ELK分布式日志系统的搭建
前言
ELK即分别为ElasticSearch、Logstash(收集、分析、过滤日志的工具)、Kibana(es的可视化工具),其主要工作原理就是由不同机器上的logstash收集日志后发送给es,然后由kibana展示
ElasticSeach
详情可参考ElasticSearch、ElasticSearch-head的安装和问题解决 一文
Logstash
安装
官网下载:https://www.elastic.co/cn/downloads/logstash
百度云下载:
链接:https://pan.baidu.com/s/1Ev1WZokXKFbmVLPTWD98kw
提取码:vxt9
linux:
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.2.3.tar.gz
tar -zxvf logstash-6.2.3.tar.gz
cd logstash-6.2.3
简易使用
./bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}' 其中 stdin{} 表示从标准输入输入信息; -e 表示从命令行指定配置;然后 codec=>rubydebug 表示把结果输出到控制台。
./bin/logstash -e 'input { stdin{} } output { stdout{} }' 标准的输入输出,logstash最基本的工作模式,你输入什么,logstash就输出什么
另外,由于Logstash占用内存较大,默认堆内存为1G,因此内存不足的情况下会很卡
Filebeat
轻量级的日志传输工具,适用于没有java环境的服务器上,收集日志后发送给logstash、elasticsearch,缓冲redis、kafka
安装
官网下载:https://www.elastic.co/cn/downloads/beats/filebeat
linux下载:
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.6.1-linux-x86_64.tar.gz
tar -zxvf filebeat-7.6.1-linux-x86_64
mv filebeat-7.6.1-linux-x86_64 filebeat-7.6.1
cd filebeat-7.6.1
修改filebeat.yml文件
filebeat.inputs: # Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations. - type: log # Change to true to enable this input configuration.
enabled: true # Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/*.log
#- c:\programdata\elasticsearch\logs\*
------------------------------------------------------------
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
# Protocol - either `http` (default) or `https`.
#protocol: "https"
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
#username: "elastic"
#password: "changeme"
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["192.168.184.131:5044"]
注意:logstash和elasticsearch只能设置一个,否则会报输出不唯一的错误,要先启动logstash再启动filebeat
logstash输出日志到es配置
新建文件vim logfile.conf
input {
file {
