2003031121——浦娟——Python数据分析第七周作业——MySQL的安装及使用
| 项目 | 要求 |
| 课程班级博客链接 | 20级数据班(本) |
| 作业要求链接 | Python第七周作业 |
| 博客名称 | 2003031121——浦娟——Python数据分析第七周作业——MySQL的安装及使用 |
| 要求 | 每道题要有题目,代码(使用插入代码,不会插入代码的自己查资料解决,不要直接截图代码!!),截图(只截运行结果) |
- 1.安装好MySQL,连接上Navicat。
- 2.完成课本练习(代码4-1~3/4-9~31)。
代码4-1至4-3
from sqlalchemy import create_engine
#创建一个MySQL连接器,用户名为root,密码为root1234
#地址为127.0.0.1数据库名称为testdb,编码为UTF—8
engine=create_engine("mysql+pymysql://root:root@127.0.0.1:3306/testdb?
charset=utf8")
print(engine) import pandas as pd
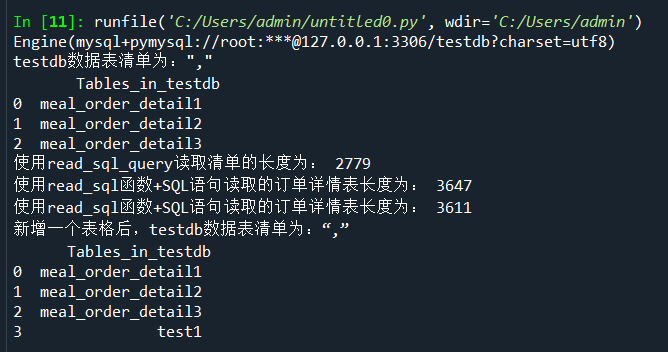
#使用read_sql_query查看testdb中的数据表书目
formlist=pd.read_sql_query('show tables',con=engine)
print('testdb数据表清单为:","\n ',formlist)
#使用read_sql_table读取订单详情表
detail1=pd.read_sql_table('meal_order_detail1',con=engine)
print("使用read_sql_query读取清单的长度为:",len(detail1)) detail2=pd.read_sql('select*from meal_order_detail2',con=engine)
print("使用read_sql函数+SQL语句读取的订单详情表长度为:",len(detail2)) detail3=pd.read_sql('meal_order_detail3',con=engine)
print('使用read_sql函数+SQL语句读取的订单详情表长度为:',len(detail3))
#使用to_sql存储orderDate
detail1.to_sql('test1',con=engine,index=False,if_exists='replace')
#使用read_sql读取test表
formlist1=pd.read_sql_query('show tables',con=engine)
print('新增一个表格后,testdb数据表清单为:“,”\n',formlist1)
代码4-9至4-11
#导入sqlalchemy 库的 create_engine函数
from sqlalchemy import create_engine
