075 importSTV的使用,与bulkload的使用
一:由HDFS将数据直接导入到HBase中
1.生成TSV文件
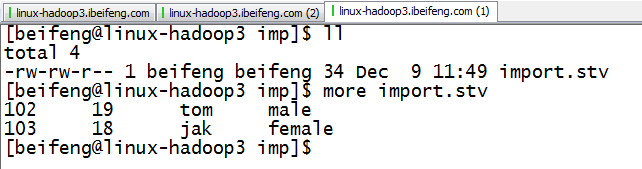
2.内容

3.上传到HDFS

4.运行
export HBASE_HOME=/etc/opt/modules/hbase-0.98.6-hadoop2
export HADOOP_CLASSPATH=`$HBASE_HOME/bin/hbase mapredcp`
export HADOOP_HOME=/etc/opt/modules/hadoop-2.5.0
$HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:age,info:name,info:sex nstest1:tb1 /imp/import.tsv
重要的是:
)HBASE_ROW_KEY
)info:name,等都要和import.tsv相对应
)目录是HDFS的目录
)表名是将要书写进去的表名
5.结果

二:将数据转换为HFile
1.将数据转为HFile
hbase-0.98.6-hadoop2]$ $HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar importtsv -Dimporttsv.bulk.output=/impout -Dimporttsv.columns=HBASE_ROW_KEY,info:age,info:name,info:sex nstest1:tb2 /imp/import.tsv
其中:nstest1:tb2的作用是按照这个表的格式进行转换HFile
/impout 是HFile的路径。

2.将HFile保存进HBase
$HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar completebulkload /impout nstest1:tb2
3.结果
HDFS中的HFile数据不再存在

HBase的结果

三:自定义分隔符
1.新定义文件

2.删除以前的文件,再重新上传文件
3.运行
$HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar importtsv -Dimporttsv.separator=,
-Dimporttsv.columns=HBASE_ROW_KEY,info:age,info:name,info:sex nstest1:tb2 /imp/import.tsv
3.结果

075 importSTV的使用,与bulkload的使用的更多相关文章
- 使用bulkload向hbase中批量写入数据
1.数据样式 写入之前,需要整理以下数据的格式,之后将数据保存到hdfs中,本例使用的样式如下(用tab分开): row1 N row2 M row3 B row4 V row5 N row6 M r ...
- 【hbase】——HBase 写优化之 BulkLoad 实现数据快速入库
1.为何要 BulkLoad 导入?传统的 HTableOutputFormat 写 HBase 有什么问题? 我们先看下 HBase 的写流程: 通常 MapReduce 在写HBase时使用的是 ...
- 通过BulkLoad的方式快速导入海量数据
摘要 加载数据到HBase的方式有多种,通过HBase API导入或命令行导入或使用第三方(如sqoop)来导入或使用MR来批量导入(耗费磁盘I/O,容易在导入的过程使节点宕机),但是这些方式不是慢就 ...
- bulk-load 装载HDFS数据到HBase
bulk-load的作用是用mapreduce的方式将hdfs上的文件装载到hbase中,对于海量数据装载入hbase非常有用,参考http://hbase.apache.org/docs/r0.89 ...
- HBase BulkLoad批量写入数据实战
1.概述 在进行数据传输中,批量加载数据到HBase集群有多种方式,比如通过HBase API进行批量写入数据.使用Sqoop工具批量导数到HBase集群.使用MapReduce批量导入等.这些方式, ...
- 通过BulkLoad快速将海量数据导入到Hbase
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据.我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等. 但是这些方式不是慢就是在导入的过程的占用Region ...
- spark批量写写数据到Hbase中(bulkload方式)
1:为什么大批量数据集写入Hbase中,需要使用bulkload BulkLoad不会写WAL,也不会产生flush以及split. 如果我们大量调用PUT接口插入数据,可能会导致大量的GC操作.除了 ...
- 在Spark上通过BulkLoad快速将海量数据导入到Hbase
我们在<通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]>文中介绍了一种快速将海量数据导入Hbase的一种方法,而本文将介绍如何在Spark上使用Scala编写快速导入 ...
- [How to] HBase的bulkload使用方法
1.简介 将数据插入HBase表中的方法很多,我们可以通过TableOutputFormat以Mapreduce on HBase的方式将数据插入,也可以单纯的使用客户端API将数据插入.但是以上方法 ...
随机推荐
- Postfix 邮件服务 - 基础服务
环境 centos 6.5 x64 测试 IP:172.16.2.18 1.关闭selinux # cat /etc/selinux/config SELINUX=disabled 2.配置 ipta ...
- centos7 网卡命名
CentOS6 及之前以太网网卡进行顺序命名的:多网卡如:eth0,eth1 依次.Centos7 则不同,命名规则默认是基于固件.拓扑.位置信息来分配.一.网卡命名的策略systemd对网络设备的命 ...
- luogu P2502 [HAOI2006]旅行
传送门 边数只有5000,可以考虑\(O(m^2)\)算法,即把所有边按边权升序排序,然后依次枚举每条边\(i\),从这条边开始依次加边,加到起点和终点在一个连通块为止.这个过程可以用并查集维护.那么 ...
- luogu P4160 [SCOI2009]生日快乐
传送门 考虑因为每个人的蛋糕体积要相等,如果切了一刀,那么要使得分当前蛋糕的人根据分成的两部分蛋糕的体积分成两部分人,所以假设当前有n人,切的这一刀要是在x或y的\(\frac{k}{n}(k\in ...
- The folder can’t be opened because you don’t have permission to see its contents.
1 自己在windows上面copy过去的文件夹,在Mac下面无法查看 一开始以为是windows文件的权限问题,然后 自己赋予了everyone所有的权限,结果在Mac上面还是无法打开文件夹 2 最 ...
- Maxwell入门
1 下载tar包 Download binary distro: https://github.com/zendesk/maxwell/releases/download/v1.19.4/maxwel ...
- Hive配置永久显示表字段名并且不显示表名
1 配置文件 hive/conf下hive-site.xml /mnt/software/hive-1.1.0-cdh5.7.0/conf 2 添加配置项 <!--不显示表名--> < ...
- linux查看防火墙的状态以及开启关闭
存在以下两种方式: 一.service方式 查看防火墙状态: [root@centos6 ~]# service iptables status 开启防火墙: [root@centos6 ~]# se ...
- RunLoop 原理和核心机制
搞iOS之后一直没有深入研究过RunLoop,非常的惭愧.刚好前一阵子负责性能优化项目,需要利用RunLoop做性能优化和性能检测,趁着这个机会深入研究了RunLoop的原理和特性. RunLoop的 ...
- 2017-2018-2 20155303『网络对抗技术』Exp7:网络欺诈防范
2017-2018-2 『网络对抗技术』Exp7:网络欺诈防范 --------CONTENTS-------- 一.原理与实践说明 1.实践目标 2.实践内容概述 3.基础问题回答 二.实践过程记录 ...