path => "/var/log/*.log" //表示扫描目录下的所有以.log结尾的文件并将扫描结果发送给es
type => "ws-log"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["192.168.184.131:9200"]
index => "system-ws-%{+YYYY.MM.dd}" //索引名为system-ws-%{+YYYY.MM.dd}
}
}
此时可以通过以下命令检测配置文件是否有误
../bin/logstash -f logfile.conf --config.test_and_exit(当前目录为logstash-6.2.3/config)
将logstash和filebeat都启动
../bin/logstash -f logfile.conf(当前目录为logstash-6.2.3/config)
./filebeat -e -c filebeat.yml -d "public" (当前目录为filebeat-7.6.1)
如果想要后台启动则可以使用
nohup ../bin/logstash -f logfile.conf & 启动日志存储在当前目录的nohup.log文件中
或
nohup ../bin/logstash -f logfile.conf >logstash.log & 指定日志存储文件和位置
或
使用脚本文件启动
vim startup.sh
#!/bin/bash
nohup ../bin/logstash -f logfile.conf &
编写完成以后修改文件的执行权限 chmod -R 775 startup.sh
使用./startup.sh执行脚本(在startup.sh文件的目录下)
filebeat同理
Kibana
安装
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.4-linux-x86_64.tar.gz (最好与elasticsearch的版本保持一致)
tar -zxvf kibana-6.2.4-linux-x86_64.tar.gz
mv kibana-6.2.4-linux-x86_64 kibana-6.2.4
cd kibana-6.2.4
修改kibana.yml
server.port: 5601 server.host: "192.168.184.131" elasticsearch.url: "http://192.168.184.131:9200" kibana.index: ".kibana"
启动kibana ./kibana(在kibana的bin目录下)
后台启动可参考Logstash启动方式
最后当配置无误,启动成功后,会有这样的效果
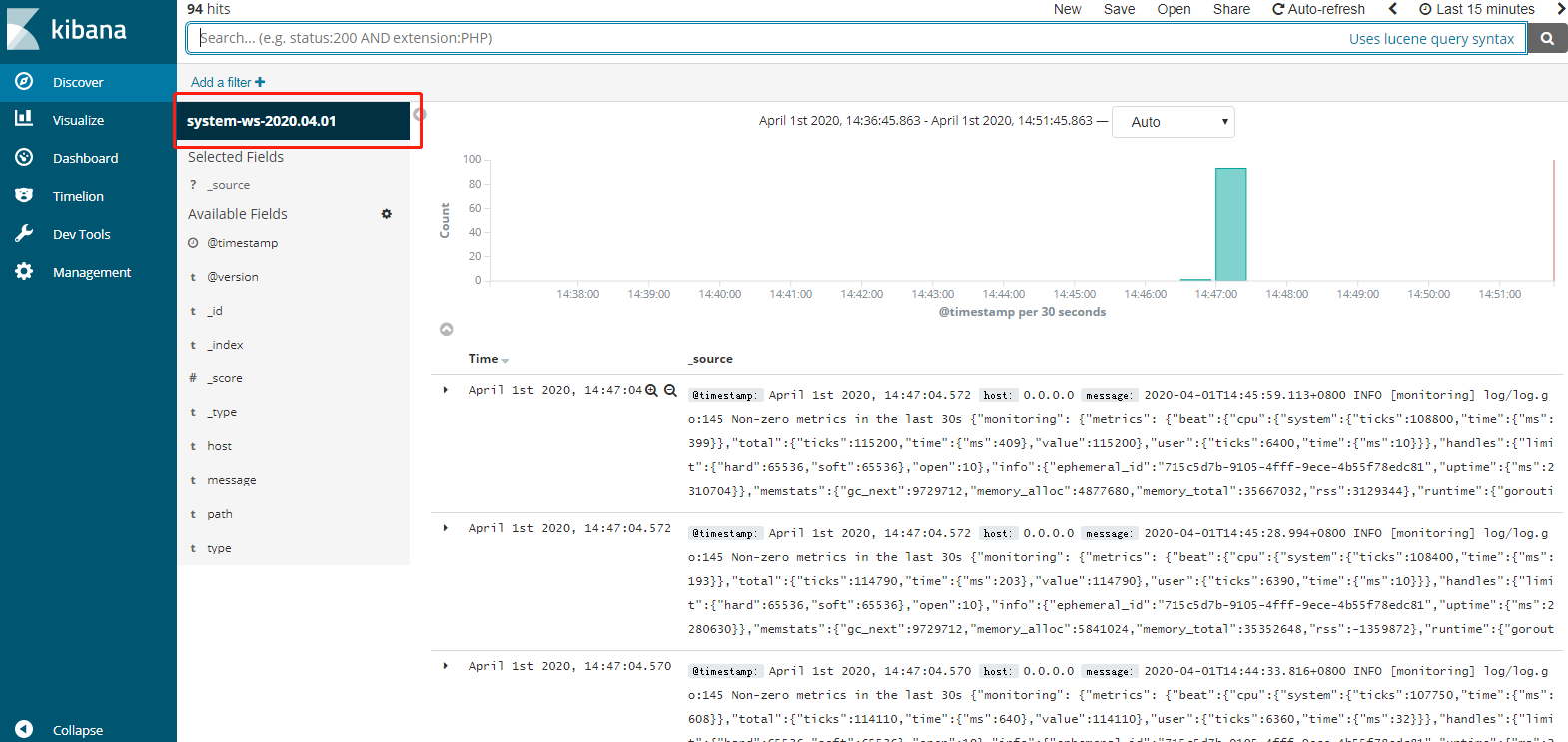
参考文章:
ELK分布式日志系统的搭建的更多相关文章
- ELK +Nlog 分布式日志系统的搭建 For Windows
前言 我们为啥需要全文搜索 首先,我们来列举一下关系型数据库中的几种模糊查询 MySql : 一般情况下LIKE 模糊查询 SELECT * FROM `LhzxUsers` WHERE UserN ...
- 使用Logstash工具导入sqlserver数据到elasticSearch及elk分布式日志中心
首先记下这个笔记,Logstash工具导入sqlserver数据到elasticSearch. 因为logstash使用java写的,我本地开发是win11,所以javade jdk必须要安装.具体安 ...
- .NET下日志系统的搭建——log4net+kafka+elk
.NET下日志系统的搭建--log4net+kafka+elk 前言 我们公司的程序日志之前都是采用log4net记录文件日志的方式(有关log4net的简单使用可以看我另一篇博客),但是随着 ...
- ELK分布式日志收集搭建和使用
大型系统分布式日志采集系统ELK全框架 SpringBootSecurity1.传统系统日志收集的问题2.Logstash操作工作原理3.分布式日志收集ELK原理4.Elasticsearch+Log ...
