爬虫(6) - 网页数据解析(2) | BeautifulSoup4在爬虫中的使用
什么是Beautiful Soup库
- Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能
- 它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序
- Beautiful Soup就是python的一个库,最主要的功能是从网页获取数据
- BeautifulSoup4==4.7.1第四版本,简称bs4
学习Beautiful Soup库的目的
增加一种获取数据的方法
- 正则表达式:https://www.cnblogs.com/gltou/p/15783716.html
- Xpath:https://www.cnblogs.com/gltou/p/16327688.html
- bs4
安装Beautiful Soup库
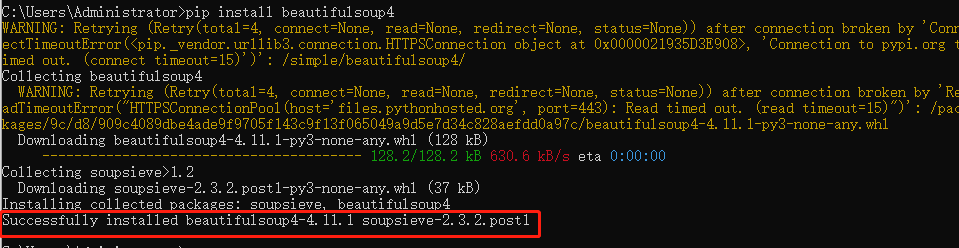
cmd输入以下命令:
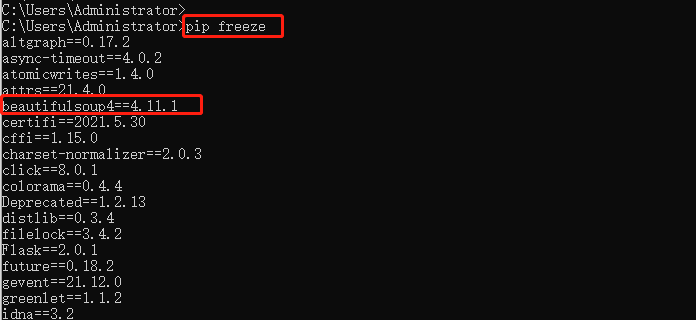
pip install beautifulsoup4

结果报错了,解决方案:在d:\python\python37\lib\site-packages目录下删除~ip开头的目录文件夹

重新执行命令
Beautiful Soup支持的解析器
| 解析器 | 使用方法 | 优势 | 劣势 |
| python标准库 | BeautifulSoup(markup,"html.parser") | python的内置标准库,执行速度适中、文档容错能力强 | python 2.7.3及Python 3.2.2之前的版本文档容错能力差 |
| lxml HTML解析器 | BeautifulSoup(markup,"lxml") | 速度快、文档容错能力强 | 需要安装C语言库 |
| lxml XML解析器 | BeautifulSoup(markup,"xml") | 速度快,唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup,"html5lib") | 最好的容错性、以浏览器的方式解析文档、生成HTML5的格式的文档 | 速度慢、不依赖外部扩展 |
实际工作中前两个用的最多,前两个中重点掌握第二个;后面的笔记以lxml为主
安装lxml解析器
pip install lxml
我之前已经安装过了,所以没有安装过程截图。

解析节点及属性值
示例
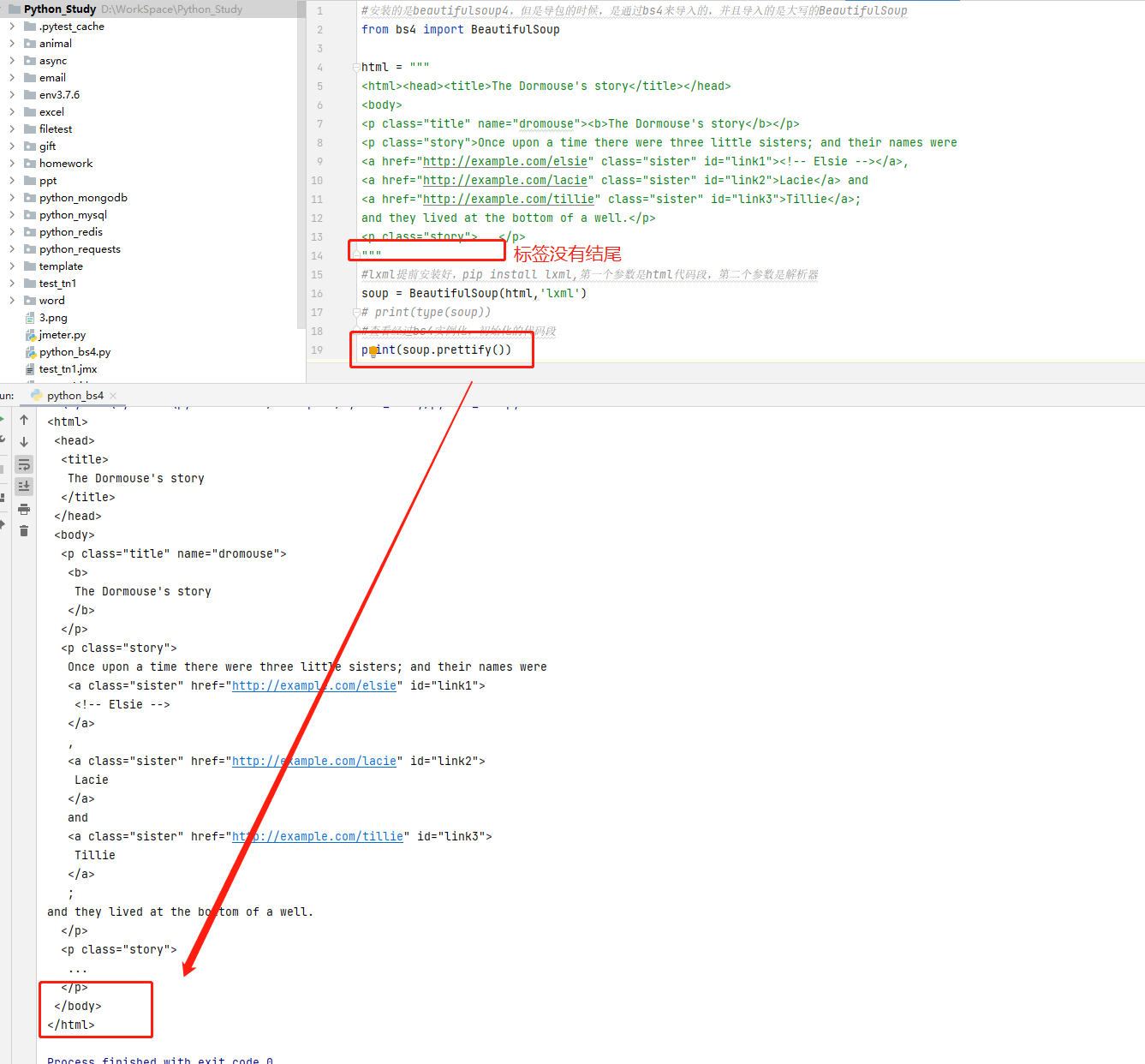
1 #安装的是beautifulsoup4,但是导包的时候,是通过bs4来导入的,并且导入的是大写的BeautifulSoup
2 from bs4 import BeautifulSoup
3
4 html = """
5 <html><head><title>The Dormouse's story</title></head>
6 <body>
7 <p class="title" name="dromouse"><b>The Dormouse's story</b></p>
