Fluentd直接传输日志给kafka
官方文档地址:https://docs.fluentd.org/output/kafka
td-agent版本自带包含out_kafka2插件,不用再安装了,可以直接使用。
若是使用的是Fluentd,则需要安装这个插件:
$ fluent-gem install fluent-plugin-kafka
配置示例
<match pattern>
@type kafka2
# list of seed brokers
brokers <broker1_host>:<broker1_port>,<broker2_host>:<broker2_port>
use_event_time true
# buffer settings
<buffer topic>
@type file
path /var/log/td-agent/buffer/td
flush_interval 3s
</buffer>
# data type settings
<format>
@type json
</format>
# topic settings
topic_key topic
default_topic messages
# producer settings
required_acks -1
compression_codec gzip
</match>
参数说明
- @type:必填,kafka2
- brokers:kafka连接地址,默认是localhost:9092
- topic_key:目标主题的字段名,默认是topic,必须设置buffer chunk key,示例如下:
topic_key category
<buffer category> # topic_key should be included in buffer chunk key
# ...
</buffer>
- default_topic:要写入目标的topic,默认nil,topic_key未设置的话则使用这个参数
- 指令,可用参数有json, ltsv和其他格式化程序插件,用法如下:
<format>
@type json
</format>
- use_event_time:fluentd事件发送到kafka的时间,默认false,也就是当前时间
- required_acks:每个请求所需的ACK数,默认-1
- compression_codec: 生产者用来压缩消息的编解码器,默认nil,可选参数有gzip, snappy(如果使用snappy,需要使用命令td-agent-gem安装snappy)
- @log_level:可选,日志等级,参数有fatal, error, warn, info, debug, trace
用法示例
kafka安装参考:https://www.cnblogs.com/sanduzxcvbnm/p/13932933.html
<source>
@type tail
@id input_tail
<parse>
@type nginx
</parse>
path /usr/local/openresty/nginx/logs/host.access.log
tag td.nginx.access
</source>
<match td.nginx.access>
@type kafka2
brokers 192.168.0.253:9092
use_event_time true
<buffer app>
@type memory
</buffer>
<format>
@type json
</format>
topic_key app
default_topic messagesb # 注意,kafka中消费使用的是这个topic
required_acks -1
compression_codec gzip
</match>
kafka消费的数据显示:
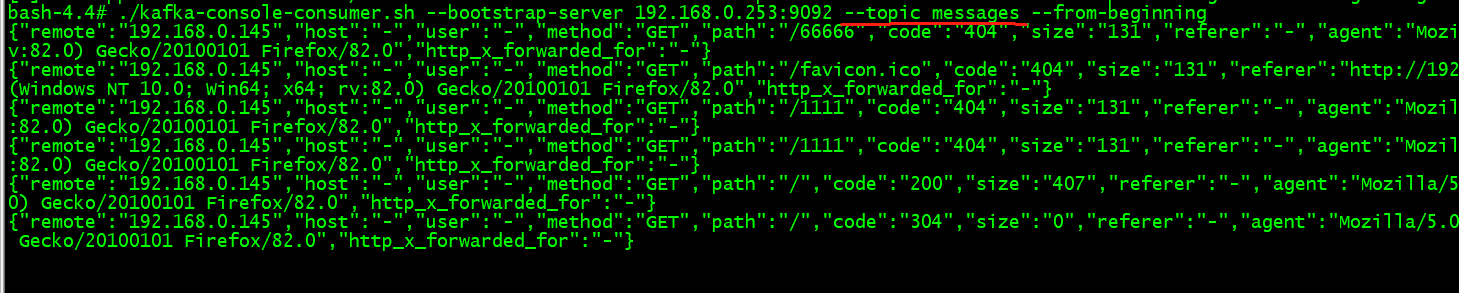
{"remote":"192.168.0.145","host":"-","user":"-","method":"GET","path":"/00000","code":"404","size":"131","referer":"-","agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0","http_x_forwarded_for":"-"}
{"remote":"192.168.0.145","host":"-","user":"-","method":"GET","path":"/99999","code":"404","size":"131","referer":"-","agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0","http_x_forwarded_for":"-"}
Fluentd直接传输日志给kafka的更多相关文章
- Fluentd直接传输日志给Elasticsearch
官方文档地址:https://docs.fluentd.org/output/elasticsearch td-agent的v3.0.1版本以后自带包含out_elasticsearch插件,不用再安 ...
- Fluentd直接传输日志给MongoDB副本集 (replset)
官方文档地址:https://docs.fluentd.org/output/mongo_replset td-agent版本默认没有包含out_mongo插件,需要安装这个插件才能使用 使用的是td ...