engine=create_engine("mysql+pymysql://root:root@127.0.0.1:3306/testdb?charset=utf8")
import pandas as pd
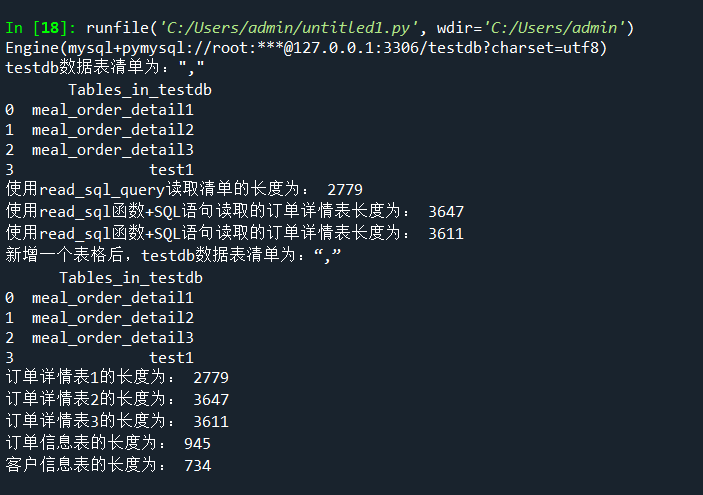
order1=pd.read_sql_table('meal_order_detail1',con=engine)
print("订单详情表1的长度为:",len(order1))
order2=pd.read_sql_table('meal_order_detail2',con=engine)
print("订单详情表2的长度为:",len(order2))
order3=pd.read_sql_table('meal_order_detail3',con=engine)
print("订单详情表3的长度为:",len(order3))
orderinfo=pd.read_table('E:/桌面/meal_order_info (1).csv',sep=",",encoding='gbk')
print('订单信息表的长度为:',len(orderinfo))
userinfo=pd.read_excel('E:/桌面/users (1).xlsx')
print('客户信息表的长度为:',len(userinfo))
代码4-12至4-31
detail = pd.read_sql_table('meal_order_detail1',con = engine)
'''print('订单详情的索引表为:',detail.index)
print('订单详情表的所有值为:','\n',detail.values)
print('订单详情表列名为:','\n',detail.columns)
print('订单详情表的数据类型为:','\n',detail.dtypes)'''
#查看DataFrame的元素个数
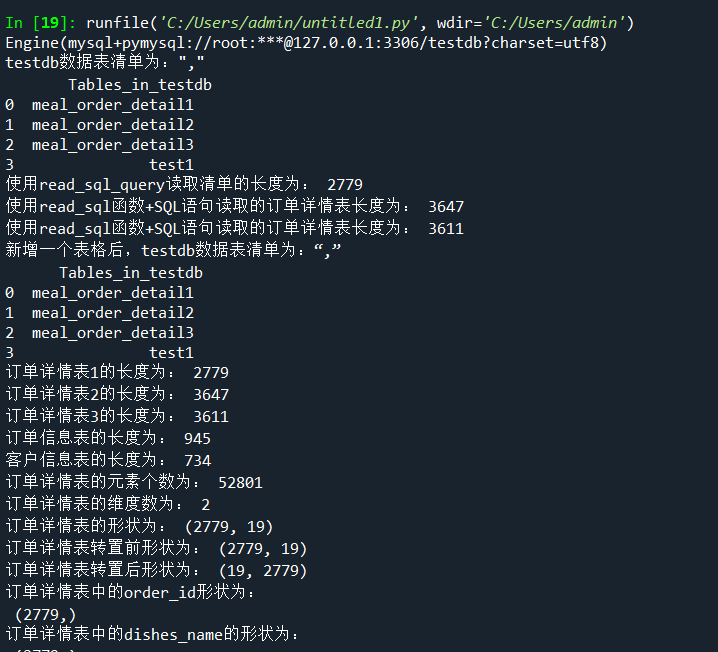
print('订单详情表的元素个数为:',detail.size)
print('订单详情表的维度数为:',detail.ndim)#查看DataFrame的维度数
print('订单详情表的形状为:',detail.shape)#查看DataFrame的形状
print('订单详情表转置前形状为:',detail.shape)
print('订单详情表转置后形状为:',detail.T.shape)
#使用字典访问的方式取出orderInfo中的某一列
order_id = detail['order_id']
print('订单详情表中的order_id形状为:','\n',order_id.shape)
#使用访问属性的方式取出orderInfo中的菜品名称列
dishes_name = detail.dishes_name
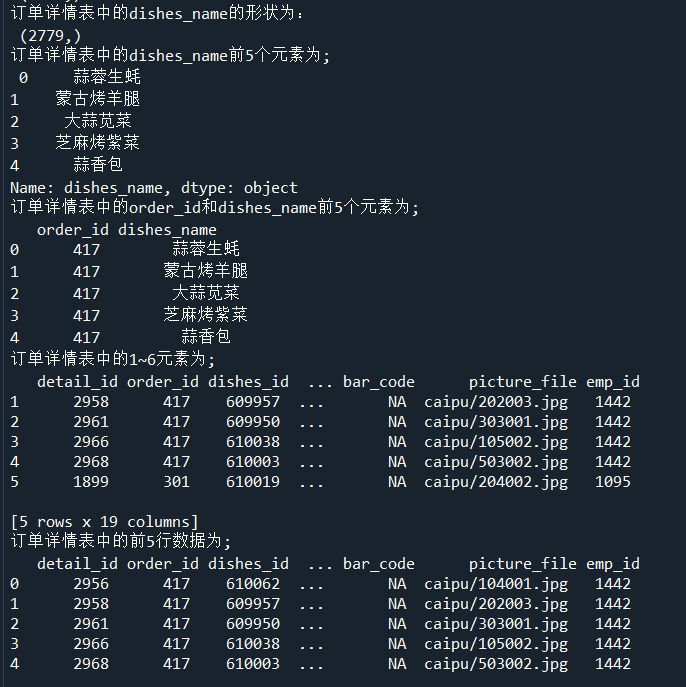
print('订单详情表中的dishes_name的形状为:','\n',dishes_name.shape)