8 <p class="story">Once upon a time there were three little sisters; and their names were
9 <a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
10 <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
11 <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
12 and they lived at the bottom of a well.</p>
13 <p class="story">...</p>
14 """
15 #lxml提前安装好,pip install lxml,第一个参数是html代码段,第二个参数是解析器
16 soup = BeautifulSoup(html,'lxml')
17 #查看经过bs4实例化,初始化的代码段
18 # print(soup.prettify())
19 #获取到的是数据结构,tag,tag有很多方法,如string
20 # print(type(soup.title))
21 #来查看文档中title的属性值
22 # print(soup.title.string)
23 # print(soup.head)
24 #当有多个节点的时候,我们当前的这种选择模式,只能匹配到第一个节点,其他节点会被忽略
25 # print(soup.p)
26 #获取节点的名称
27 # print(soup.title.name)
28 #attrs会返回标签的所有属性值,返回的是一个字典
29 # print(soup.p.attrs)
30 # print(soup.p.attrs['name'])
31 #返回的节点属性,可能是列表,也可能是字符串,需要进行实际的判断
32 # print(soup.p['name'])
33 # print(soup.p['class'])
| 方法 | 作用 | 示例结果 |
soup = BeautifulSoup(html,'lxml') |
实例化对象,解析器用的是lxml |
>> print(type(soup)) |
soup.prettify() |
初始化代码段,即将示例不规则代码, |
 |
soup.title |
获取到的是数据结构tag,tag有很多 |
>>> print(type(soup.title))
|
soup.title.string |
查看文档中title的属性值 |
>>>print(soup.title) |
soup.p |
当有多个节点的时候,我们当前的这种 |
>>> print(soup.p) |
soup.title.name |
获取节点的名称 |
>>> print(soup.title.name) |
soup.p.attrs |
attrs会返回标签的所有属性值,返回的 |
>>> print(soup.p.attrs) |
soup.p['name'] |
返回的节点属性,可能是列表,也可能是 |
>>> print(soup.p['name']) |

BeautifulSoup解析节点,只能匹配第一个节点!!!
