【十大经典数据挖掘算法】k-means
【十大经典数据挖掘算法】系列
1. 引言
k-means与kNN虽然都是以k打头,但却是两类算法——kNN为监督学习中的分类算法,而k-means则是非监督学习中的聚类算法;二者相同之处:均利用近邻信息来标注类别。
聚类是数据挖掘中一种非常重要的学习流派,指将未标注的样本数据中相似的分为同一类,正所谓“物以类聚,人以群分”嘛。k-means是聚类算法中最为简单、高效的,核心思想:由用户指定k个初始质心(initial centroids),以作为聚类的类别(cluster),重复迭代直至算法收敛。
2. 基本算法
在k-means算法中,用质心来表示cluster;且容易证明k-means算法收敛等同于所有质心不再发生变化。基本的k-means算法流程如下:
选取k个初始质心(作为初始cluster);
repeat:
对每个样本点,计算得到距其最近的质心,将其类别标为该质心所对应的cluster;
重新计算k个cluser对应的质心;
until 质心不再发生变化
对于欧式空间的样本数据,以平方误差和(sum of the squared error, SSE)作为聚类的目标函数,同时也可以衡量不同聚类结果好坏的指标:
\]
表示样本点\(x\)到cluster \(C_i\) 的质心 \(c_i\) 距离平方和;最优的聚类结果应使得SSE达到最小值。
下图中给出了一个通过4次迭代聚类3个cluster的例子:

k-means存在缺点:
k-means是局部最优的,容易受到初始质心的影响;比如在下图中,因选择初始质心不恰当而造成次优的聚类结果(SSE较大):
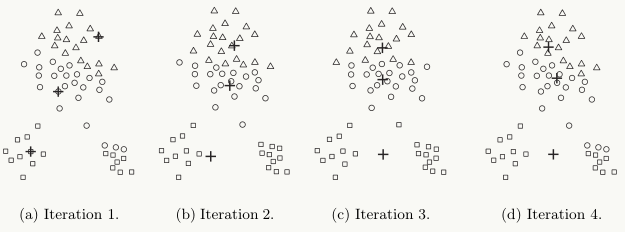
同时,k值的选取也会直接影响聚类结果,最优聚类的k值应与样本数据本身的结构信息相吻合,而这种结构信息是很难去掌握,因此选取最优k值是非常困难的。
3. 优化
为了解决上述存在缺点,在基本k-means的基础上发展而来二分 (bisecting) k-means,其主要思想:一个大cluster进行分裂后可以得到两个小的cluster;为了得到k个cluster,可进行k-1次分裂。算法流程如下:
初始只有一个cluster包含所有样本点;
repeat:
从待分裂的clusters中选择一个进行二元分裂,所选的cluster应使得SSE最小;
until 有k个cluster
上述算法流程中,为从待分裂的clusters中求得局部最优解,可以采取暴力方法:依次对每个待分裂的cluster进行二元分裂(bisect)以求得最优分裂。二分k-means算法聚类过程如图:

从图中,我们观察到:二分k-means算法对初始质心的选择不太敏感,因为初始时只选择一个质心。
4. 参考资料
[1] Pang-Ning Tan, Michael Steinbach, Vipin Kumar, Introduction to Data Mining.
[2] Xindong Wu, Vipin Kumar, The Top Ten Algorithms in Data Mining.
【十大经典数据挖掘算法】k-means的更多相关文章
- 【十大经典数据挖掘算法】k
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 引言 k-means与kNN虽 ...
- 【十大经典数据挖掘算法】PageRank
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 我特地把PageRank作为[十大经 ...
- 【十大经典数据挖掘算法】SVM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART SVM(Support Vector ...
- 【十大经典数据挖掘算法】Naïve Bayes
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 朴素贝叶斯(Naïve Bayes) ...
- 【十大经典数据挖掘算法】C4.5
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 决策树模型与学习 决策树(de ...
- 【十大经典数据挖掘算法】Apriori
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 关联分析 关联分析是一类非常有 ...
- 【十大经典数据挖掘算法】kNN
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 引言 顶级数据挖掘会议ICDM ...
- 【十大经典数据挖掘算法】CART
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 前言 分类与回归树(Class ...
- 【十大经典数据挖掘算法】EM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 极大似然 极大似然(Maxim ...
随机推荐
- mysql之触发器trigger
触发器(trigger):监视某种情况,并触发某种操作. 触发器创建语法四要素:1.监视地点(table) 2.监视事件(insert/update/delete) 3.触发时间(after/befo ...
- winform设置文本框宽度 根据文字数量和字体返回宽度
_LinkLabel.Width = TextRenderer.MeasureText(_LinkLabel.Text, _LinkLabel.Font).Width;
- SQL Server通过File Header Page来进行Crash Recovery
SQL Server通过File Header Page来进行Crash Recovery 看了盖总的一篇文章 http://www.eygle.com/archives/2008/11/oracle ...
- Mac下设置Android源代码编译环境
在Mac下编译Android最麻烦的就是设置Android的编译环境了,做完这一步基本上剩下的就是近乎傻瓜式的操作了.说起来也简单就三步,设置大小写敏感的文件系统.安装编译工具.设置文件系统同时能打开 ...
- 七天学会ASP.NET MVC(七)——创建单页应用
系列文章 七天学会ASP.NET MVC (一)——深入理解ASP.NET MVC 七天学会ASP.NET MVC (二)——ASP.NET MVC 数据传递 七天学会ASP.NET MVC (三)— ...
- spring事务管理器设计思想(一)
在最近做的一个项目里面,涉及到多数据源的操作,比较特殊的是,这多个数据库的表结构完全相同,由于我们使用的ibatis框架作为持久化层,为了防止每一个数据源都配置一套规则,所以重新实现了数据源,根据线程 ...
- eclipse下打包实践
前提: 配置好打包相关的插件,看打包的结果分别添加不同的plugin,装好m2eclipse. 以下步骤以war包的packing为例. 步骤: 如下图:右键,选择Run As 或者 Debug As ...
- css+div常用属性备忘录
学习软件设计有一年多了,明年五月就要毕业了.回头看看发现自己其实挺差劲的. 最近开通了博客所以就整理了一下笔记,在这里发布一下自己以前学习css时总是记不住去翻书又很常用的属性,都是一些很基础的. 大 ...
- Nginx重写
一.location匹配 1.分类:(1)正则location:~,~*(2)普通location:=,^~,@,无2.匹配规则:(1) = 精确匹配.如果找到,停止搜索(2) ^~ 普通 ...
- CentOS7安装mysql提示“No package mysql-server available.”
针对centos7安装mysql,提示"No package mysql-server available."错误,解决方法如下: Centos 7 comes with Mari ...