dishes_name5 = detail['dishes_name'][:5]
print('订单详情表中的dishes_name前5个元素为;','\n',dishes_name5)
orderDish = detail[['order_id','dishes_name']][:5]
print('订单详情表中的order_id和dishes_name前5个元素为;','\n',orderDish)
order5 = detail[:][1:6]
print('订单详情表中的1~6元素为;','\n',order5)
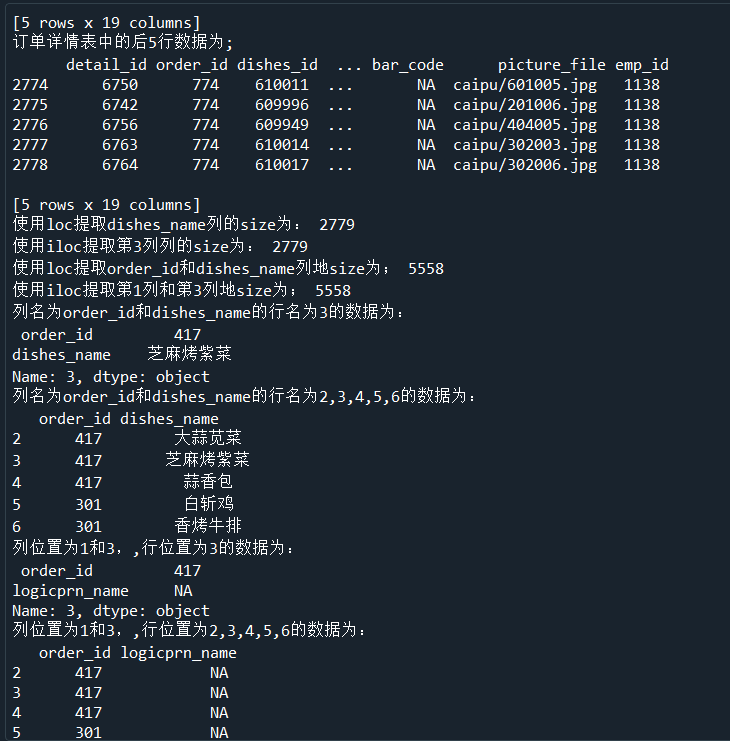
print('订单详情表中的前5行数据为;','\n',detail.head())
print('订单详情表中的后5行数据为;','\n',detail.tail())
dishes_name1 = detail.loc[:,'dishes_name']
print('使用loc提取dishes_name列的size为:',dishes_name1.size)
dishes_name2 = detail.iloc[:,3]
print('使用iloc提取第3列列的size为:',dishes_name2.size)
orderDish1 = detail.loc[:,['order_id','dishes_name']]
print('使用loc提取order_id和dishes_name列地size为;',orderDish1.size)
orderDish2 = detail.iloc[:,[1,3]]
print('使用iloc提取第1列和第3列地size为;',orderDish2.size)
print('列名为order_id和dishes_name的行名为3的数据为:\n',detail.loc[3,['order_id','dishes_name']])
print('列名为order_id和dishes_name的行名为2,3,4,5,6的数据为:\n',detail.loc[2:6,['order_id','dishes_name']])
print('列位置为1和3,,行位置为3的数据为:\n',detail.iloc[3,[1,3]])
print('列位置为1和3,,行位置为2,3,4,5,6的数据为:\n',detail.iloc[2:7,[1,3]])
#loc内部传入表达式
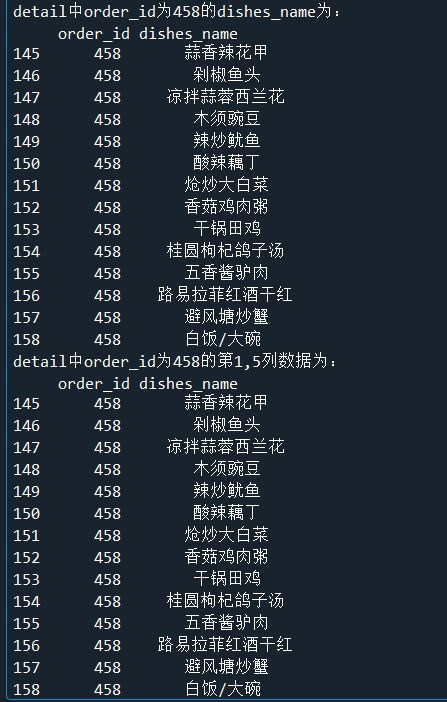
print('detail中order_id为458的dishes_name为:\n',detail.loc[detail['order_id']=='458',['order_id','dishes_name']])
#错误示例如下:
#print('detail中order_id为458的第1、5列数据为:\n',detail.iloc[detail['order_id']=='458',[1,5]])