获取子节点和孙节点
示例-1:嵌套调用
1 #嵌套调用
2
3 from bs4 import BeautifulSoup
4
5 html = """
6 <html><head><title>The Dormouse's story</title></head>
7 <body>
8 <p class="title" name="dromouse"><b>The Dormouse's story</b></p>
9 <p class="story">Once upon a time there were three little sisters; and their names were
10 <a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
11 <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
12 <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
13 and they lived at the bottom of a well.</p>
14 <p class="story">...</p>
15 """
16
17 soup = BeautifulSoup(html,'lxml')
18 #嵌套调用,查找head节点下面的title节点
19 print(soup.head.title)
20
21 #两个都是bs4.element.Tag
22 print(type(soup.head))
23 print(type(soup.head.title))
24
25 #查找head节点下面的title节点的内容
26 print(soup.head.title.string)
| 方法 | 作用 | 示例结果 |
soup.head.title |
嵌套调用,查找head节点下面的title节点 |
>>> print(soup.head.title) |
soup.head |
查看两个节点的类型,都是bs4.element.Tag |
>>> print(type(soup.head)) |
soup.head.title.string |
查找head节点下面的title节点的内容 |
>>> print(soup.head.title.string) |
示例-2:子节点和子孙节点调用
1 #子节点和子孙节点
2 from bs4 import BeautifulSoup
3
4 html = """
5 <html>
6 <head>
7 <title>The Dormouse's story</title>
8 </head>
9 <body>
10 <p class="story">
11 Once upon a time there were three little sisters; and their names were
12 <a href="http://example.com/elsie" class="sister" id="link1">
13 <span>Elsie</span>
14 </a>
15 <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
16 and
17 <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
18 and they lived at the bottom of a well.
19 </p>
20 <p class="story">...</p>
21 """
22
23 soup = BeautifulSoup(html,'lxml')
24
25 #获取p标签的子节点,注意是子节点,返回的是一个列表
26 #列表中的元素是p节点的直接子节点
27 #返回结果没有单独的吧a标签中的span标签选出来
28 #contents方法获取直接子节点的列表
29 print(soup.p.contents)
30 print(soup.p.contents[0])
31 print(len(soup.p.contents))
32
33 #contents和children返回的结果是一样的,都是直接子节点
34 #只不过children方法返回的是一个迭代器,需要使用for循环来进行遍历
35 print(soup.p.children)
36 for i,j in enumerate(soup.p.children):
