以寡治众各个击破,超大文件分片上传之构建基于Vue.js3.0+Ant-desgin+Tornado6纯异步IO高效写入服务
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_218
分治算法是一种很古老但很务实的方法。本意即使将一个较大的整体打碎分成小的局部,这样每个小的局部都不足以对抗大的整体。战国时期,秦国破坏合纵的连横即是一种分而治之的手段;十九世纪,比利时殖民者占领卢旺达, 将卢旺达的种族分为胡图族与图西族,以图进行分裂控制,莫不如是。
21世纪,人们往往会在Leetcode平台上刷分治算法题,但事实上,从工业角度上来看,算法如果不和实际业务场景相结合,算法就永远是虚无缥缈的存在,它只会出现在开发者的某一次不经意的面试中,而真实的算法,并不是虚空的,它应该能帮助我们解决实际问题,是的,它应该落地成为实体。
大文件分片上传就是这样一个契合分治算法的场景,现而今,视频文件的体积越来越大,高清视频体积大概2-4g不等,但4K视频的分辨率是标准高清的四倍,需要四倍的存储空间——只需两到三分钟的未压缩4K 电影,或者电影预告片的长度,就可以达到500GB。 8K视频文件更是大得难以想象,而现在12K正在出现,如此巨大的文件,该怎样设计一套合理的数据传输方案?这里我们以前后端分离项目为例,前端使用Vue.js3.0配合ui库Ant-desgin,后端采用并发异步框架Tornado实现大文件的分片无阻塞传输与异步IO写入服务。
前端分片
首先,安装Vue3.0以上版本:
npm install -g @vue/cli
安装异步请求库axios:
npm install axios --save
随后,安装Ant-desgin:
npm i --save ant-design-vue@next -S
Ant-desgin虽然因为曾经的圣诞节“彩蛋门”事件而声名狼藉,但客观地说,它依然是业界不可多得的优秀UI框架之一。
接着在项目程序入口文件引入使用:
import { createApp } from 'vue'
import App from './App.vue'
import { router } from './router/index'
import axios from 'axios'
import qs from 'qs'
import Antd from 'ant-design-vue';
import 'ant-design-vue/dist/antd.css';
const app = createApp(App)
app.config.globalProperties.axios = axios;
app.config.globalProperties.upload_dir = "https://localhost/static/";
app.config.globalProperties.weburl = "http://localhost:8000";
app.use(router);
app.use(Antd);
app.mount('#app')
随后,参照Ant-desgin官方文档:https://antdv.com/components/overview-cn 构建上传控件:
<a-upload
@change="fileupload"
:before-upload="beforeUpload"
>
<a-button>
<upload-outlined></upload-outlined>
上传文件
</a-button>
</a-upload>
注意这里需要将绑定的before-upload强制返回false,设置为手动上传:
beforeUpload:function(file){
return false;
}
接着声明分片方法:
fileupload:function(file){
var size = file.file.size;//总大小
var shardSize = 200 * 1024; //分片大小
this.shardCount = Math.ceil(size / shardSize); //总片数
console.log(this.shardCount);
for (var i = 0; i < this.shardCount; ++i) {
//计算每一片的起始与结束位置
var start = i * shardSize;
var end = Math.min(size, start + shardSize);
var tinyfile = file.file.slice(start, end);
let data = new FormData();
data.append('file', tinyfile);
data.append('count',i);
data.append('filename',file.file.name);
const axiosInstance = this.axios.create({withCredentials: false});
axiosInstance({
method: 'POST',
url:'http://localhost:8000/upload/', //上传地址
data:data
}).then(data =>{
this.finished += 1;
console.log(this.finished);
if(this.finished == this.shardCount){
