2003031120—廖威—Python数据分析第七周作业—MySQL的安装以及使用
| 项目 | 内容 |
| 课程班级博客链接 | https://edu.cnblogs.com/campus/pexy/20sj |
| 这个作业要求链接 | https://edu.cnblogs.com/campus/pexy/20sj/homework/12597 |
| 博客名称 | 2003031120—廖威—Python数据分析第七周作业—MySQL的安装以及使用 |
| 要求 | 每道题要有题目,代码(使用插入代码,不会插入代码的自己查资料解决,不要直接截图代码!!),截图(只截运行结果) |
题目一:扩展阅读心得体会
1.扩展阅读:小白必看!超详细MySQL下载安装教程
2.扩展阅读:MySQL教程
3.扩展阅读:MySQL卸载
题目二:
1.安装好MySQL,连接上Navicat。
2.完成课本练习(代码4-1~3/4-9~31)。
from sqlalchemy import create_engine
#创建一个MYSQL连接器,用户名为root,密码为111
#地址为127.0.0.1,数据库名称为testdb,编码为UTF-8
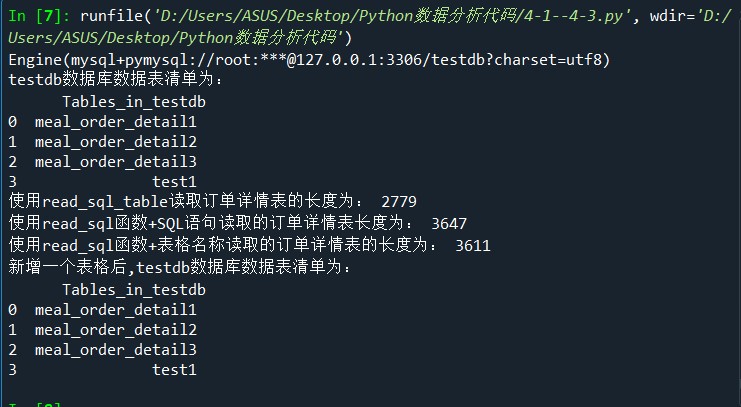
engine = create_engine('mysql+pymysql://root:111@127.0.0.1:3306/testdb?charset=utf8')
print(engine) import pandas as pd
#使用read_sql_query查看testdb中的数据表数目
formlist = pd.read_sql_query('show tables',con = engine)
print('testdb数据库数据表清单为:','\n',formlist) #使用read_sql_table读取订单详情表
detail1 = pd.read_sql_table('meal_order_detail1',con = engine)
print('使用read_sql_table读取订单详情表的长度为:',len(detail1)) #使用read_sql读取订单详情表
detail2 = pd.read_sql('select * from meal_order_detail2',con = engine)
print('使用read_sql函数+SQL语句读取的订单详情表长度为:',len(detail2))
detail3 = pd.read_sql('meal_order_detail3',con = engine)
print('使用read_sql函数+表格名称读取的订单详情表的长度为:',len(detail3)) #使用to_sql存储orderData
detail1.to_sql('test1',con = engine,index = False,if_exists = 'replace')
#使用read_sql读取test表
formlist1 = pd.read_sql_query('show tables',con = engine)
print('新增一个表格后,testdb数据库数据表清单为:','\n',formlist1)
#导入SQLAIchemy库的creat_engine函数
from sqlalchemy import create_engine
import pandas as pd
#创建一个MYSQL连接器,用户名为root,密码为111
#地址为127.0.0.1,数据库名称为testdb