- 【7.1.1】ELK日志系统单体搭建
ELK是什么? 一般来说,为了提高服务可用性,服务器需要部署多个实例,每个实例都是负载均衡转发的后的,如果还用老办法登录服务器去tail -f xxx.log,有很大可能错误日志未出现在当前服务器中, ...
- .NetCore快速搭建ELK分布式日志中心
懒人必备:.NetCore快速搭建ELK分布式日志中心 该篇内容由个人博客点击跳转同步更新!转载请注明出处! 前言 ELK是什么 它是一个分布式日志解决方案,是Logstash.Elastaics ...
- C#采用rabbitMQ搭建分布式日志系统
网上对于java有很多开源的组件可以搭建分布式日志系统,我参考一些组件自己开发一套简单的分布式日志系 全部使用采用.NET进行开发,所用技术:MVC.EF.RabbitMq.MySql.Autofac ...
- Spring Cloud 5分钟搭建教程(附上一个分布式日志系统项目作为参考) - 推荐
http://blog.csdn.net/lc0817/article/details/53266212/ https://github.com/leoChaoGlut/log-sys 上面是我基于S ...
- ELK统一日志系统的应用
收集和分析日志是应用开发中至关重要的一环,互联网大规模.分布式的特性决定了日志的源头越来越分散, 产生的速度越来越快,传统的手段和工具显得日益力不从心.在规模化场景下,grep.awk 无法快速发挥作 ...
- Ansible实战:部署分布式日志系统
本节内容: 背景 分布式日志系统架构图 创建和使用roles JDK 7 role JDK 8 role Zookeeper role Kafka role Elasticsearch role My ...
随机推荐
- [WPF]鼠标移动到Button颜色改变效果设置
代码 <Style x:Key="Button_Menu" TargetType="{x:Type Button}"> <Setter Pro ...
- Matplotlib学习笔记2 - 循序渐进
Matplotlib学习笔记2 - 循序渐进 调整"线条" 在Matplotlib中,使用plot函数绘制的线条其实是一种特定的类,matplotlib.lines.Line2D. ...
- 在GCP的Kubernetes上安装dapr
1 简介 我们之前使用了dapr的本地托管模式,但在生产中我们一般使用Kubernetes托管,本文介绍如何在GKE(GCP Kubernetes)安装dapr. 相关文章: dapr本地托管的服务调 ...
- 12月15日内容总结——ORM执行原生SQL语句、双下划线数据查询、ORM外键字段的创建、外键字段的相关操作、ORM跨表查询、基于对象的跨表查询、基于双下划线的跨表查询、进阶查询操作
目录 一.ORM执行SQL语句 二.神奇的双下划线查询 三.ORM外键字段的创建 复习MySQL外键关系 外键字段的创建 1.创建基础表(书籍表.出版社表.作者表.作者详情) 2.确定外键关系 3.O ...
- elasticsearch之日期类型有点怪
一.Date类型简介 elasticsearch通过JSON格式来承载数据的,而JSON中是没有Date对应的数据类型的,但是elasticsearch可以通过以下三种方式处理JSON承载的Date数 ...
- JWT的原理及使用
目录 JWT的原理及使用 一.什么是JWT? 二.签发认证流程 三.使用方法 1.设置登录接口 2.设置过期事件 3.定制返回格式 4.配置认证类和权限类 5.写登录逻辑 5.配路由 JWT的原理及使 ...
- (原创)【B4A】一步一步入门04:编译模式、打包为APK、私钥签名
一.前言 上篇 (原创)[B4A]一步一步入门03:APP名称.图标等信息修改 中我们将APP做成了标准的样子. 本篇文章会讲解如何将程序打包成APK文件以分发,同时讲解如何制作私钥并签名APP,以用 ...
- FCoE简单介绍
目录 FCoE 使用前提 FCoE FCoE是一种融合网络技术,其目的是将FC帧封装到以太网帧中,实现以太网链路与光纤链路通信的功能. SAN一般指存储区域网络,FC SAN 有光纤组网,IP SAN ...
- 用ChatGPT,快速设计一个真实的账号系统
hi,我是熵减,见字如面. 用ChatGPT,可以尝试做很多的事情. 今天我们就来让ChatGPT做为架构师,来帮我们设计一个账号系统吧. 我的实验过程记录如下,与你分享. 用户故事 首先,我们从用户 ...
- CF1418D Trash Problem
题目传送门 思路 这题其实非常的简单,完全到不了 \(\mathcal *2100\). 发现这个题目描述有点诈骗,但是翻译的挺不错,实质上问题就是给你 \(n\) 个点,让你动态维护相邻两个点的差值 ...