Flask之model以及缓存
Flask默认并没有提供任何数据库操作的API。
Flask中可以自己的选择数据,用原生语句实现功能,也可以选择ORM(SQLAlchemy,MongoEngine)
原生SQL缺点
代码利用率低,条件复杂代码语句越长,有很多相似语句
一些SQL是在业务逻辑中拼出来的,修改需要了解业务逻辑
直接写SQL容易忽视SQL问题。
一、orm
将对对象的操作转换为原生SQL
1、优点
易用性,可以有效减少重复SQL,性能损耗少设计灵活,可以轻松实现复杂查询,移植性好
Python中的orm是SQLAlchemy
针对于Flask的支持
pip install flask-sqlalchemy
2、连接数据库
dialect+driver://username:password@host:port/database
dialect数据库实现
driver数据库的驱动
username
password
host
port
database
连接数据库需要指定配置
app.config[‘SQLALCHEMY_DATABASE_URI’] = DB_URI
app.config[‘SQLALCHEMY_TRAKE_MODIFICATIONS’]=False
3、创建模型
class User(db.Model):
__tablename__ = "UserModel" # 指定表名,默认是类名 id = db.Column(db.Integer, primary_key=True, autoincrement=True) u_name = db.Column(db.String(16), unique=True) u_des = db.Column(db.String(128), nullable=True)
(1)、字段类型
Integer
SmallInteger
BigInteger
Float
Numeric
String
Text
Unicode
Unicode Text
Boolean
Date
Time
DateTime
Interval
LargeBinary
(2)、常见约束
primary_key
autoincrement
unique
index
nullable
default
ForeignKey()
(3)、数据操作
db.create_all() 创建数据库
db.drop_all() 删除数据库
①、数据插入
数据插入是在事务中处理
db.session.add(object)
db.session.add_all(list[object])
db.session.commit()
@api.route('/adduser/')
def adduser():
users = []
for i in range(5):
user = User()
user.u_name = "小花%d" % random.randrange(10000)
users.append(user)
db.session.add_all(users)
db.session.commit()
return 'Add success'
②、数据删除
db.session.delete(object)
db.session.commit()
修改和删除基于查询。
(4)、模型继承
默认继承并不会报错,它会将多个模型的数据映射到一张表中,导致数据混乱,不能满足基本使用
抽象的模型是不会在数据库中产生映射的
class Animal(db.Model):
__abstract__ = True
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
a_name = db.Column(db.String(16)) class Dog(Animal):
d_legs = db.Column(db.Integer, default=4) class Cat(Animal): c_eat = db.Column(db.String(32), default='fish')
(5)、模型迁移
python manager.py db init #初次迁移,生成migration包
python manager.py db migrate # 创建迁移
python manager.py db upgrade # 更新
(6)、数据查询
①、查询单个对象
first
get
get_or_404
@api.route('/getuser/<int:id>/')
def get_user(id):
user = User.query.get(id)
print(user)
return 'GET success'
②、查询结果集
all:比较特殊,返回列表
@api.route('/getusers/')
def get_users():
users = User.query.all()
for user in users:
print(user.u_name)
return 'get success'
filter:BaseQuery对象
运算符:
contains
startswith
endswith
in_
like
__gt__
__ge__
__lt__
__le__
条件:
- 类名.属性名.魔术方法(临界值)
@api.route('/getdog/')
def getdog():
dogs = Dog.query.filter(Dog.id.__le__(5))
for dog in dogs:
print(dog.id, dog.a_name)
return 'GET SUCCESS'
- 类名.属性名 操作符运算符 临界值
@api.route('/getdog/')
def getdog():
dogs = Dog.query.filter(Dog.id > 5)