this.mergeupload(file.file.name);
}
}).catch(function(err) {
//上传失败
});
}
}
具体分片逻辑是,大文件总体积按照单片体积的大小做除法并向上取整,获取到文件的分片个数,这里为了测试方便,将单片体积设置为200kb,可以随时做修改。
随后,分片过程中使用Math.min方法计算每一片的起始和结束位置,再通过slice方法进行切片操作,最后将分片的下标、文件名、以及分片本体异步发送到后台。
当所有的分片请求都发送完毕后,封装分片合并方法,请求后端发起合并分片操作:
mergeupload:function(filename){
this.myaxios(this.weburl+"/upload/","put",{"filename":filename}).then(data =>{
console.log(data);
});
}
至此,前端分片逻辑就完成了。
后端异步IO写入
为了避免同步写入引起的阻塞,安装aiofiles库:
pip3 install aiofiles
aiofiles用于处理asyncio应用程序中的本地磁盘文件,配合Tornado的异步非阻塞机制,可以有效的提升文件写入效率:
import aiofiles
# 分片上传
class SliceUploadHandler(BaseHandler):
async def post(self):
file = self.request.files["file"][0]
filename = self.get_argument("filename")
count = self.get_argument("count")
filename = '%s_%s' % (filename,count) # 构成该分片唯一标识符
contents = file['body'] #异步读取文件
async with aiofiles.open('./static/uploads/%s' % filename, "wb") as f:
await f.write(contents)
return {"filename": file.filename,"errcode":0}
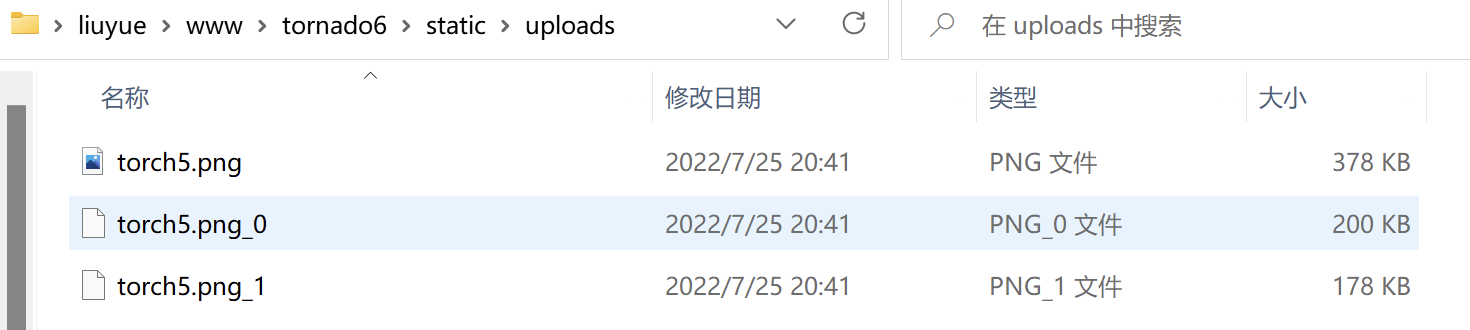
这里后端获取到分片实体、文件名、以及分片标识后,将分片文件以文件名_分片标识的格式异步写入到系统目录中,以一张378kb大小的png图片为例,分片文件应该顺序为200kb和178kb,如图所示:
当分片文件都写入成功后,触发分片合并接口:
import aiofiles
# 分片上传
class SliceUploadHandler(BaseHandler):
async def post(self):
file = self.request.files["file"][0]
filename = self.get_argument("filename")
count = self.get_argument("count")
filename = '%s_%s' % (filename,count) # 构成该分片唯一标识符
contents = file['body'] #异步读取文件
async with aiofiles.open('./static/uploads/%s' % filename, "wb") as f:
await f.write(contents)
return {"filename": file.filename,"errcode":0}
async def put(self):
filename = self.get_argument("filename")
chunk = 0
async with aiofiles.open('./static/uploads/%s' % filename,'ab') as target_file:
while True:
try:
source_file = open('./static/uploads/%s_%s' % (filename,chunk), 'rb')
await target_file.write(source_file.read())
source_file.close()
except Exception as e:
print(str(e))
break
chunk = chunk + 1
self.finish({"msg":"ok","errcode":0})
这里通过文件名进行寻址,随后遍历合并,注意句柄写入模式为增量字节码写入,否则会逐层将分片文件覆盖,同时也兼具了断点续写的功能。有些逻辑会将分片个数传入后端,让后端判断分片合并个数,其实并不需要,因为如果寻址失败,会自动抛出异常并且跳出循环,从而节约了一个参数的带宽占用。
轮询服务
在真实的超大文件传输场景中,由于网络或者其他因素,很可能导致分片任务中断,此时就需要通过降级快速响应,返回托底数据,避免用户的长时间等待,这里我们使用基于Tornado的Apscheduler库来调度分片任务:
pip install apscheduler
随后编写job.py轮询服务文件:
from datetime import datetime
from tornado.ioloop import IOLoop, PeriodicCallback
from tornado.web import RequestHandler, Application
