)的估计即 ,使落在第x行的数据点的频率作为P(x)的估计,同理获得P(y)的估计。然后计算随机变量X、Y的互信息。因为m乘以n的网格划分数据点的方式不止一种,所以我们要获得使互信息最大的网格划分。然后使用归一化因子,将互信息的值转化为(0,1)区间之内。最后,找到能使归一化互信息最大的网格分辨率,作为MIC的度量值。其中网格的分辨率限制为m x n < B,
,使落在第x行的数据点的频率作为P(x)的估计,同理获得P(y)的估计。然后计算随机变量X、Y的互信息。因为m乘以n的网格划分数据点的方式不止一种,所以我们要获得使互信息最大的网格划分。然后使用归一化因子,将互信息的值转化为(0,1)区间之内。最后,找到能使归一化互信息最大的网格分辨率,作为MIC的度量值。其中网格的分辨率限制为m x n < B,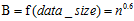 。将MIC的计算过程概括为公式为:
。将MIC的计算过程概括为公式为: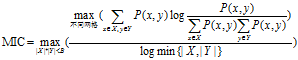
总之,MIC度量在本质上是基于互信息的。
本论文首先通过仿真实验来验证MIC的有效性。首先生成具有特定函数关系的二维数据点,然后在数据上添加不同程度的垂直的,均匀分布的随机噪声。使用这种方法生成了不同关系类型和不同噪声程度的数据集。然后在这组数据集上,综合比较了MIC和其它的一些方法,得出MIC度量更具有普适性和均衡性的结论。
作者在MIC的基础上又提出了几种度量。包括检测反单调性的MAS,检测非线性的MIC-ρ2等。
然后,作者在几组高维的公开数据集上测试了MIC度量,这些数据集已经被广泛的研究,已经被发现了很多有价值的著名的变量关系。这些数据集包括来自世界卫生组织的社会,经济,健康和政治指标数据;酵母菌基因表达数据;棒球联赛的统计数据。在来自WHO的数据中,发现了一些有趣的非线性关系(指数关系,抛物线,重叠函数关系等);在酵母菌基因表达数据中,使用MIC度量的变体:MAS度量,发现了几组有趣的周期模式;在人体肠道细菌丰度数据集中,发现了影响肠道细菌特异性的因素。
我在读完论文的正文部分之后,阅读了一部分论文的补充资料,里面有对论文更详细的解释。然后,我在网上找到了MIC度量的软件工具:R语言包minerva,并尝试了一下论文中的部分仿真实验。结果发现,随着B参数的增大,MIC度量总是趋近于1,这与补充资料中看到的资料一致。接下来我打算仔细阅读一下补充资料中关于算法实现的部分。
论文链接:http://science.sciencemag.org/content/334/6062/1518.full
软件下载:http://www.exploredata.net/Downloads/MINE-Application
最大信息系数(MIC)——Detecting Novel Associations in Large Data Sets的更多相关文章
- R与数据分析旧笔记(十一)数据挖掘初步
PART 1 PART 1 传统回归模型的困难 1.为什么一定是线性的?或某种非线性模型? 2.过分依赖于分析者的经验 3.对于非连续的离散数据难以处理 网格方法 <Science>上的文 ...
- Machine Learning - 第6周(Advice for Applying Machine Learning、Machine Learning System Design)
In Week 6, you will be learning about systematically improving your learning algorithm. The videos f ...
- AVIRIS反射率数据简介
Surface Reflectance 高光谱图像 ↑ AVIRIS高光谱成像光谱仪采集得到的原始图像为辐亮度图像,经过校正后的L1级产品为地表辐亮度信息.但是许多时候,我们更希望知道地面目标物的反射 ...
- Hadoop3.x 三大组件详解
Hadoop Hadoop适合海量数据分布式存储和分布式计算 运行用户使用简单的编程模型实现跨机器集群对海量数据进行分布式计算处理 1. 概述 1.1 简介 Hadoop核心组件 HDFS (分布式文 ...
- Hadoop
Hadoop应用场景 Hadoop是专为离线处理和大规模数据分析而设计的,它并不适合那种对几个记录随机读写的在线事务处理模式. 大数据存储:Hadoop最适合一次写入.多次读取的数据存储需求,如数据仓 ...
- Hadoop官方文档翻译——HDFS Architecture 2.7.3
HDFS Architecture HDFS Architecture(HDFS 架构) Introduction(简介) Assumptions and Goals(假设和目标) Hardware ...
- PRML读书会第七章 Sparse Kernel Machines(支持向量机, support vector machine ,KKT条件,RVM)
主讲人 网神 (新浪微博: @豆角茄子麻酱凉面) 网神(66707180) 18:59:22 大家好,今天一起交流下PRML第7章.第六章核函数里提到,有一类机器学习算法,不是对参数做点估计或求其分 ...
- 别老扯什么Hadoop了,你的数据根本不够大
本文原名“Don't use Hadoop when your data isn't that big ”,出自有着多年从业经验的数据科学家Chris Stucchio,纽约大学柯朗研究所博士后,搞过 ...
- Hbase原理、基本概念、基本架构
来源:http://blog.csdn.net/woshiwanxin102213/article/details/17584043 概述 HBase是一个构建在HDFS上的分布式列存储系统:HBas ...
随机推荐
- 基于FFMpeg的C#录屏全攻略
最近负责一个录屏的小项目,需要录制Windows窗口内容并压缩保存到指定文件夹,本想使用已有的录屏软件,但是本着学习的态度去探索了FFMpeg,本文主要介绍基于FFMpeg开源项目的C#录屏软件开发. ...
- linux 投影仪
注:文章转自http://goo.gl/aI9Ycd如果侵权,请原作者留言,立即删除 之前在 R219 做 C++ 演講的時候,發現 Ubuntu 沒有辦法使用 VGA 輸出,臨時改用 Windows ...
- Spark 基本概念
Application:用户编写的 Spark 应用程序,包含驱动程序(Driver),和分布在集群中多个节点上运行的 Executor 代码,在执行过程中由一个或多个作业组成 Driver(驱动程序 ...
- Hadoop(十四)MapReduce原理分析
前言 上一篇我们分析了一个MapReduce在执行中的一些细节问题,这一篇分享的是MapReduce并行处理的基本过程和原理. Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于had ...
- iOS开发从申请账号到上线APP Store步骤
1.developer.apple.com 申请开发者账号 2.根据API Cloud创建证书: http://docs.apicloud.com/Dev-Guide/iOS-License-Appl ...
- LeetCode 561. Array Partition I (数组分隔之一)
Given an array of 2n integers, your task is to group these integers into n pairs of integer, say (a1 ...
- LeetCode 73. Set Matrix Zeros(矩阵赋零)
Given a m x n matrix, if an element is 0, set its entire row and column to 0. Do it in place. click ...
- ES6中函数新增的方式方法
---恢复内容开始--- 绪 言 ES6 大家对JavaScript中的函数都不陌生.今天我就为大家带来ES6中关于函数的一些扩展方式和方法. 1.1函数形参的默认值 1.1.1基本用法 ES6 ...
- Android 6.0运行时权限
一.Runtime Permissions Android 6.0在手机安全方面做的一个处理就是增加了运行时权限(Runtime Permissions). 新的权限机制更好的保护了用户的隐私,Goo ...
- django 实现登录时候输入密码错误5次锁定用户十分钟
在学习django的时候,想要实现登录失败后,进行用户锁定,切记录锁定时间,在网上找了很多资料,但是都感觉不是那么靠谱, 于是乎,我开始了我的设计,其实我一开始想要借助redis呢,但是想要先开发一个 ...