for dog in dogs:
print(dog.id, dog.a_name)
return 'GET SUCCESS'
@api.route('/getdog/')
def getdog():
dogs = Dog.query.filter(Dog.a_name.contains("2"))
for dog in dogs:
print(dog.id, dog.a_name)
return 'GET SUCCESS'
offset和limit不区分顺序,都是先执行offset
@api.route('/getdog/')
def getdog():
dogs = Dog.query.offset(5).limit(4)
for dog in dogs:
print(dog.id, dog.a_name)
return 'GET SUCCESS'
- order_by 调用必须在 offset和limit 之前
使用offset以及limit实现分页
@api.route('/getdogs/')
def get_dogs():
page = request.args.get("page", 1, type=int)
per_page = request.args.get('per_page', 4, type=int)
dogs = Dog.query.offset(per_page * (page - 1)).limit(per_page)
return render_template('Dogs.html', dogs=dogs)
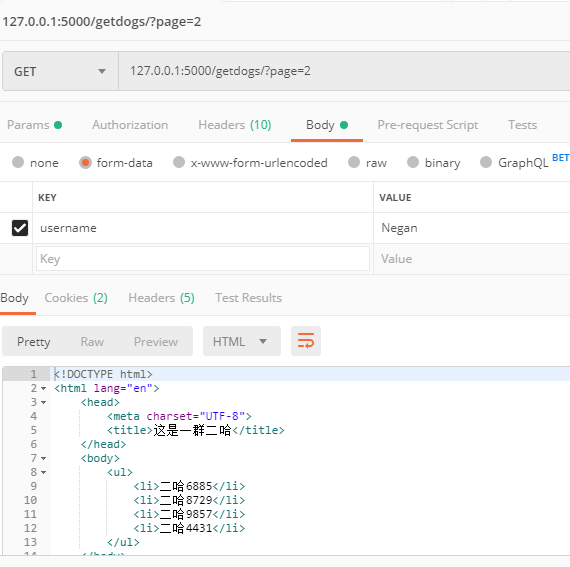
paginate实现分页
@api.route('/getdogs/')
def get_dogs_with_page():
# dogs = Dog.query.paginate().items
pagination = Dog.query.paginate()
per_page = request.args.get('per_page', 4, type=int)
return render_template('Dogs.html', pagination=pagination, per_page=per_page)
<div class=pagination>
{% for page in pagination.iter_pages(left_edge=5,left_current=5,right_current=5,right_edge=5) %}
{% if page %}
{% if page != pagination.page %}
<a href="{{ url_for('api.get_dogs_with_page') }}?page={{ page }}&per_page={{ per_page }}">{{ page }}</a>
{% else %}
<strong>{{ page }}</strong>
{% endif %}
{% else %}
<span class=ellipsis>…</span>
{% endif %}
{% endfor %}
</div>

filter_by
用在级联数据上,条件语法精准,字段 = 值
@blue.route('/getcatsfilterby/')
def get_cats_filter_by():
cats = Cat.query.filter_by(id = 5)
return render_template('Cats.html', cats=cats)
(7)级联数据
class Customer(db.Model):
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
c_name = db.Column(db.String(16))
addresses = db.relationship('Address', backref='customer', lazy=True) class Address(db.Model):
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
a_position = db.Column(db.String(128))
a_customer_id = db.Column(db.Integer, db.ForeignKey(Customer.id))

①添加数据
@api.route('/getcustomer/')
def get():
customer = Customer.query.order_by(desc('id')).first()
return str(customer.id)
@api.route('/addaddress/')
def add_address():
address = Address()
address.a_position = '秀水街 %s' % random.randrange(10000)
address.a_customer_id = Customer.query.order_by(desc('id')).first().id # 注意此处使用id的倒叙,不能直接用‘-id’
db.session.add(address)
db.session.commit()
return 'Address Add Success %s' % address.a_position

②查询数据
根据地址找到对应的人
@api.route('/getcustomer/')
def get():
a_id = request.args.get('a_id', type=int)
address = Address.query.get(a_id)