from apscheduler.schedulers.tornado import TornadoScheduler
scheduler = None
job_ids = []
# 初始化
def init_scheduler():
global scheduler
scheduler = TornadoScheduler()
scheduler.start()
print('[Scheduler Init]APScheduler has been started')
# 要执行的定时任务在这里
def task1(options):
print('{} [APScheduler][Task]-{}'.format(datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f'), options))
class MainHandler(RequestHandler):
def get(self):
self.write('<a href="/scheduler?job_id=1&action=add">add job</a><br><a href="/scheduler?job_id=1&action=remove">remove job</a>')
class SchedulerHandler(RequestHandler):
def get(self):
global job_ids
job_id = self.get_query_argument('job_id', None)
action = self.get_query_argument('action', None)
if job_id:
# add
if 'add' == action:
if job_id not in job_ids:
job_ids.append(job_id)
scheduler.add_job(task1, 'interval', seconds=3, id=job_id, args=(job_id,))
self.write('[TASK ADDED] - {}'.format(job_id))
else:
self.write('[TASK EXISTS] - {}'.format(job_id))
# remove
elif 'remove' == action:
if job_id in job_ids:
scheduler.remove_job(job_id)
job_ids.remove(job_id)
self.write('[TASK REMOVED] - {}'.format(job_id))
else:
self.write('[TASK NOT FOUND] - {}'.format(job_id))
else:
self.write('[INVALID PARAMS] INVALID job_id or action')
if __name__ == "__main__":
routes = [
(r"/", MainHandler),
(r"/scheduler/?", SchedulerHandler),
]
init_scheduler()
app = Application(routes, debug=True)
app.listen(8888)
IOLoop.current().start()
每一次分片接口被调用后,就建立定时任务对分片文件进行监测,如果分片成功就删除分片文件,同时删除任务,否则就启用降级预案。
结语
分治法对超大文件进行分片切割,同时并发异步发送,可以提高传输效率,降低传输时间,和之前的一篇:聚是一团火散作满天星,前端Vue.js+elementUI结合后端FastAPI实现大文件分片上传,逻辑上有异曲同工之妙,但手法上却略有不同,确是颇有相互借镜之处,最后代码开源于Github:https://github.com/zcxey2911/Tornado6_Vuejs3_Edu,与众亲同飨。
原文转载自「刘悦的技术博客」 https://v3u.cn/a_id_218
以寡治众各个击破,超大文件分片上传之构建基于Vue.js3.0+Ant-desgin+Tornado6纯异步IO高效写入服务的更多相关文章
- b/s利用webuploader实现超大文件分片上传、断点续传
本人在2010年时使用swfupload为核心进行文件的批量上传的解决方案.见文章:WEB版一次选择多个文件进行批量上传(swfupload)的解决方案. 本人在2013年时使用plupload为核心 ...
- 前端利用webuploader实现超大文件分片上传、断点续传
本人在2010年时使用swfupload为核心进行文件的批量上传的解决方案.见文章:WEB版一次选择多个文件进行批量上传(swfupload)的解决方案. 本人在2013年时使用plupload为核心 ...
- 利用webuploader实现超大文件分片上传、断点续传
之前仿造uploadify写了一个HTML5版的文件上传插件,没看过的朋友可以点此先看一下~得到了不少朋友的好评,我自己也用在了项目中,不论是用户头像上传,还是各种媒体文件的上传,以及各种个性的业务需 ...
- java利用webuploader实现超大文件分片上传、断点续传
我们平时经常做的是上传文件,上传文件夹与上传文件类似,但也有一些不同之处,这次做了上传文件夹就记录下以备后用. 首先我们需要了解的是上传文件三要素: 1.表单提交方式:post (get方式提交有大小 ...