print('detail中order_id为458的第1,5列数据为:\n',detail.iloc[(detail['order_id']=='458').values,[1,5]])
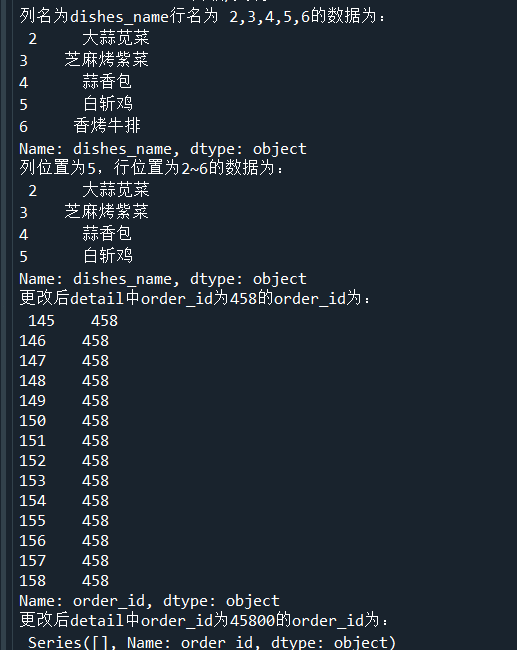
print('列名为dishes_name行名为 2,3,4,5,6的数据为:\n',detail.loc[2:6,'dishes_name'])
print('列位置为5,行位置为2~6的数据为:\n',detail.iloc[2:6,5])
#print('列位置为5,行名为2~6的数据为:', '\n',detail.ix[2:6,5]) #pandas的1.0.0版本后,已经对ix进行了升级和重构。
#将ordeer_id为458的变换为45800
detail.loc[detail['order_id']=='458','ordeer_id'] = '45800'
print('更改后detail中order_id为458的order_id为:\n',detail.loc[detail['order_id']=='458','order_id'])
print('更改后detail中order_id为45800的order_id为:\n',detail.loc[detail['order_id']=='45800','order_id'])
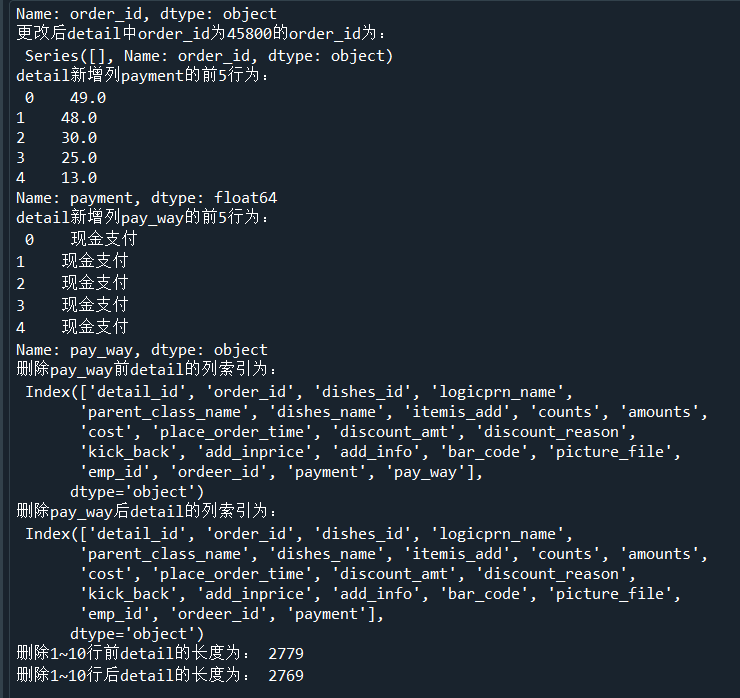
detail['payment'] = detail['counts']*detail['amounts']
print('detail新增列payment的前5行为:','\n',detail['payment'].head())
detail['pay_way'] = '现金支付'
print('detail新增列pay_way的前5行为:','\n',detail['pay_way'].head())
print('删除pay_way前detail的列索引为:','\n',detail.columns)
detail.drop(labels = 'pay_way',axis = 1,inplace = True)
print('删除pay_way后detail的列索引为:','\n',detail.columns)
print('删除1~10行前detail的长度为:',len(detail))
detail.drop(labels = range(1,11),axis = 0,inplace = True)
print('删除1~10行后detail的长度为:',len(detail))
2003031121——浦娟——Python数据分析第七周作业——MySQL的安装及使用的更多相关文章
- 2003031121-浦娟-python数据分析第三周作业-第一次作业
项目 内容 课程班级博客链接 https://edu.cnblogs.com/campus/pexy/20sj 作业链接 https://edu.cnblogs.com/campus/pexy/20s ...