37 print(i,j)
38 print("==============================")
39
40 #获取子节点和孙节点
41 #会把中间的孙节点也单独的取出来
42 print(soup.p.descendants)
43 for i,j in enumerate(soup.p.descendants):
44 print(i,j)
| 方法 | 作用 | 示例结果 |
soup.p.contents |
获取p标签的子节点,注意是子节点,返回的是一个列表; |
>>> print(soup.p.contents)
>>> print(soup.p.contents[0]) |
soup.p.children |
contents和children返回的结果是一样的,都是直 |
>>> print(soup.p.children)
|
soup.p.descendants |
获取p标签子节点和孙节点; |
>>> print(soup.p.descendants)
|

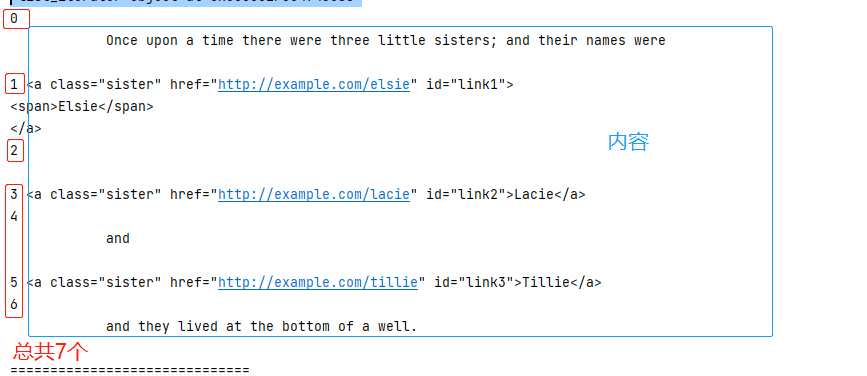
这个里面直接子节点和子节点是有区别的,可能不太容易理解,简单讲解一下:
直接子节点:
contents;children
- 所有儿子节点,至于你儿子节点里面有没有孙子节点,都跟你儿子节点算一个
- 人家跟你说:明天来吃席,一家都来哈。第二天你们家都去了,不分大人小孩坐在了一桌
子节点
descendants
- 所有儿子节点输出的同时,如果节点里面有孙子、重孙子...节点的依次输出
- 人家跟你说:明天来吃席,一家都来哈。第二天你们家都去了,先看你家人都到了没有,先做一桌子,输出一下;以家为单位输出结束后,再依次输出你孙子一大家、然后重孙子一大家
获取父节点、祖先节点、兄弟节点
示例-1:获取父节点、祖先节点
1 #获取父节点和获取祖先节点
2
3 from bs4 import BeautifulSoup
4
5 html = """
6 <html>
7 <head>
8 <title>The Dormouse's story</title>
9 </head>
10 <body>
11 <p class="story">
12 Once upon a time there were three little sisters; and their names were
13 <a href="http://example.com/elsie" class="sister" id="link1">
14 <span>Elsie</span>
15 </a>
16 </p>
17 <p class="story">...</p>
18 """
19
20 soup = BeautifulSoup(html,'lxml')
21 #获取a节点的父节点
22 print(soup.a.parent)
23
24 #获取所有的祖先节点,返回的是迭代器
25 print(soup.a.parents)
26 for i,j in enumerate(soup.a.parents):
27 print(i,j)
| 方法 | 作用 | 示例结果 |
soup.a.parent |
获取a节点的父节点; |
>>> print(soup.a.parent)
|
soup.a.parents |
依次往上找,获取所有的祖先节点, |
>>> print(soup.a.parents)
|

示例-2:获取兄弟节点
1 from bs4 import BeautifulSoup
2
3 html = """
4 <html>
5 <body>
6 <p class="story">
7 Once upon a time there were three little sisters; and their names were
8 <a href="http://example.com/elsie" class="sister" id="link1">
9 <span>Elsie</span>
10 </a>
11 Hello
12 <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
13 and
14 <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
15 and they lived at the bottom of a well.
