盘点十大GIS相关算法
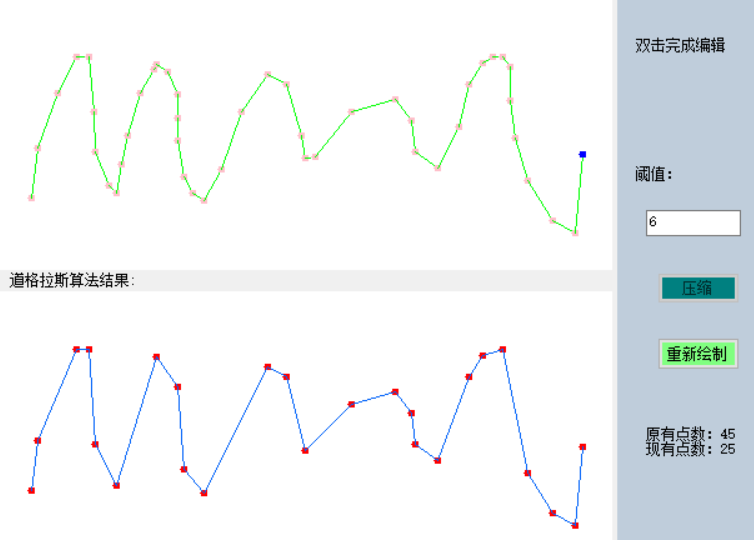
1、道格拉斯-普克算法(Douglas–Peucker)
2、D8单流向算法
ArcGIS水文分析的两个重要的基础,一是使用DEM进行分析,二是分析的基础算法为D8单流向算法。
D8算法是假定雨水降落在地形中某一个格子上,改格子的水流将会流向周围8个格子地形最低的格子中。如果多个像元格子的最大下降方向都相同,则会扩大相邻像元范围,直到找到最陡下降方向为止。如图所示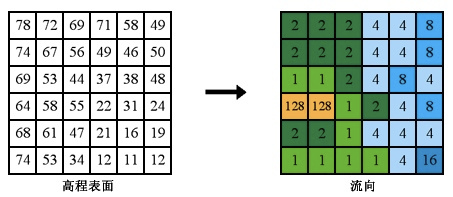
其流向则用2的n次方表示,从0开始,按照逆时针分别为递增,其方位编码如下图所示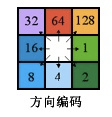
这样编码的好处自然是通过数学的方式,让计算机可以非常快的使用二进制进行索引,加快大区域的流量累计统计。
所以,D8 算法又称作单流向算法。其特点就计算速度快,能够很好的反应出地形对地表径流形成的作用。但其弊端也是显而易见。因为水流只流向一个方向,是单线传递,一旦遇到某一洼地的时候,周边的水流都会集中向该洼地流入,导致断流现象,而现实中由于水会向多个方位不定向的流动,是不会轻易导致断流的。如果要避免这种情况发生,就需要对地形中的洼地进行填平,确保水流也能从该洼地流出。这就是为什么水文分析工具中出现了一些与水文分析完全没有关系的一个工具–填洼 。
从D8算法可以看出,ArcGIS的水文分析工具是依赖无凹陷的DEM地形的,所以在分析之前都必须对DEM数据进行检查。【汇】工具和【填洼】工具就是为了分析前查找和填平洼地而生的,在使用水文分析之前必须要使用这两个工具对DEM进行处理。
单流向算法影响限制了ArcGIS水文分析工具的使用。尤其是地势平坦的地区和人工干预比较多的城市区域,基本上不适用。因为地势平坦导致水流无法沿某一方向流动而形成径流。
另一种情况是事实上的断流形成,如存在地表水流汇流入地下水系的情况。一旦出现流入地下暗河,D8算法就完全失效。因此,在喀斯特地貌中同样也不适用。
D8算法是完全不考虑降雨的多少、土壤渗透率、植被吸水以及水流挡阻等水文过程,它只是假定有无限的降雨并最终汇聚水流形成径流,并通过汇流范围来定义最终的河流。因此,它只是一个径流汇成河流的定性分析(尽管流量计算看起来是有定量因子),并不能通过其流量算法去做水文的预报。