- php利用webuploader实现超大文件分片上传、断点续传
PHP用超级全局变量数组$_FILES来记录文件上传相关信息的. 1.file_uploads=on/off 是否允许通过http方式上传文件 2.max_execution_time=30 允许脚本 ...
- jsp利用webuploader实现超大文件分片上传、断点续传
1,项目调研 因为需要研究下断点上传的问题.找了很久终于找到一个比较好的项目. 在GoogleCode上面,代码弄下来超级不方便,还是配置hosts才好,把代码重新上传到了github上面. http ...
- asp.net利用webuploader实现超大文件分片上传、断点续传
ASP.NET上传文件用FileUpLoad就可以,但是对文件夹的操作却不能用FileUpLoad来实现. 下面这个示例便是使用ASP.NET来实现上传文件夹并对文件夹进行压缩以及解压. ASP.NE ...
- Webuploader 大文件分片上传
百度Webuploader 大文件分片上传(.net接收) 前阵子要做个大文件上传的功能,找来找去发现Webuploader还不错,关于她的介绍我就不再赘述. 动手前,在园子里找到了一篇不错的分片 ...
- Vue2.0结合webuploader实现文件分片上传
Vue项目中遇到了大文件分片上传的问题,之前用过webuploader,索性就把Vue2.0与webuploader结合起来使用,封装了一个vue的上传组件,使用起来也比较舒爽. 上传就上传吧,为什么 ...
随机推荐
- MySQL启动与多实例安装
启动方式及故障排查 一.几个问题 1.1 /etc/init.d/mysql 从哪来 cp /usr/local/mysql/support-files/mysql.server /etc/init. ...
- unity---判断物体碰撞的对象
脚本效果 trrn对象为地面,排除这个选项
- SeataAT模式原理
Seata架构 Seata将分布式事务理解为一个全局事务,它由若干个分支事务组成,一个分支事务就是一个满足ACID的本地事务. Seata架构中有三个角色: TC (Transaction Coord ...
- elementUI 函数自定义传参
<div v-for="(item,i) in ruleContent" :key="i"> <!-- eg:想通过循环将[i]传进函数rul ...
- Linux namespace技术应用实践--调用宿主机命令(tcpdump/ip/ps/top)检查docker容器网络、进程状态
背景 最近偶然听了几堂极客时间的云原生免费公开课程,首次接触到了Linux namespace技术,并了解到这正是现在风头正劲的容器技术基石,引起了自己探究一二的兴趣,结合课程+网络搜索+实践操作,也 ...
- jeecgboot-vue3笔记(三)弹窗的使用
需求描述 点击按钮,弹窗窗体(子组件),确定后在子组件中完成业务逻辑处理(例如添加记录),然后回调父组件刷新以显示最近记录. 实现步骤 子组件 子组件定义BasicModal <BasicMod ...
- 渗透测试之sql注入点查询
一切教程在于安全防范,不在于攻击别人黑别人系统为目的 寻找sql注入点方法: 拿到网页后进行查找注入点: 1.通过单引号 ' ; 在 url 后面输入单引号进行回车(如果报错可能存在sql注入为 ...
- 【lora无线数传通信模块】亿佰特E22串口模块用于物联网地震预警传感通信方案
物联网地震预警项目介绍: 地震,俗称地动.它像平常的刮风下雨一样,是一种常见的自然现象,是地壳运动的一种表现,即地球内部缓慢积累的能量突然释放而引起的地球表层的振动.据统计,5级以上地震就能够造成破坏 ...
- Jmeter(五十四) - 从入门到精通高级篇 - 如何在linux系统下运行jmeter脚本 - 上篇(详解教程)
1.简介 上一篇宏哥已经介绍了如何在Linux系统中安装Jmeter,想必各位小伙伴都已经在Linux服务器或者虚拟机上已经实践并且都已经成功安装好了,那么今天宏哥就来介绍一下如何在Linux系统下运 ...
- BUUCTF-乌镇峰会种图
乌镇峰会种图 16进制拖到底一看便知