16 </p>
17 """
18
19 soup = BeautifulSoup(html,'lxml')
20 #获取a标签的下一个兄弟节点
21 # print(soup.a.next_sibling)
22
23 #获取上一个兄弟节点
24 # print(soup.a.previous_sibling)
25
26 #获取当前节点后面的所有兄弟节点
27 # print(soup.a.next_siblings)
28 # for i,j in enumerate(soup.a.next_siblings):
29 # print(i,j)
30
31 #获取当前节点前面所有的兄弟节点
32 print(soup.a.previous_siblings)
33 for i,j in enumerate(soup.a.previous_siblings):
34 print(i,j)
| 方法 | 作用 | 示例结果 |
soup.a.next_sibling |
获取a标签的下一个兄弟节点 |
>>> print(soup.a.next_sibling) Hello |
soup.a.previous_sibling |
获取上一个兄弟节点 |
>>> print(soup.a.previous_sibling) |
soup.a.next_siblings |
获取当前节点后面的所有兄弟节点 |
>>> print(soup.a.next_siblings)
|
soup.a.previous_siblings |
获取当前节点前面所有的兄弟节点 |
>>> print(soup.a.previous_siblings)
|


方法选择器
find和find_all方法
- find_parents 和 find_parent:前者返回所有祖先节点,后者返回直接父节点。
- find_next_siblings 和 find_next_sibling:前者返回后面所有的兄弟节点,后者返回后面第一个兄弟节点。
- find_previous_siblings 和 find_previous_sibling:前者返回前面所有的兄弟节点,后者返回前面第一个兄弟节点。
- find_all_next 和 find_next:前者返回节点后所有符合条件的节点,后者返回第一个符合条件的节点。
- find_all_previous 和 find_previous:前者返回节点前所有符合条件的节点,后者返回第一个符合条件的节点。
| 方法 | 表达式 | 示例 |
soup.find_all() |
find_all:返回的是列表 |
#attrs,传入的是属性参数,类型是字典,attrs={"id":"list-1"}
|
soup.find() |
#find方法,返回的是一个单个的元素,第一个匹配的元素,而find_all返回的是所有值的列表 |
|
find_parents 和 find_parent:前者返回所有祖先节点,后者返回直接父节点 |
||
find_next_siblings 和 find_next_sibling:前者返回后面所有的兄弟节点,后者返回后面第一个兄弟节点 |
||
find_previous_siblings 和 find_previous_sibling:前者返回前面所有的兄弟节点,后者返回前面第一个兄弟节点 |
||
find_all_next 和 find_next:前者返回节点后所有符合条件的节点,后者返回第一个符合条件的节点 |
||
find_all_previous 和 find_previous:前者返回节点前所有符合条件的节点,后者返回第一个符合条件的节点 |
||
示例-1:find_all通过节点名进行查询
1 #方法选择器,find_all,通过节点名来进行查询的
2
3 from bs4 import BeautifulSoup
4
5 html='''
6 <div class="panel">
7 <div class="panel-heading">
8 <h4>Hello</h4>
9 </div>
10 <div class="panel-body">
11 <ul class="list" id="list-1">
12 <li class="element">Foo</li>
13 <li class="element">Bar</li>
14 <li class="element">Jay</li>
15 </ul>
16 <ul class="list list-small" id="list-2">
17 <li class="element">Foo</li>
18 <li class="element">Bar</li>
19 </ul>
20 </div>
21 </div>
22 '''
23
24 soup = BeautifulSoup(html,'lxml')
25 #find_all,name=li,可以获取到当前文本中所有li标签的数据,返回的是一个列表
26 print(soup.find_all(name='li')) #[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>, <li class="element">Foo</li>, <li class="element">Bar</li>]
27 print(soup.find_all(name='li')[0]) #<li class="element">Foo</li>
28
29 #tag类型
30 print(type(soup.find_all(name='li')[0])) #<class 'bs4.element.Tag'>
31
32 #可以进行嵌套查询
33 for ul in soup.find_all(name="ul"):
34 for li in ul.find_all(name='li'):
35 #tag
36 print(li.string) #FooBar Jay Foo Bar
示例-2:find_all通属性进行查询
1 #通过属性来进行查询
2 #通过text文本来获取匹配的文本
3
4 import re
5 from bs4 import BeautifulSoup
6
7 html='''
8 <div class="panel">
9 <div class="panel-heading">
10 <h4>Hello</h4>
11 </div>
12 <div class="panel-body">
13 <ul class="list" id="list-1" name="elements">
14 <li class="element">Foo</li>
15 <li class="element">Bar</li>
16 <li class="element">Jay</li>
17 </ul>
18 <ul class="list" id="list-1">
19 <li class="element">Foo2</li>
20 <li class="element">Bar2</li>
21 <li class="element">Jay2</li>
22 </ul>