最常用的是D8算法:假设单个栅格中的水流只能流入与之相邻的8 个栅格中。它用最陡坡度法来确定水流的方向,即在3×3 的DEM 栅格上,计算中心栅格与各相邻栅格间的距离权落差(即栅格中心点落差除以栅格中心点之间的距离),取距离权落差最大的栅格为中心栅格的流出栅格。
所谓最陡坡度法的原理是假设地表不透水,降雨均匀.那么流域单元上的水流总是流向最低的地方 “窗口滑动指以计算单元为中心,组合其相邻的若干个单元形成一个窗口”,以“窗口”为计算基本元素,推及整个DEM,求取最终结果。
目前应用最广泛的是基于流向分析和汇流分析的流域特征提取技术。Jenson and Domingue (1988)设计了应用该技术的典型算法,该算法包括3个过程:流向分析,汇流分析和流域特征提取。
流向分析:以数值表示每个单元的流向。数字变化范围是1~255。其中1:东;2:东南;4南;8:西南;16:西;32:西北;64:北;128:东北。除上述数值之外的其它值代表流向不确定,这是由DEM中 洼地”和“平地”现象所造成的。所谓“洼地”即某个单元的高程值小于任何其所有相邻单元的高程。这种现象是由于当河谷的宽度小于单元的宽度时,由于单元的高程值是其所覆盖地区的平均高程,较低的河谷高度拉低了该单元的高程。这种现象往往出现在流域的上游。“平地 指相邻的8个单元具有相同的高程,与测量精度、DEM单元尺寸或该地区地形有关。这两种现象在DEM 中相当普遍,Jenson andDomingue在流向分析之前,将DEM进行填充;将“洼地”变成“平地”,再通过一套复杂的迭代算法确定“平地”流向。
汇流分析:汇流分析的主要目的是确定流路。在流向栅格图的基础上生成汇流栅格图.汇流栅格上每个单元的值代表上游汇流区内流入该单元的栅格点的总数,既汇入该单元的流入路径数(NIP),NIP较大者,可视为河谷,NlP等于0,则是较高的地方,可能为流域s的分水岭。
提取流域特征:有了流域汇流栅格图就可以很方便地提取流域的各种特征参数。例如模拟流域水系,可以设置一个NIP阈值,大于该值的格点为沟谷线上的点,连接各个沟谷线上的点就形成了河网。在汇流矩阵(汇流栅格)上求子流域的方法如下:从河谷单元或孤立的洼单元开始,向上游搜索所有流向该单元的单元,这些单元构成以开始单元为流域出口的子流域。模拟出水系及流域边界后,利用GIS的相关函数,就可以很方便地得到流域的各项特征参数,如河流的长度、坡癣、流域面积等。
详细介绍