engine = create_engine('mysql+pymysql://root:111@127.0.0.1:3306/testdb?charset=utf8')
#使用read_sql_table读取订单详情表
order1 = pd.read_sql_table('meal_order_detail1',con = engine)
print('订单详情表1的长度为:',len(order1))
order2 = pd.read_sql_table('meal_order_detail2',con = engine)
print('订单详情表2的长度为:',len(order2))
order3 = pd.read_sql_table('meal_order_detail3',con = engine)
print('订单详情表3的长度为:',len(order3)) #使用read_table读取订单信息表
orderInfo = pd.read_table('D:/Users/ASUS/Desktop/meal_order_info.csv',sep = ',',encoding = 'gbk')
print('订单信息表长度为:',len(orderInfo)) #读取users.xlsx文件
userInfo = pd.read_excel('D:/Users/ASUS/Desktop/users.xlsx')
print('客户信息表长度为:',len(userInfo)) from sqlalchemy import create_engine
import pandas as pd
engine = create_engine('mysql+pymysql://root:111@127.0.0.1:3306/testdb?charset=utf8')#创建数据库连接
detail= pd.read_sql_table('meal_order_detail1',con = engine)
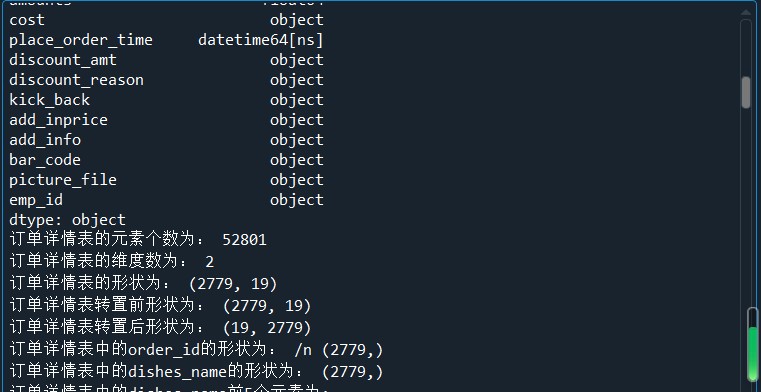
print('订单详情表的索引为:',detail.index) print('订单详情表的所有值为:','\n',detail.values) print('订单详情表的列名为:','\n',detail.columns) print('订单详情表的数据类型为:','\n',detail.dtypes) #查看DataFrame的元素个数
print('订单详情表的元素个数为:',detail.size)
print('订单详情表的维度数为:',detail.ndim) #查看DataFrame的维度数
print('订单详情表的形状为:',detail.shape) #查看Dataframe的形状 print('订单详情表转置前形状为:',detail.shape)
print('订单详情表转置后形状为:',detail.T.shape) #使用字典访问的方式取出orderInfo中的某一列
order_id = detail['order_id']
print('订单详情表中的order_id的形状为:','/n',order_id.shape) #使用访问属性的方式取出orderInfo中的菜品名称列
dishes_name = detail.dishes_name
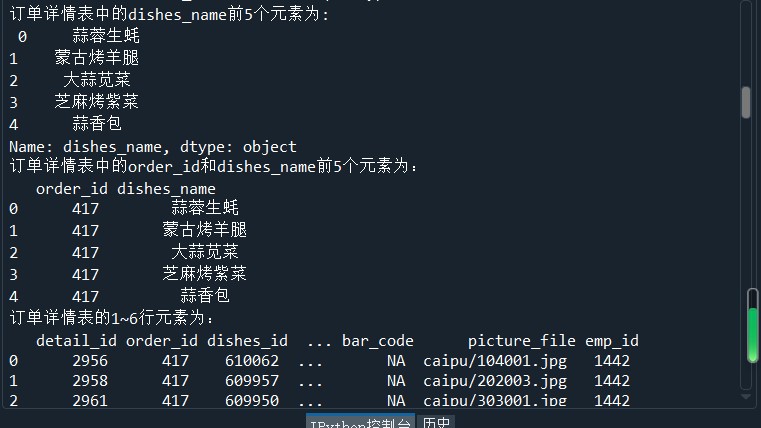
print('订单详情表中的dishes_name的形状为:',dishes_name.shape) dishes_name5 = detail['dishes_name'][:5]