- Fluentd直接传输日志给MongoDB (standalone)
官方文档地址:https://docs.fluentd.org/output/mongo td-agent版本默认没有包含out_mongo插件,需要安装这个插件才能使用 使用的是td-agent,安 ...
- 一次flume exec source采集日志到kafka因为单条日志数据非常大同步失败的踩坑带来的思考
本次遇到的问题描述,日志采集同步时,当单条日志(日志文件中一行日志)超过2M大小,数据无法采集同步到kafka,分析后,共踩到如下几个坑.1.flume采集时,通过shell+EXEC(tail -F ...
- 记一次logback传输日志到logstash根据自定义设置动态创建ElasticSearch索引
先说背景,由于本人工作需要创建很多小应用程序,而且在微服务的大环境下,服务越来越多,然后就导致日志四分五裂,到处都有,然后就有的elk,那么问题来了 不能每个小应用都配置一个 logstash 服务来 ...
- 日志打入kafka改造历程-我们到底能走多远系列49
方案 日志收集的方案有很多,包括各种日志过滤清洗,分析,统计,而且看起来都很高大上.本文只描述一个打入kafka的功能. 流程:app->kafka->logstash->es-&g ...
- ELK系列~Fluentd对大日志的处理过程~16K
Fluentd是一个日志收集工具,有输入端和输出端的概念,前者主要是日志的来源,你可以走多种来源方式,http,forward,tcp都可以,后者输出端主要指把日志进行持久化的过程,你可以直接把它持久 ...
- 日志=>flume=>kafka=>spark streaming=>hbase
日志=>flume=>kafka=>spark streaming=>hbase 日志部分 #coding=UTF-8 import random import time ur ...
- 9. Fluentd部署:日志
Fluentd是用来处理其他系统产生的日志的,它本身也会产生一些运行时日志.Fluentd包含两个日志层:全局日志和插件级日志.每个层次的日志都可以进行单独配置. 日志级别 Fluentd的日志包含6 ...
随机推荐
- 2022-07-15/16 第一小组 田龙月 管理系统javaSE
JavaSE小项目(基础语法:二分查找:冒泡排序)--还是存在bug:删除一个数组内一组数据后面只有一组后面数据能向前移位 (YY:使用"方法"应该会好很多,代码架构会清晰一点)未 ...
- 或许是 WebGIS 下一代的数据规范 - OGC API 系列
目录 1. 前言 1.1. 经典的 OGC 标准回顾 1.2. 共同特点与时代变化 1.3. 免责声明 2. 什么是 OGC API 2.1. OGC API 是一个开放.动态的规范族 2.2. OG ...
- 如何做出一个好的c++游戏
目录 一.游戏分类 1.文字型 2.画图型 3.键盘型 二.游戏创意 你的程序可以比较激情.热血 1.打怪,爆装备型 2.答题闯关型 可以添加一些不可思议的物品和玩法 三.学号c++/c的语法,是成功 ...
- python中print函数
python中的输出函数 注意不是C中的printf 起作用就是将希望输出的内容输出在IDLE或标准的控制台上 python解释器将代码翻译成及其能听懂的语言,从而实现代码的实现 print的输出内容 ...
- 2022-7-25 第七组 pan小堂 多态
多态 多态是继封装.继承之后,面向对象的第三大特性. 现实事物经常会体现出多种形态,如学生,学生是人的一种,则一个具体的同学张三既是学生也是人,即出现两种形态. Java作为面向对象的语言,同样可以描 ...
- 在docker中出现的僵尸进程怎么处理
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 一.发现问题 小玲是一名数据库测试人员,这一天她尝试在docker环境中部署GreatDB集群,结果在对greatsqld ...
- CSP-J2021 题解
分糖果 题意 选择L~R中的某个数 , 使得x mod k的结果最大. 思路 分两种情况考虑: 若 L 和 R 对 K 取模后在同一区间,则必然在 x=R 位置取到最大值: 否则 L~R 必然跨越多个 ...
- Luogu2783 有机化学之神偶尔会做作弊 (树链剖分,缩点)
当联通块size<=2时不管 #include <iostream> #include <cstdio> #include <cstring> #includ ...
- Linux 02 基本命令
参考源 https://www.bilibili.com/video/BV187411y7hF?spm_id_from=333.999.0.0 版本 本文章基于 CentOS 7.6 工具 清屏 cl ...
- Dynamic CRM一对多关系的数据删除时设置自动删除关联的数据
在业务实体中主子表非常常见,然后子表可能有会有自己的子表或者多对多关系,在删除的业务场景下,删除主数据,剩余的子数据就成了脏数据, 之前的做法是,监听主表的删除事件,然后在插件中找到其下的子表数据然后 ...