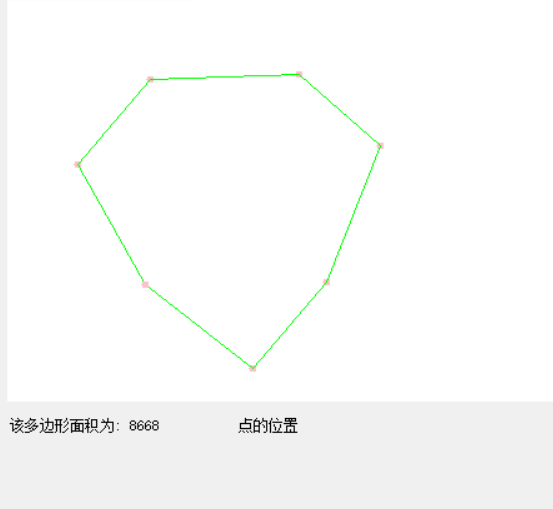
3、不规则多边形面积计算
这个算法的思想就是不停地将多边形,划分成n个三角形,然后计算每个三角形的面积,这个可以用线性代数的知识解决。
大家可以参考这个网址https://blog.csdn.net/lemongirl131/article/details/51130659
无论是凸多边形还是凹多边形都是适用的。
4、点在多边形内外的判断

5、曼哈顿距离算法(Manhattan Distance)
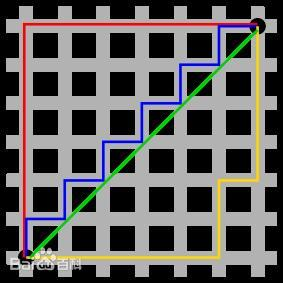
曼哈顿距离算法,简单来讲其实就是根据曼哈顿距离来计算最优路径的算法,是一种启发式的寻路算法,对网络结构的要求是规则。
6、迪杰斯特拉算法(Dijkstra)
迪杰斯特拉算法(Dijkstra)是由荷兰计算机科学家狄克斯特拉于1959 年提出的,因此又叫狄克斯特拉算法。是从一个顶点到其余各顶点的最短路径算法,解决的是有权图中最短路径问题。迪杰斯特拉算法主要特点是从起始点开始,采用贪心算法的策略,每次遍历到始点距离最近且未访问过的顶点的邻接节点,直到扩展到终点为止。
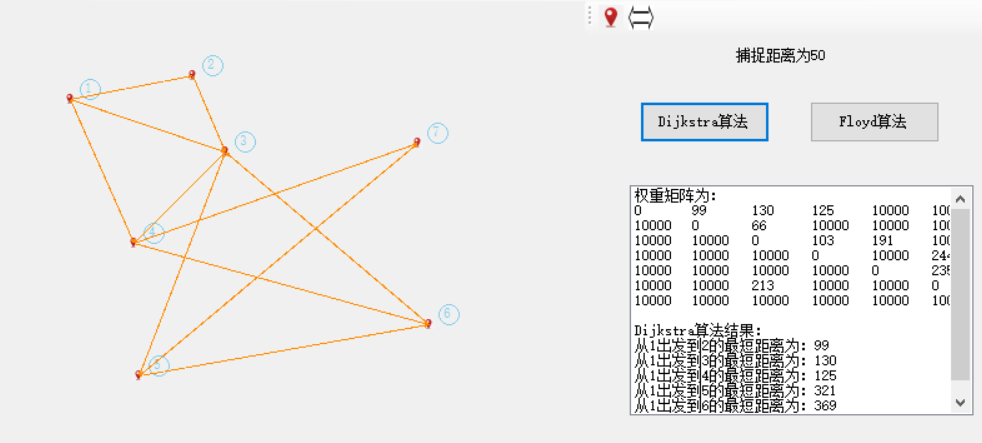
Dijkstra算法,简单讲是一种贪心算法,通关权重矩阵进行计算,利用广度优先算法不停找其相邻点的过程,这个可以参考百度,百度说的很清楚。
7、弗洛伊德算法(Floyd)
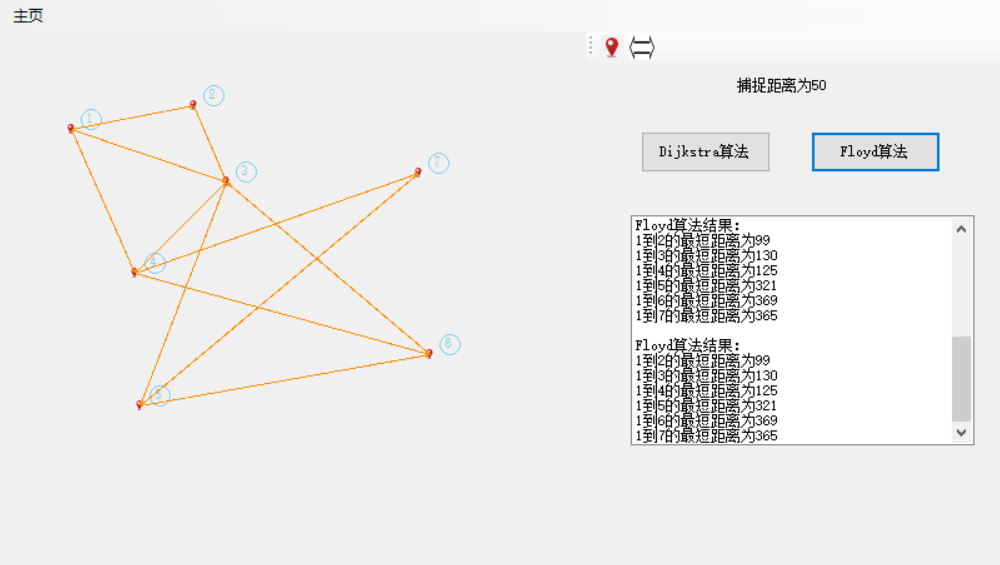
Floyd算法,简单讲就是三层循环遍历,这个也可以参考百度。Dijkstra算法和Floyd算法跟计算机专业联系密切,不仅用于GIS中图的最短路径的研究,在运筹学等多方面应用广泛,博主在前段时间的一个电影较大数据的人物关系查询还曾用到这两个算法,希望读者可以深入了解下。
8、泰森多边形(Voronoi图)
泰森多边形又叫冯洛诺伊图(Voronoi diagram),得名于Georgy Voronoi,是一组由连接两邻点线段的垂直平分线组成的连续多边形组成。一个泰森多边形内的任一点到构成该多边形的控制点的距离小于到其他多边形控制点的距离。泰森多边形是对空间平面的一种剖分,其特点是多边形内的任何位置离该多边形的样点(如居民点)的距离最近,离相邻多边形内样点的距离远,且每个多边形内含且仅包含一个样点。由于泰森多边形在空间剖分上的等分性特征,因此可用于解决最近点、最小封闭圆等问题,以及许多空间分析问题,如邻接、接近度和可达性分析等。