print('订单详情表中的dishes_name前5个元素为:','\n',dishes_name5) orderDish = detail[['order_id','dishes_name']][:5]
print('订单详情表中的order_id和dishes_name前5个元素为:','\n',orderDish) order5 = detail[:][:6]
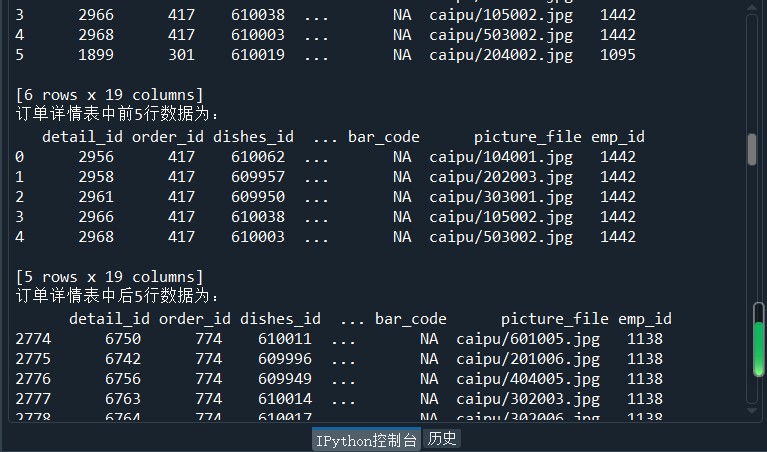
print('订单详情表的1~6行元素为:','\n',order5) print('订单详情表中前5行数据为:','\n',detail.head())
print('订单详情表中后5行数据为:','\n',detail.tail()) dishes_namel = detail.loc[:,'dishes_name']
print('使用loc提取dishes_name列的size为:',dishes_namel.size)
dishes_name2 = detail.iloc[:,3]
print('使用iloc提取第3列的size为:',dishes_name2.size) orderDish1 = detail.loc[:,['order_id','dishes_name']]
print('使用loc提取order_id和dishes_name列的size为:',orderDish1.size)
orderDish2 = detail.iloc[:,[1,3]]
print('使用iloc提取第1和第3列的size为:',orderDish2.size) print('列名为order_id和dishes_name的行名为3的数据为:\n',detail.loc[3,['order_id','dishes_name']])
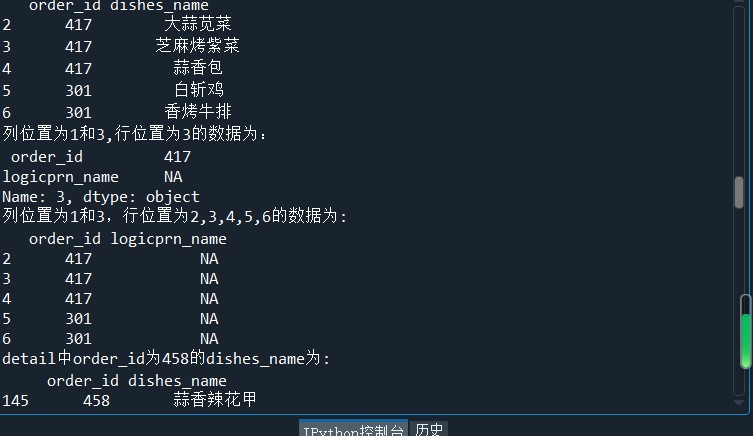
print('列名为order_id和dishes_name行名为2,3,4,5,6的数据为:\n',detail.loc[2:6,['order_id','dishes_name']])
print('列位置为1和3,行位置为3的数据为:\n',detail.iloc[3,[1,3]])
print('列位置为1和3,行位置为2,3,4,5,6的数据为:\n',detail.iloc[2:7,[1,3]]) #loc内部传入表达式
print('detail中order_id为458的dishes_name为:\n',detail.loc[detail['order_id']=='458',['order_id','dishes_name']])
#print('detail中order_id为458的第1、5列数据为:\n',detail.iloc[detail['order_id']=='458',[1,5]])#返回的为一个布尔值Series,而iloc可以接收的数据类型并不包括Series print('detail中order_id为458的第1、5列数据位:\n',detail.iloc[(detail['order_id']=='458').values,[1,5]]) print('列名为dishes_name行名为2,3,4,5,6的数据为:\n',detail.loc[2:6,'dishes_name'])
print('列位置为5,行位置为2~6的数据为:\n',detail.iloc[2:6,5])
