OpenAI的子词标记化神器--tiktoken 以及 .NET 支持库SharpToken
OpenAI在其官方GitHub上公开了一个开源Python库:tiktoken,这个库主要是用力做字节编码对的。 字节编码对(Byte Pair Encoder,BPE)是一种子词处理的方法。其主要的目的是为了压缩文本数据。主要是将数据中最常连续出现的字节(bytes)替换成数据中没有出现的字节的方法。该算法首先由Philip Gage在1994年提出。
下图是tiktoken中公开的OpenAI所有大模型所使用的词表。
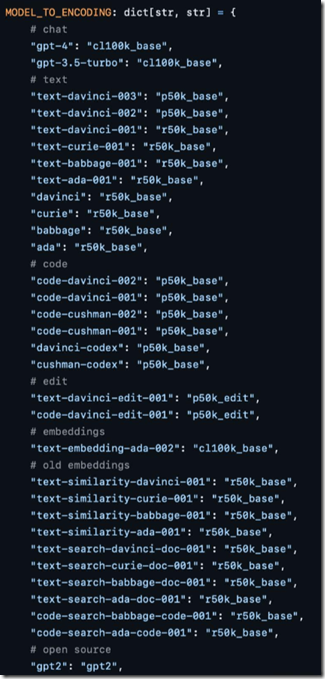
可以看到,ChatGPT和GPT-4所使用的是同一个,名为“cl100k_base”的词表。而text-davinci-003和text-davinci-002所使用的是名为”p50k_base“的词表。

OpenAI 官方开源了Python版本, .NET社区 移植了https://github.com/dmitry-brazhenko/SharpToken, 它提供了使用基于 GPT 的编码对令牌进行编码和解码的功能。此库是为 .NET 6 和 .NET Standard 2.1 构建的,使其与各种框架兼容。
下面是一个示例函数,用于对传递到 gpt-3.5-turbo-0381 或gpt-4-314 的消息的tokens进行计数。请注意,从消息中计算tokens的确切方式可能会因模型而异。将函数中的计数视为一个估计值:
public int CountMessagesTokens(string Model ,string Messages)
{
int tokensPerMessage;
if (Model.StartsWith("gpt-3.5-turbo"))
{
tokensPerMessage = 5;
}
else if (Model.StartsWith("gpt-4"))
{
tokensPerMessage = 4;
}
else
{
tokensPerMessage = 5;
}
var encoding = GptEncoding.GetEncoding("cl100k_base");
int totalTokens = 0;
foreach (var msg in Messages)
{
totalTokens += tokensPerMessage;
totalTokens += encoding.Encode(msg.Content).Count;
}
totalTokens += 3;
return totalTokens;
}
OpenAI的子词标记化神器--tiktoken 以及 .NET 支持库SharpToken的更多相关文章
- 斯坦福NLP课程 | 第12讲 - NLP子词模型
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- C语言标记化结构初始化语法
C语言标记化结构初始化语法 (designated initializer),而且还是一个ISO标准. #include <stdio.h> #include <stdlib.h&g ...
- 支付标记化(Tokenization)技术
道客巴巴->支付标记化(Tokenization)技术介绍 百度文库->中国银联支付标记化技术指引 NFC产业网->银联技术专家解答支付标记化Token技术 百度搜索->Tok ...
- windows 编程 —— 子窗口类别化(Window Subclassing)
对于子窗口控件,有时我们可能会想要获取子窗口的某些消息,比如在一个主窗口下有三个按钮,如果想要实现使用键盘Tab或者Shift-Tab键来使焦点切换于不同按钮之间,这时就可以使用子窗口类别化(Wind ...
- 标记化结构初始化语法 在结构体成员前加上小数点 如 “.open .write .close ”C99编译器 .
今天在看串口驱动(四)的时候 有这样一个结构体初始化 我很不理解 如下: static struct s3c24xx_uart_port s3c24xx_serial_ports[NR_PORTS] ...
- XAF应用开发教程(八) 汉化与多国语言支持
使用了XAF开发时,汉化是一个比较常的问题. 要实现汉化很简单: 1.在这里下载汉化资源文件.这里演示的版本是15.1.X的 2.文件下载后将:文件解压到目录 <你的项目>\BIN\ ...
- oracle 子查询因子化 浅谈(with的使用)
近来学习oracle,想要提高自己所写语句的效率和易读性,今天的笔记是关于子查询因子话这么一个东西 因子化的查询不一定可以提高效率,但是一定可以再提高程序的可读性方面成效显著 --with 语句 wi ...
- ckeditor 敏感词标记显示处理方法
直接在原型添加方法: (function () { /* * 取消所有高亮 */ CKEDITOR.editor.prototype.CancleSensitiveWordsHighlight = f ...
- NLP系列文章:子词嵌入(fastText)的理解!(附代码)
1. 什么是fastText 英语单词通常有其内部结构和形成⽅式.例如,我们可以从"dog""dogs"和"dogcatcher"的字⾯上推 ...
- 标准C的标记化结构初始化语法
1 struct file_operations { 2 struct module *owner; 3 loff_t (*llseek) (struct file * ...
随机推荐
- html页面间传递参数
$.query.get("id") jquery.params.js代码 /** * jQuery.query - Query String Modification and Cr ...
- matlab/simulink中的执行顺序问题
关于在simulink中开发一些硬件环境模型,有时候会碰到一些模块的执行先后顺序问题.比如说在一个通过UDP发送指令命令给客户端,要求发送的指令有先后的时间顺序,只有在前一条命令发送完以后,才可以进行 ...
- oneDNN
目录 oneDNN卷积思路 debug捆绑套路 jit_avx2_convolution_fwd_t::execute_forward( 整个文件oneDNN/src/cpu/x64/jit_avx2 ...
- python中and和or表达式的返回值
a or b 首先明确运算顺序, 从左至右 # 其次只要存在真就会返回真, and返回的是最后一个真, or返回的是第一个真 # 再次, a,b中存在假, 则and返回第一个假, or返回最后一个假 ...
- redis为什么是单核单线程
1)以前一直有个误区,以为:高性能服务器 一定是多线程来实现的 原因很简单因为误区二导致的:多线程 一定比 单线程 效率高,其实不然! 在说这个事前希望大家都能对 CPU . 内存 . 硬盘的速度都有 ...
- C/C++ 数据结构链式队列的定义与实现
#include <iostream> #include <Windows.h> using namespace std; typedef struct _QNode{ int ...
- 奇怪的 document.body.onscroll
打开开发者工具, 滚动下面示例页面 See the Pen document.body.onscroll vs document.body.addEventListener('scroll', ... ...
- Nginx + Keepalived 高可用集群部署
负载均衡技术对于一个网站尤其是大型网站的web服务器集群来说是至关重要的!做好负载均衡架构,可以实现故障转移和高可用环境,避免单点故障,保证网站健康持续运行.在使用 Nginx 做反向代理或者负载均衡 ...
- Java笔记第十一弹
TCP通信程序 TCP发送数据 //需要进行三次握手 import java.io.*; public class Main{ public static void main(String[] arg ...
- Android笔记--图像显示
imageView 具体实现: 注意:图片名称应当为小写的英文字母与数字的结合,当然,二者可以只存在其一 图片的放置的比例:(通过scaleType属性设置) ImageButton ImageBut ...