也就是我们常说的Voronoi图,百度讲的也比较清楚。
9、狄洛尼三角网(Delaunay )
这个需要先讲一下TIN,我们常说的TIN就是不规则三角网。
不规则三角网(TIN, Triangulated Irregular Network)模型采用一系列相连接的三角形拟合地表或其他不规则表面,常用来构造数字地面模型,特别是数字高程模型。最常用的生成方法是Delaunay 剖分方法。TIN在表示复杂表面方面具有许多优越性,国面被广就应用于数字制用、地用表面的模型化及分析以及LIS中。
在所有可能的三角网中,狄洛尼(Delaunay)三角网在地形拟合方面运用的较普遍,因此常被用于TIN的生成。在狄洛尼三角网中的每个三角形可视为一个平面,平面的几何特征完全由三个顶点的空间坐标值(x,y,z)所决定。存储的时候,每个三角形分别构成一个记录,每个记录包括:三角形标识码、该三角形的相邻三角形标识码、该三角形的顶点标识码等。顶点的空间坐标值则另外存储。
狄洛尼三角网是在所有可能的三角网中,Delaunay 三角网在离散点均匀分布的情况下能够避免产生有过小锐角的三角形。

Delaunay三角网,全称应该是狄洛尼不规则三角网(Delaunay Triangulated Irregular Network),主要就是应用于TIN的构建,立体模型的生成。
10、分形图

几乎在曼德布罗特获得Barnard奖章的同时,以德国布来梅大学的数学家和计算机专家H.Peotgen与P.Richter等为代表,在当时最先进的计算机图形工作站上制作了大量的分形图案;J. Hubbard等人还完成了一部名为《混沌》的计算机动画。接着,印刷着分形的画册、挂历、明信片、甚至T恤衫纷纷出笼。

观呈现出来,给出其形式化的表达。分形作为一类例证,为数学理论与实践中所蕴涵的美,给出了一类精彩的注记。充分反映了数学科学中的简单、和谐、统一的内涵!

至于算法的重要性,算法是计算机科学领域最重要的基石之一,对于编程者来说,算法是解决问题的一种重要手段,现在不少人陷入了一个误区,认为只有前沿的知识才是最重要的,这使他们在追逐前沿技术时忘记了那些根本的基础的工具,整天赶时髦的人最后只懂得招式,没有功力,是不可能成为高手的。
文中只提到了一些常用的GIS相关的算法,博主会在之后对这些相关算法的源码进行公布,欢迎评论或后台留言!

