python+BeautifulSoup+多进程爬取糗事百科图片
用到的库;
import requests
import os
from bs4 import BeautifulSoup
import time
from multiprocessing import Pool
定义图片存储路径;
path = r'E:\爬虫\0805\\'
请求头,模拟浏览器请求;
在浏览器中的位置,按f12打开开发者模式;
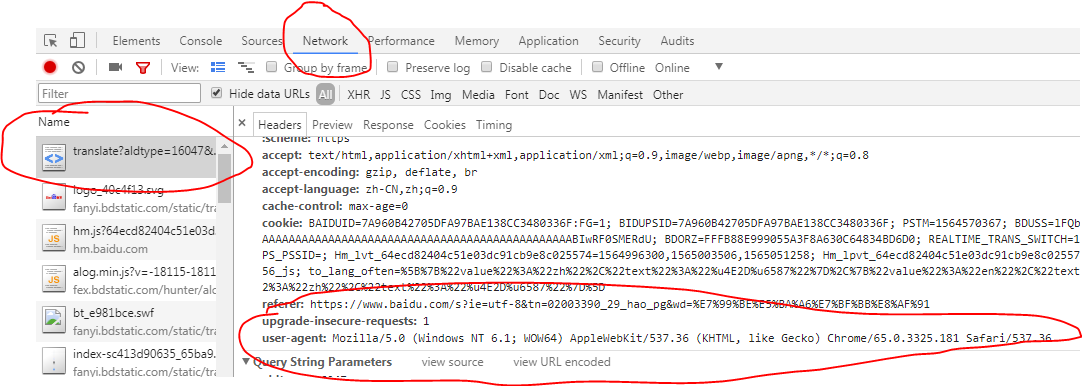
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
主函数;
def get_images(url):
data = 'https:'
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,'lxml')
url_infos = soup.select('div.thumb > a > img')
# print(url_infos)
for url_info in url_infos:
try:
urls = data+url_info.get('src')
if os.path.exists(path+urls.split('/')[-1]):
print('图片已下载')
else:
image = requests.get(urls,headers=headers)
with open(path+urls.split('/')[-1],'wb') as fp:
fp.write(image.content)
print('正在下载:'+urls)
time.sleep(0.5)
except Exception as e:
print(e)
开始爬虫程序;
if __name__ == '__main__':
# 路由列表
urls = ['https://www.qiushibaike.com/imgrank/page/{}/'.format(i) for i in range(1,14)]
# 开启多进程爬取
pool = Pool()
pool.map(get_images,urls)
print('抓取完毕')
爬取中;

打开文件夹查看爬取结果;
done
完整代码;
import requests
import os
from bs4 import BeautifulSoup
import time
from multiprocessing import Pool
"""
************常用爬虫库***********
requests
BeautifulSoup
pyquery
lxml
************爬虫框架***********
scrapy
三大解析方式:re,css,xpath
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
path = r'E:\爬虫\0805\\'
def get_images(url):
data = 'https:'
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,'lxml')
url_infos = soup.select('div.thumb > a > img')
# print(url_infos)
for url_info in url_infos:
try:
urls = data+url_info.get('src')
if os.path.exists(path+urls.split('/')[-1]):
print('图片已下载')
else:
image = requests.get(urls,headers=headers)
with open(path+urls.split('/')[-1],'wb') as fp:
fp.write(image.content)
print('正在下载:'+urls)
time.sleep(0.5)
except Exception as e:
print(e) if __name__ == '__main__':
# 路由列表
urls = ['https://www.qiushibaike.com/imgrank/page/{}/'.format(i) for i in range(1,14)]
# 开启多进程爬取
pool = Pool()
pool.map(get_images,urls)
print('抓取完毕')
python+BeautifulSoup+多进程爬取糗事百科图片的更多相关文章
- python+正则+多进程爬取糗事百科图片
话不多说,直接上代码: # 需要的库 import requests import re import os from multiprocessing import Pool # 请求头 header ...
- python爬虫之爬取糗事百科并将爬取内容保存至Excel中
本篇博文为使用python爬虫爬取糗事百科content并将爬取内容存入excel中保存·. 实验环境:Windows10 代码编辑工具:pycharm 使用selenium(自动化测试工具)+p ...
- Python爬虫:爬取糗事百科
网上看到的教程,但是是用正则表达式写的,并不能运行,后面我就用xpath改了,然后重新写了逻辑,并且使用了双线程,也算是原创了吧#!/usr/bin/python# -*- encoding:utf- ...
- 8.Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- [爬虫]用python的requests模块爬取糗事百科段子
虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Humans”,说明使用更 ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
随机推荐
- SpringBoot 为什么能够自动的注入一些常用的Bean ?
原文转载至:https://blog.csdn.net/qq_29941401/article/details/79605388 但是我一直没有搞懂druid是怎么自动配置的? 这个是properti ...
- linux服务器之间文件传输
有时候我们会遇到,把一个服务器上的文件夹,传到另一个服务器 我们需要先把文件夹打包成 tar.gz,这种格式在任何linux版本上都能压缩/解压 #解压命令 tar -zxvf xxx.tar.gz ...
- Dockerfile HEALTHCHECK健康检查
Dockerfile中使用HEALTHCHECK的形式有两种: 1.HEALTHCHECK [options] CMD command 2.HEALTHCHECK NODE 意思是禁止从父镜像继承的H ...
- 简述 高性能Linux服务器 模型架构 设计
主要从三个方面进行分析: 1.事件处理模式 2.并发模式 一.事件处理模式 1.Reactoor模式 定义: 主线程只负责监听文件描述符上是否有事件发生,有的话立即将该事件通知工作线程,除此之外,主线 ...
- 如何自己手动修改win10磁贴背景颜色?
前言 当我们安装完应用后,可以选择将应用图标固定到"开始"屏幕,于是就会产生一个磁贴,有的应用会自带背景颜色,有的则是默认的主题色.其实这个只不过是应用本身没有没有去适配win10 ...
- Python之路【第十九篇】:前端CSS
CSS 一.CSS概述 CSS是Cascading Style Sheets的简称,中文称为层叠式样式表,用来控制网页数据的表现,可以使网页的表现与数据内容分离. 学CSS后我们需要掌握的技能: 1. ...
- cocos creator图片渲染问题!
问题:游戏项目需要添加一个开场剧情(); 第一时间使用了cc.component.scheduleOnce (), 里面的回调函数为 cc.loader.loadRes(). 进入游戏时,渲染主场景后 ...
- Spark实战电影点评系统(二)
二.通过DataFrame实战电影点评系统 DataFrameAPI是从Spark 1.3开始就有的,它是一种以RDD为基础的分布式无类型数据集,它的出现大幅度降低了普通Spark用户的学习门槛. D ...
- jwt的思考
什么是jwt jwt的问题 jwt的是实践 https://www.pingidentity.com/en/company/blog/posts/2019/jwt-security-nobody-ta ...
- Spring Boot Freemarker特别篇之contextPath【从零开始学Spring Boot
需求缘起:有人在群里@我:请教群主大神一个问题,spring boot + freemarker 怎么获取contextPath 头疼死我了,网上没一个靠谱的 .我就看看之前博客中的 [Spri ...