#print('列位置为5,行位置为2~6的数据为:', '\n',detail.ix[2:6,5])在pandas的1.0.0版本开始,移除了Series.ix and DataFrame.ix 方法。使用DataFrame的loc方法或者iloc方法进行替换吧。 #将order_id为458的变换45800
detail.loc[detail['order_id']=='458','order_id'] = '45800'
print('更改后detail中order_id为458的order_id为:\n',detail.loc[detail['order_id']=='458','order_id'])
print('更改后detail中order_id为45800的order_id为:\n',detail.loc[detail['order_id']=='45800','order_id']) detail['payment'] = detail['counts']*detail['amounts']
print('detail新增列payment的前5行为:','\n',detail['payment'].head()) detail['pay_way'] = '现金支付'
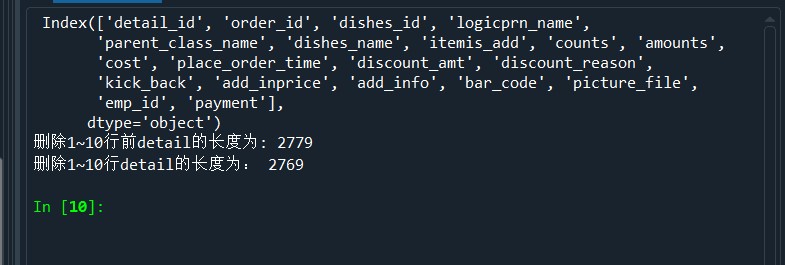
print('detail新增列pay_way的前5行为:','\n',detail['pay_way'].head()) print('删除pay_way前detail的列索引为:','\n',detail.columns)
detail.drop(labels = 'pay_way',axis = 1,inplace = True)
print('删除pay_way后detail的列索引为:','\n',detail.columns) print('删除1~10行前detail的长度为:',len(detail))
detail.drop(labels = range(1,11),axis = 0,inplace = True)
print('删除1~10行detail的长度为:',len(detail))
运行结果








2003031120—廖威—Python数据分析第七周作业—MySQL的安装以及使用的更多相关文章
- 2003031121——浦娟——Python数据分析第七周作业——MySQL的安装及使用
项目 要求 课程班级博客链接 20级数据班(本) 作业要求链接 Python第七周作业 博客名称 2003031121--浦娟--Python数据分析第七周作业--MySQL的安装及使用 要求 每道题 ...
- 2003031121-浦娟-python数据分析第三周作业-第一次作业
项目 内容 课程班级博客链接 https://edu.cnblogs.com/campus/pexy/20sj 作业链接 https://edu.cnblogs.com/campus/pexy/20s ...
- 2017-2018-1 我爱学Java 第六七周 作业
团队六七周作业 完善版需求规格说明书 制定团队编码规范 数据库设计 后端架构设计 TODOList 参考资料 完善版需求规格说明书 <需求规格说明书>初稿不足之处: 1.开发工具写错 2. ...
- 2018-2019-1 20189221 《Linux内核原理与分析》第七周作业
2018-2019-1 20189221 <Linux内核原理与分析>第七周作业 实验六 分析Linux内核创建一个新进程的过程 代码分析 task_struct: struct task ...