扫码关注公众号
盘点十大GIS相关算法的更多相关文章
- 【十大经典数据挖掘算法】AdaBoost
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 集成学习 集成学习(ensem ...
- 十大经典排序算法的 JavaScript 实现
计算机领域的都多少掌握一点算法知识,其中排序算法是<数据结构与算法>中最基本的算法之一.排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大 ...
- 【十大经典数据挖掘算法】PageRank
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 我特地把PageRank作为[十大经 ...
- 【十大经典数据挖掘算法】EM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 极大似然 极大似然(Maxim ...
- 【十大经典数据挖掘算法】SVM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART SVM(Support Vector ...
- 【十大经典数据挖掘算法】Naïve Bayes
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 朴素贝叶斯(Naïve Bayes) ...
- 【十大经典数据挖掘算法】C4.5
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 决策树模型与学习 决策树(de ...
- 【十大经典数据挖掘算法】k-means
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 引言 k-means与kNN虽 ...
- 【十大经典数据挖掘算法】Apriori
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 关联分析 关联分析是一类非常有 ...
随机推荐
- 什么是UIImageView
UIKit框架提供了非常多的UI控件,但并不是每一个都很常用,有些控件可能1年内都用不上,有些控件天天用,比如UIButton.UILabel.UIImageView.UITableView等等 UI ...
- 【BZOJ3545】Peaks(Kruskal重构树 主席树)
题目链接 大意 给出有\(N\)个点\(M\)条边的一张图,其中每个点都有一个High值,每条边都有一个Hard值. 再给出\(Q\)个询问:\(v\) \(x\) \(k\) 每次询问查询从点\(v ...
- Redis 源码简洁剖析 12 - 一条命令的处理过程
命令的处理过程 Redis server 和一个客户端建立连接后,会在事件驱动框架中注册可读事件--客户端的命令请求.命令处理对应 4 个阶段: 命令读取:对应 readQueryFromClient ...
- .NET 固定时间窗口算法实现(无锁线程安全)
一.前言 最近有一个生成 APM TraceId 的需求,公司的APM系统的 TraceId 的格式为:APM AgentId+毫秒级时间戳+自增数字,根据此规则生成的 Id 可以保证全局唯一(有 N ...
- Solution Set -「LOCAL」冲刺省选 Round XXIII
\(\mathscr{Summary}\) 有一说一,虽然我炸了,但这场锻炼心态的效果真的好.部分分聊胜于无,区分度一题制胜,可谓针对性强的好题. A 题,相对性签到题.这个建图确实巧妙,多见 ...
- Solution -「UOJ #87」mx 的仙人掌
\(\mathcal{Description}\) Link. 给出含 \(n\) 个结点 \(m\) 条边的仙人掌图.\(q\) 次询问,每次询问给出一个点集 \(S\),求 \(S\) 内 ...
- Solution -「APIO/CTSC 2007」「洛谷 P3620」数据备份
\(\mathcal{Description}\) Link. 给定升序序列 \(\{x_n\}\) 以及整数 \(k\),在 \(\{x_n\}\) 中选出恰 \(k\) 对 \((x_i, ...
- node(s) didn‘t match node selector.
k8s集群中,有pod出现了 Pending ,通过 kubectl describe pod 命令,发现了如下报错 0/4 nodes are available: 1 node(s) had ta ...
- 三、Mybatis多表关联查询应用
一对一查询 实现语句:select * from neworder o, user u where o.uid = u.id 实体Order: 接口: 配置: 测试: 一对多查询 实现语句:selec ...
- 使用SpringBoot整合MybatisPlus出现 : java.lang.IllegalStateException: Unable to find a @SpringBootConfiguration, you need to use @ContextConfiguration or @SpringBootTest(classes=...) with your test
解决方案一: 将测试类的包路径改为和主启动类的一致 解决方法二: 不想改测试类的路径 就在测试类上添加要测试的类的classes