BeautifulSoup图片爬取
------------恢复内容开始------------
BeautifulSoup介绍:
简单来说,Beautiful Soup 是 python 的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup 提供一些简单的、python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。 Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档转换为 utf-8 编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup 就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。 Beautiful Soup 已成为和 lxml、html6lib 一样出色的 python 解释器,为用户灵活地提供不同的解析策略或强劲的速度。
以下为爬取网页图片的例子:
爬取图片的网页地址:https://pic.netbian.com/4kdongman/
先创建一个requests的请求,然后使用BeautifulSoup的lxml HTML解析器去解析网页
url = 'https://pic.netbian.com/4kdongman/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
r = requests.get(url,headers=headers)
#设置编码为gbk,要不然会乱码
r.encoding='gbk'
#使用lxml解析器解析
soup = BeautifulSoup(r.text,'lxml')
编码格式可以从网页html中看到

接下来可以先定位到所有图片的整体div,例如class=’slist‘这个div,然后再定位每张图片的img标签,提取相关数据,得到每张图片的url地址
#定位所有图片的整体div
all_list = soup.find_all(attrs={'class': 'slist'})
#定位所有的img标签
img_list = all_list[0].find_all('img')
#遍历每个img标签
for img in img_list:
img_url = img['src']
name = img['alt']
#拼接图片url地址
img_url = 'https://pic.netbian.com' + img_url
#图片名称
print(name)
#图片url
print(img_url)
获取到每张图片的url地址后,就可以直接将其下载下来
方法一:with open直接将图片用字节流写入保存
r_img = requests.get(img_url)
with open('./img/'+name+'.jpg','wb+') as f:
#content返回的是二进制数据,如果你是取文本,你可以使用r.txt,如果取图片和文件,则是r.content
f.write(r_img.content)
方法二:直接使用urllib.request.urlretrieve下载
#第一个参数为要下载文件的url,第二个参数为本地保存路径以及文件名的路径
urllib.request.urlretrieve(img_url,'./img/'+name+'.jpg')
两种都可以实现,图片的下载,我保存的图片的地址为当前目录的img,从下面图片可以看到已经全部下载了
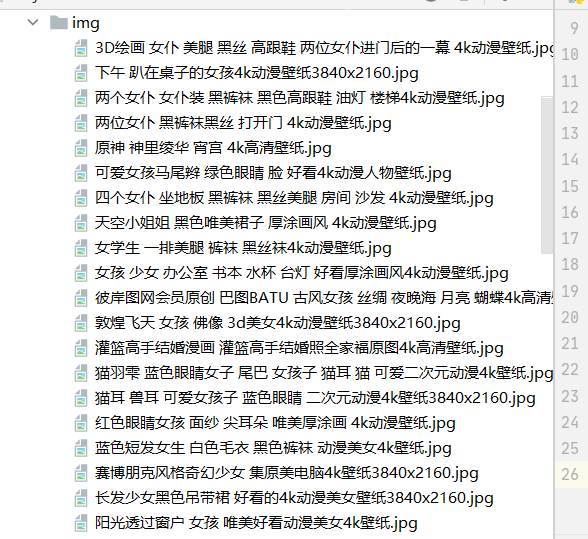
完整代码如下:
import urllib.request import requests
from bs4 import BeautifulSoup url = 'https://pic.netbian.com/4kdongman/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
r = requests.get(url,headers=headers)
#设置编码为gbk,要不然会乱码
r.encoding='gbk'
#使用lxml解析器解析
soup = BeautifulSoup(r.text,'lxml')
all_list = soup.find_all(attrs={'class': 'slist'})
img_list = all_list[0].find_all('img')
for img in img_list:
img_url = img['src']
name = img['alt']
img_url = 'https://pic.netbian.com' + img_url
print(name)
# r_img = requests.get(img_url)
# with open('./img/'+name+'.jpg','wb+') as f:
# f.write(r_img.content)
urllib.request.urlretrieve(img_url,'./img/'+name+'.jpg')
print('已经保存完成:'+img_url)
------------恢复内容结束------------
BeautifulSoup图片爬取的更多相关文章
- Python爬虫入门教程 26-100 知乎文章图片爬取器之二
1. 知乎文章图片爬取器之二博客背景 昨天写了知乎文章图片爬取器的一部分代码,针对知乎问题的答案json进行了数据抓取,博客中出现了部分写死的内容,今天把那部分信息调整完毕,并且将图片下载完善到代码中 ...