- 2003031121-浦娟-python数据分析五一假期作业
项目 内容 课程班级博客链接 20级数据班(本) 这个作业要求链接 Python作业 博客名称 2003031121-浦娟-python数据分析五一假期作业 要求 每道题要有题目,代码(使用插入代码, ...
- 2003031121-浦娟-python数据分析第四周作业-第二次作业
项目 内容 课程班级博客链接 20级数据班(本) 作业链接 Python第四周作业第二次作业 博客名称 2003031121-浦娟-python数据分析第四周作业-matolotlib的应用 要求 每 ...
- 2017-2018-1 我爱学Java 第六七周 作业
团队六七周作业 完善版需求规格说明书 制定团队编码规范 数据库设计 后端架构设计 TODOList 参考资料 完善版需求规格说明书 <需求规格说明书>初稿不足之处: 1.开发工具写错 2. ...
- 2018-2019-1 20189221 《Linux内核原理与分析》第七周作业
2018-2019-1 20189221 <Linux内核原理与分析>第七周作业 实验六 分析Linux内核创建一个新进程的过程 代码分析 task_struct: struct task ...
- 2017-2018-1 JAVA实验站 第六、七周作业
2017-2018-1 JAVA实验站 第六.七周作业 详情请见团队博客
- 2017-2018-1 JaWorld 第六、七周作业
2017-2018-1 JaWorld 第六.七周作业 修改需求规格说明书 上次的<需求规格说明书>初稿有哪些不足? 王译潇同学回答: 1. 引言和目的性考虑的不是很周全. 2. ...
- 2017-2018-1 20179205《Linux内核原理与设计》第七周作业
<Linux内核原理与设计>第七周作业 视频学习及操作分析 创建一个新进程在内核中的执行过程 fork.vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_for ...
- 2019-2020-1 20199325《Linux内核原理与分析》第七周作业
第七周作业 1.进程描述符task_struct数据结构(一) 为了管理进程,内核必须对每个进程进行清晰的描述,进程描述符提供了内核所需了解的进程信息. struct task_struct数据结构很 ...
随机推荐
- 什么是Spring的依赖注入?
依赖注入,是IOC的一个方面,是个通常的概念,它有多种解释.这概念是说你不用创建对象,而只需要描述它如何被创建.你不在代码里直接组装你的组件和服务,但是要在配置文件里描述哪些组件需要哪些服务,之后一个 ...
- jQuery--内容过滤和可见性过滤
一.内容过滤 1.内容过滤选择器介绍 :empty 当前元素是否为空(是否有标签体) :contains(text) 标签体是否含有指定的文本 :has(...) ...
- SQLyog创建用户并授权的过程
点击你要授权的数据库然后点击用户管理器 然后输入用户名和密码主机选localhost 然后点击创建,然后选择你创建的数据库全选 最后保存就可以了
- @Controller 注解?
该注解表明该类扮演控制器的角色,Spring 不需要你继承任何其他控制器基类或 引用 Servlet API.
- 学习 Haproxy (五)
1 Linux Haproxy 负载均衡 v1.8 ★★★ 类似于ningx的反向代理1.1 Haproxy 概述 Haproxy是一个开源的高性能的反向代理或者说是负载均衡服务软件之一,它支持双机热 ...
- Effective Java —— 消除过期的对象引用
本文参考 本篇文章参考自<Effective Java>第三版第七条"Eliminate obsolete object references" Memory leak ...
- BMZCTF simple_pop
simple_pop 打开题目得到源码 这边是php伪协议的考点,需要去读取useless.php 解码获得源码 <?php class Modifier { protected $var; p ...
- asp.net 可视化操作(一)——asp.net安装与使用
目录 安装 创建网页 设计网页 运行 vs 2019安装asp.net 1.安装 打开vs,选择继续但无需代码 -->工具–>获取工具和功能 勾选如下选项后,点击关闭 点击更新等待安装完成 ...
- JQuery基础修炼-样式篇
jQuery对象转化成DOM对象 jQuery库本质上还是JavaScript代码,它只是对JavaScript语言进行包装处理,为了是提供更好更方便快捷的DOM处理与开发常见中经常使用的功能.我们可 ...
- html 元素 强制不换行
html 中 nowrap是用来强制不换行的 在排版中 对包裹plain text的标签使用nowrap属性即刻实现强制不换行. 如:<p nowrap>强制不换行</p>&l ...