23 <ul class="list list-small" id="list-2">
24 <li class="element">Foo</li>
25 <li class="element">Bar</li>
26 </ul>
27 </div>
28 </div>
29 '''
30
31 soup = BeautifulSoup(html,'lxml')
32 #attrs,传入的是属性参数,类型是字典,attrs={"id":"list-1"}
33 print(soup.find_all(attrs={"id":"list-1"}))
34 print(soup.find_all(attrs={"name":"elements"}))
35
36 #也可以直接传入ID这个参数
37 print(soup.find_all(id="list-1"))
38
39 #class在Python中是一个关键字,find_all方法里面要用class的时候,后面加上一个下划线
40 print(soup.find_all(class_="list"))
41
42 #可以通过text参数来获取文本的值,可以传递正则表达式,返回是一个列表
43 print(soup.find_all(text=re.compile("Foo\d")))
44
45 #find方法,返回的是一个单个的元素,第一个匹配的元素,而find_all返回的是所有值的列表
46 print(soup.find(name="ul"))
使用css选择器获取元素
- 建议大家使用find find_all查询匹配单个结果或多个结果
- css选择器非常的熟悉,那么就可以使用css选择器
#使用css选择器,只需要呢,调用select方法,传入css选择器即可 from bs4 import BeautifulSoup html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
''' soup = BeautifulSoup(html,'lxml')
#需要调用select方法,传入css选择器,class用.来表示;通过空格继续书写子节点
# print(soup.select(".panel .panel-heading")) #获取ul标签下所有Li标签
# print(soup.select("ul li")) #获取id为list-2,class为element两个Li标签;id属性简写是#
# print(type(soup.select("#list-2 .element")[0])) #支持嵌套选择
#先获取到ul标签,tag类型,for 调用select方法在次传入css选择器
for ul in soup.select("ul"):
for li in ul.select("li"):
#调用tag类型里面的方法,string方法来获取文本内容
# print(li.string)
print(li['class']) #支持使用属性获取元素
# for ul in soup.select("ul"):
# print(ul['id']) #建议大家使用find find_all查询匹配单个结果或多个结果
#css选择器非常的熟悉,那么就可以使用css选择器
案例-BS4解析网站数据
1 import requests
2 from bs4 import BeautifulSoup
3
4
5 def handle_detail_bs4(content):
6 """
7 解析目标页面返回数据的
8 :param content:response.text
9 :return:
10 """
11 # 数据的实例化,传入要解析的数据,和解析器,解析器使用的是lxml
12 soup = BeautifulSoup(content, "lxml")
13 # 获取所有的图书条目,使用find_all,查找div标签,通过class属性查找,class是一个关键字,class_
14 all_book_items = soup.find_all("div", class_="row col-padding")
15 # 打印未格式化的数据,可以看到html标签的
16 for item in all_book_items:
17 # print(item)
18 # 获取图书信息,先查找上层的div,发现里面包含着三个span,find_all来查找所有span
19 info = item.find("div", class_="col-md-7 flex-vertical description-font").find_all("span")
20 # 获取作者,出版社,价格信息
21 author_press_price = info[1].string.split("/")
22 if len(author_press_price) == 3:
23 print(
24 {
25 # 最终信息
26 "title": info[0].string,
27 "author": author_press_price[0],
28 "press": author_press_price[1],
29 "price": author_press_price[2],
30 "summary": info[2].string
31 }
32 )
33
34
35 def main():
36 header = {
37 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
38 }
39 for i in range(1, 5):
40 url = "http://yushu.talelin.com/book/search?q=python&page={}".format(i)
41 response = requests.get(url=url, headers=header)
42 handle_detail_bs4(response.text)
43
44
45 if __name__ == '__main__':
46 main()
爬虫(6) - 网页数据解析(2) | BeautifulSoup4在爬虫中的使用的更多相关文章
- 20170717_python_爬虫_网页数据解析_BeautifulSoup_数据保存_pymysql
上午废了老大劲成功登陆后,下午看了下BeautifulSoup和pymysql,晚上记录一下 自己电脑装的sublime,字体颜色竟然拷贝不下来 - - 写的过程中遇到了很多问题: 1.模拟登陆部分 ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(1)
一.数据类型及解析方式 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为两部分,非结构化的数据 和 结构化的数据. 非结构化数据:先有数据,再有结构, 结构化数 ...
- Python网络爬虫之三种数据解析方式
1. 正则解析 正则例题 import re # string1 = """<div>静夜思 # 窗前明月光 # 疑是地上霜 # 举头望明月 # 低头思故乡 ...