- 2017-2018-1 JAVA实验站 第六、七周作业
2017-2018-1 JAVA实验站 第六.七周作业 详情请见团队博客
- 2017-2018-1 JaWorld 第六、七周作业
2017-2018-1 JaWorld 第六.七周作业 修改需求规格说明书 上次的<需求规格说明书>初稿有哪些不足? 王译潇同学回答: 1. 引言和目的性考虑的不是很周全. 2. ...
- 2017-2018-1 20179205《Linux内核原理与设计》第七周作业
<Linux内核原理与设计>第七周作业 视频学习及操作分析 创建一个新进程在内核中的执行过程 fork.vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_for ...
- 2019-2020-1 20199325《Linux内核原理与分析》第七周作业
第七周作业 1.进程描述符task_struct数据结构(一) 为了管理进程,内核必须对每个进程进行清晰的描述,进程描述符提供了内核所需了解的进程信息. struct task_struct数据结构很 ...
- 2019-2020-1 20199329《Linux内核原理与分析》第七周作业
<Linux内核原理与分析>第七周作业 一.本周内容概述: 对Linux系统如何创建一个新进程进行追踪 分析Linux内核创建一个新进程的过程 二.本周学习内容: 1.学习进程的描述 操作 ...
- 2020-2021-1 20209307《Linux内核原理与分析》第七周作业
这个作业属于哪个课程 <2020-2021-1Linux内核原理与分析)> 这个作业要求在哪里 <2020-2021-1Linux内核原理与分析第七周作业> 这个作业的目标 & ...
随机推荐
- sqoop,hive2mysql
sqoop export \ --connect jdbc:mysql://master:3306/testdb \ --username hive \ --password 123456 \ --t ...
- vue+elementUI 在表格中动态增加与删除行
1.定义一个数组,存放表格数据(注:表格要给定一个高度,添加数据超过这个高度会自动出现滚动条) ttable:[], 2.把数组中表格的每一行定义成一个对象,添加到数组中 newconditions: ...
- 生产环境自动备份win服务器所有web项目(IIS+项目代码)
@echo offrem 功能:每月自动备份本服务器所有web项目rem 日期:2022.3.10rem 制作人:zl rem 定义变量Y为备份时间:YYYYMMset y=%date:~0,4%%d ...
- windows下C#读文件遇到一个路径的天坑
在win下面准备了一个文件,右键属性然后"安全"复制完整的文件路径, 放到C#代码(vs中编写)中来读取,竟然死活异常: System.IO.IOException HResult ...
- 获取git远程分支仓库
1:新建本地目录 2:进入并初始化这个目录 git init 3:新建一个文件,并添加 git add . 4: git commit -m "first commit" 5:新建 ...
- VUE前端请求跨域问题解决
解决方法: vue.config.js文件配置: module.exports = { devServer: { open: true, host: '192.168.1.193', port: 80 ...
- Rest-Assured:发送PATCH请求:更新Hello-imook(java.lang.IllegalArgumentException: Invalid number of path parameters. Expected 2, was 0. Undefined path parameters are: owner, repo.)
代码: /* * 发送PATCH请求:更新Hello-imook */ @Test public void test003_PatchMethod() { S ...
- win10事件查看器出现10016错误的解决办法
该错误一般会重复出现在事件查看器,严重的会导致系统卡死. 以解决下列错误为例,给出步骤: 注意记录用户(划掉的部分)及要添加的权限(本例为"本地激活"权限) 1.运行regedit ...
- kubeadm安装单master单node节点k8s集群
操作系统:centos7.6 podSubnet(pod 网段) 10.244.0.0/16 serviceSubnet(service 网段): 10.10.0.0/16 集群角色 IP 主机名 安 ...
- adb 测试常用命令
adb 环境安装并配置环境变量 常用命令汇总: 1.查看电脑已经连接的手机设备 adb devices 2.通过logcat日志获取应用APP入口 mac/linux:adb logcat Activ ...