customer = Customer.query.get(address.a_customer_id) #维护关系表中的外键存的是不维护关系表中的主键,
return customer.c_name
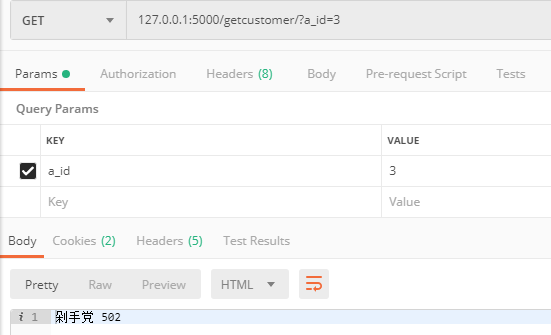
根据人找到对应的地址
@api.route('/getaddress/')
def get_address():
c_id = request.args.get('c_id')
customer = Customer.query.get(c_id)
# addresses = Address.query.filter_by(a_customer_id=customer.id)
addresses = customer.addresses
return render_template('address.html', addresses=addresses)
<ul>
{% for address in addresses %}
<li>{{ address.a_position }}</li>
{% endfor %} </ul>
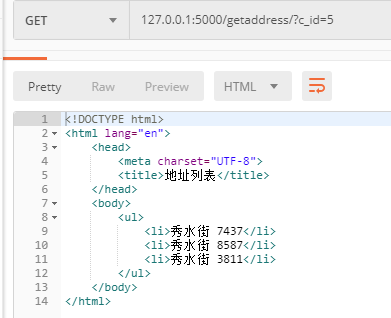
③逻辑运算
filter多个条件
@api.route('/getaddress/')
def get_address():
addresses = Address.query.filter(Address.a_customer_id.__eq__(1)).filter(Address.a_position.endswith('4'))
return render_template('address.html', addresses=addresses)
与 and
filter(and_(条件),条件…)
@api.route('/getaddress/')
def get_address():
addresses = Address.query.filter(and_(Address.a_customer_id.__eq__(1),Address.a_position.endswith('4')))
return render_template('address.html', addresses=addresses)
Django中可以将字段直接写在filter中,无需使用and_
或
or_
filter(or_(条件),条件…)
非
not_
filter(not_(条件),条件…)
@api.route('/getaddress/')
def get_address():
addresses = Address.query.filter(not_(or_(Address.a_customer_id.__eq__(1), Address.a_position.endswith('4'))))
return render_template('address.html', addresses=addresses)
二、缓存
pip install Flask-Caching
在ext.py中进行配置
from flask_caching import Cache
from flask_migrate import Migrate
from flask_session import Session
from flask_sqlalchemy import SQLAlchemy db = SQLAlchemy()
migrate = Migrate()
cache = Cache(config={
"CACHE_TYPE": "redis" # 默认是连接本地,可以设置远程。
})
# cache=Cache() # 配置可以写在settings中的Config类中 def init_ext(app):
db.init_app(app)
migrate.init_app(app, db)
Session(app)
cache.init_app(app)
在视图中使用
@api.route('/getaddress/')
@cache.cached(timeout=60)
def get_address():
addresses = Address.query.filter(not_(or_(Address.a_customer_id.__eq__(1), Address.a_position.endswith('4'))))
print('数据库中获取')
return render_template('address.html', addresses=addresses)
Flask之model以及缓存的更多相关文章
- flask 之(四) --- 扩展|缓存|会话
扩展 蓝图内置扩展 (实现的是路由的拆分) '''----------- app.py -------------''' from flask import Flask from users_view ...
- Flask SQLAlchemy & model
Flask-SQLAlchemy Flask-SQLAlchemy库让flask更方便的使用SQLALchemy,是一个强大的关系形数据库框架,既可以使用orm方式操作数据库,也可以使用原始的SQL命 ...
- AngularJS中实现Model缓存
在AngularJS中如何实现一个Model的缓存呢? 可以通过在Provider中返回一个构造函数,并在构造函数中设计一个缓存字段,在本篇末尾将引出这种做法. 一般来说,Model要赋值给Scope ...
- 欢迎来到 Flask 的世界
欢迎来到 Flask 的世界 欢迎阅读 Flask 的文档.本文档分成几个部分,我推荐您先读 < 安装 >,然后读< 快速上手 >.< 教程 > 比快速上手文档更详 ...