- Python网络爬虫实战(二)数据解析
上一篇说完了如何爬取一个网页,以及爬取中可能遇到的几个问题.那么接下来我们就需要对已经爬取下来的网页进行解析,从中提取出我们想要的数据. 根据爬取下来的数据,我们需要写不同的解析方式,最常见的一般都是 ...
- 05.Python网络爬虫之三种数据解析方式
引入 回顾requests实现数据爬取的流程 指定url 基于requests模块发起请求 获取响应对象中的数据 进行持久化存储 其实,在上述流程中还需要较为重要的一步,就是在持久化存储之前需要进行指 ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(2)
上半部分内容链接 : https://www.cnblogs.com/lowmanisbusy/p/9069330.html 四.json和jsonpath的使用 JSON(JavaScript Ob ...
- Python爬虫之三种数据解析方式
一.引入 二.回顾requests实现数据爬取的流程 指定url 基于requests模块发起请求 获取响应对象中的数据 进行持久化存储 其实,在上述流程中还需要较为重要的一步,就是在持久化存储之前需 ...
- 05,Python网络爬虫之三种数据解析方式
回顾requests实现数据爬取的流程 指定url 基于requests模块发起请求 获取响应对象中的数据 进行持久化存储 其实,在上述流程中还需要较为重要的一步,就是在持久化存储之前需要进行指定数据 ...
- 《Python网络爬虫之三种数据解析方式》
引入 回顾requests实现数据爬取的流程 指定url 基于requests模块发起请求 获取响应对象中的数据 进行持久化存储 其实,在上述流程中还需要较为重要的一步,就是在持久化存储之前需要进行指 ...
随机推荐
- TF-IDF笔记(直接调用函数、手写)
首先TF-IDF 全称:term frequency–inverse document frequency,是一种用于信息检索与数据挖掘的常用加权技术. TF是词频(Term Frequency),I ...
- XCTF练习题---MISC---就在其中
XCTF练习题---MISC---就在其中 flag:flag{haPPy_Use_0penSsI} 解题步骤: 1.观察题目,下载附件 2.拿到手以后发现是一个数据包格式,直接上Wireshark查 ...
- FreeRTOS --(9)任务管理之启动调度器
转载自 https://blog.csdn.net/zhoutaopower/article/details/107057528 在使用 FreeRTOS 的时候,一般的,先创建若干任务,但此刻任务并 ...
- 浅谈Nginx性能调优
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! Linux系统参数优化 下文中提到的一些配置,需要较新的 ...
- Spring Ioc源码分析系列--Ioc源码入口分析
Spring Ioc源码分析系列--Ioc源码入口分析 本系列文章代码基于Spring Framework 5.2.x 前言 上一篇文章Spring Ioc源码分析系列--Ioc的基础知识准备介绍了I ...
- 零基础学Java第一节(语法格式、数据类型)
本篇文章是<零基础学Java>专栏的第一篇文章,从本篇文章开始,将会连更本专栏,带领大家将Java基础知识彻底学懂,文章采用通俗易懂的文字.图示及代码实战,从零基础开始带大家走上高薪之路! ...
- 使用echo 无法正确清空文件存储大小
在使用echo进行重定向文件的时候,会存在大小没有发生改变的现象 使用上面的方法遇到一个现象 ls -l 与 du -sh 得到的大小事是不同的 可以尝试下面的方面之后在进行对比 再看是否正确清除 使 ...
- arts-week12
Algorithm 69. Sqrt(x) - LeetCode Review Cloudflare goes InterPlanetary - Introducing Cloudflare's IP ...
- dd-文件系统内容映射
复制文件并对原文件的内容进行转换和格式化处理. 语法 dd [OPTIONS]... 选项 if=filename 指定源文件. of=filename 指定目的文件. ibs=bytes 指定一个块 ...
- LC T668笔记 & 有关二分查找、第K小数、BFPRT算法
LC T668笔记 [涉及知识:二分查找.第K小数.BFPRT算法] [以下内容仅为本人在做题学习中的所感所想,本人水平有限目前尚处学习阶段,如有错误及不妥之处还请各位大佬指正,请谅解,谢谢!] !! ...