- 用BeautifulSoup简单爬取BOSS直聘网岗位
用BeautifulSoup简单爬取BOSS直聘网岗位 爬取python招聘 import requests from bs4 import BeautifulSoup def fun(path): ...
- 4k图片爬取+中文乱码
4k图片爬取+中文乱码 此案例有三种乱码解决方法,推荐第一种 4k图片爬取其实和普通图片爬取的过程是没有本质区别的 import requests import os from lxml import ...
- scrapy之360图片爬取
#今日目标 **scrapy之360图片爬取** 今天要爬取的是360美女图片,首先分析页面得知网页是动态加载,故需要先找到网页链接规律, 然后调用ImagesPipeline类实现图片爬取 *代码实 ...
- [Python_scrapy图片爬取下载]
welcome to myblog Dome地址 爬取某个车站的图片 item.py 中 1.申明item 的fields class PhotoItem(scrapy.Item): # define ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- python+BeautifulSoup+多进程爬取糗事百科图片
用到的库: import requests import os from bs4 import BeautifulSoup import time from multiprocessing impor ...
- 使用BeautifulSoup自动爬取微信公众号图片
爬取微信分享的图片,根据不同的页面自行修改,使用BeautifulSoup爬取,自行格局HTML修改要爬取图片的位置 import re import time import requests imp ...
- 网络爬虫之网站图片爬取-python实现
版本1.5 本次简单添加了四路多线程(由于我电脑CPU是四核的),速度飙升.本想试试xPath,但发现反倒是多此一举,故暂不使用 #-*- coding:utf-8 -*- import re,url ...
随机推荐
- vc获取进程版本号
#param comment(lib, "version.lib") CString &CMonitorManagerDlg::GetApplicationVersion( ...
- Java 中使用正则表达式校检IP是否输入正确
感谢大佬案例:https://www.jb51.net/article/114671.htm 正则表达式学习:(待办)近期总结
- CSS 圆角框
转载请注明来源:https://www.cnblogs.com/hookjc/ 其实这种圆角框是靠一个个容器堆砌而成的,每一个容器的宽度不同,这个宽度是由margin外边距来实现的,如:margin: ...
- 推荐的php安全配置选项
推荐安全配置选项 这里有几个会影响安全功能的 PHP 配置设置.下面是一些显然应该用于生产服务器的: register_globals 设置为 offsafe_mode 设置为 offerror_re ...
- 前端-Data URI Scheme
了解Data URI scheme,首要要掌握一些URI.URL的基本知识,很多做移动端上开发的同学对这两个基本概念掌握的不够,本文首先会对这两个基本概念做一些简单的介绍. 基本概念 <HTTP ...
- epoll反应堆模型实现
epoll反应堆模型demo实现 在高并发TCP请求中,为了实现资源的节省,效率的提升,Epoll逐渐替代了之前的select和poll,它在用户层上规避了忙轮询这种效率不高的监听方式,epoll的时 ...
- 编译安装http2.4
编译安装http2.4 1.安装相关依赖包 [root@centos7 ~]yum -y install gcc make 2.下载http2.4包,并解压 [root@centos7 ~]#tar ...
- Java中的多线程你只要看这一篇就够了(引用)
引 如果对什么是线程.什么是进程仍存有疑惑,请先Google之,因为这两个概念不在本文的范围之内. 用多线程只有一个目的,那就是更好的利用cpu的资源,因为所有的多线程代码都可以用单线程来实现.说这个 ...
- Pytest介绍
Pytest介绍 pytest是python的一种单元测试框架,与python自带的unittest测试框架类似,但是比unittest框架使用起来更简洁,效率更高.根据pytest的官方网站介绍,它 ...
- 如何在Kubernetes 里添加自定义的 API 对象(一)
环境: golang 1.15 依赖包采用go module 实例:现在往 Kubernetes 添加一个名叫 Network 的 API 资源类型.它的作用是,一旦用户创建一个 Network 对象 ...