- .NET/ASP.NETMVC 大型站点架构设计—迁移Model元数据设置项(自定义元数据提供程序)
阅读目录: 1.需求背景介绍(Model元数据设置项应该与View绑定而非ViewModel) 1.1.确定问题域范围(可以使用DSL管理问题域前提是锁定领域模型) 2.迁移ViewModel设置到外 ...
- SSH整合配置二级缓存
一.了解 Hibernate的session提供了一级缓存,每个session,对同一个id进行两次load,不会发送两条sql给数据库,但session关闭时,一级缓存失效. 二级缓存是Sessio ...
- 迁移Model元数据设置项
.NET/ASP.NETMVC 大型站点架构设计—迁移Model元数据设置项(自定义元数据提供程序) 阅读目录: 1.需求背景介绍(Model元数据设置项应该与View绑定而非ViewModel) 1 ...
- iOS架构设计-URL缓存
概览 缓存组件应该说是每个客户端程序必备的核心组件,试想对于每个界面的访问都必须重新请求势必降低用户体验.但是如何处理客户端缓存貌似并没有统一的解决方案,多数开发者选择自行创建数据库直接将服务器端请求 ...
- Springboot Mybatis Redis 实现二级缓存
前言 什么是mybatis二级缓存? 二级缓存是多个sqlsession共享的,其作用域是mapper的同一个namespace. 即,在不同的sqlsession中,相同的namespace下,相同 ...
- springboot mybatis redis 二级缓存
前言 什么是mybatis二级缓存? 二级缓存是多个sqlsession共享的,其作用域是mapper的同一个namespace. 即,在不同的sqlsession中,相同的namespace下,相同 ...
随机推荐
- Windows 提权-内核利用_2
本文通过 Google 翻译 Kernel Exploits Part 2 – Windows Privilege Escalation 这篇文章所产生,本人仅是对机器翻译中部分表达别扭的字词进行了校 ...
- Vue2框架-基础
1. vue简介 什么是vue? Vue是一套用于构建用户界面的渐进式JavaScript框架.与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用.Vue 的核心库只关注视图层,方便与第三方 ...
- Xshell连接有跳板机(堡垒机)的服务器
一.Xshell直连有跳板机的服务器 跳板机IP:112.74.163.161 端口号: 22 服务器IP:47.244.217.66 端口号:22 1. 新建跳板机会话 点击连接,主机和端口 ...
- laradock 更改 mysql 版本
# 修改 .env 文件 MYSQL_VERSION=5.7 # 默认为 latest #停止mysql容器 docker-compose stop mysql # 删除旧数据库数据 rm -rf ~ ...
- 实现领域驱动设计 - 使用ABP框架 - 领域逻辑 & 应用逻辑
领域逻辑 & 应用逻辑 如前所述,领域驱动设计中的业务逻辑分为两部分(层):领域逻辑和应用逻辑: 领域逻辑由系统的核心领域规则组成,应用逻辑实现应用特定的用例 虽然定义很明确,但实现起来可能并 ...
- [源码系列:手写spring] IOC第十四节:容器事件和事件监听器
代码分支 https://github.com/yihuiaa/little-spring/tree/event-and-event-listenerhttps://github.com/yihuia ...
- [每日算法 - 华为机试] leetcode172. 阶乘后的零
入口 力扣https://leetcode.cn/problems/factorial-trailing-zeroes/ 题目描述 给定一个整数 n ,返回 n! 结果中尾随零的数量. 提示 n! = ...
- SQL 和 PL/SQL 的区别
不经意看到2个ORA错误,一个提示PL/SQL ORA-错误,另一个提示SQL ORA-错误,好奇这2货啥区别?留爪. PL/SQL也是一种程序语言,叫做过程化SQL语言(Procedural Lan ...
- nodejs新进程子进程
获取进程相关的基本信息 #!/bin/env node console.log (process.execPath) console.log (process.cwd()) console.log ( ...
- java基础之接口、多态
一.接口:是Java语言中一种引用类型[组数.类也是引用类型],内部主要就是封装了方法, 包括(抽象方法.默认方法.静态方法.私有方法) 格式: public interface 接口名称 { // ...