python爬虫训练——正则表达式+BeautifulSoup爬图片
这次练习爬 传送门 这贴吧里的美食图片。
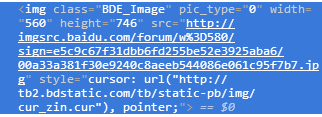
如果通过img标签和class属性的话,用BeautifulSoup能很简单的解决,但是这次用一下正则表达式,我这也是参考了该博主的博文:传送门
所有图片的src地址前面都是相同的,所以根据这个就可以筛选出我们想要的图片了。也就是在匹配时不用class属性的值,而是用正则表达式去匹配src的值。
from urllib import request
from bs4 import BeautifulSoup
import re def get_page(url, tot_page):
url_list = []
for i in range(1,tot_page):
new_url = re.sub(('=(.*)'),'%s%s' %('=',i), url)
url_list.append(new_url)
return url_list if __name__ == '__main__':
url = 'http://tieba.baidu.com/p/4792769205?pn=1'
path = 'D:\python\project\爬虫结果'
count = 0
url_list = get_page(url, 4)
for url in url_list:
print(url)
page = request.urlopen(url).read().decode()
soup = BeautifulSoup(page, 'lxml')
regex = re.compile("http://imgsrc.baidu.com/forum/w%3D580/sign=.+\.jpg")
pic_list = soup.findAll('img', {'src': regex})
for pic in pic_list:
pic = pic['src']
request.urlretrieve(pic, '%s/%s.jpg' % (path, count))
count += 1
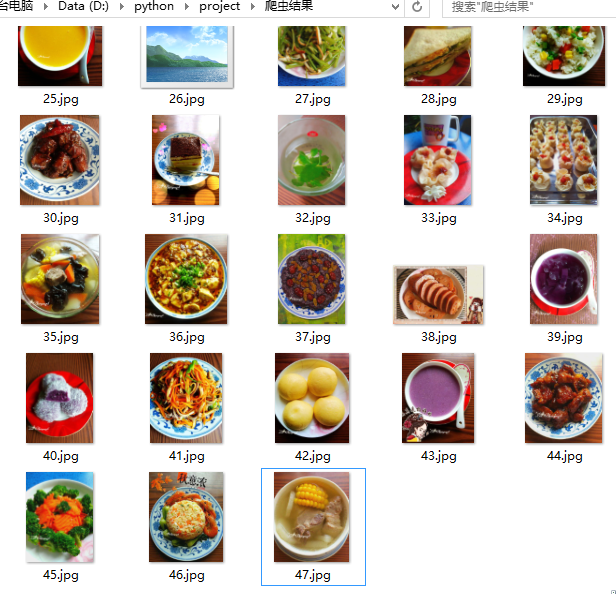
我就爬了3页的图片:
python爬虫训练——正则表达式+BeautifulSoup爬图片的更多相关文章
- 【python爬虫和正则表达式】爬取表格中的的二级链接
开始进公司实习的一个任务是整理一个网页页面上二级链接的内容整理到EXCEL中,这项工作把我头都搞大了,整理了好几天,实习生就是端茶送水的.前段时间学了爬虫,于是我想能不能用python写一个爬虫一个个 ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(一)——设置代理IP
自己写了一个爬虫爬取豆瓣小说,后来为了应对请求不到数据,增加了请求的头部信息headers,为了应对豆瓣服务器的反爬虫机制:防止请求频率过快而造成“403 forbidden”,乃至封禁本机ip的情况 ...
- python爬虫:利用BeautifulSoup爬取链家深圳二手房首页的详细信息
1.问题描述: 爬取链家深圳二手房的详细信息,并将爬取的数据存储到Excel表 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目标网址:https://sz.lianjia.com ...
- python爬虫-80电子书,爬图片
''' 作者:Caric_lee 日期:2018 查看图片 ''' import requests from bs4 import BeautifulSoup r = requests.get(&qu ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(三)——将小说信息写入文件
#-*-coding:utf-8-*- import urllib2 from bs4 import BeautifulSoup class dbxs: def __init__(self): sel ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(二)——回车分段打印小说信息
在上一篇文章中,我主要是设置了代理IP,虽然得到了相关的信息,但是打印出来的信息量有点多,要知道每打印一页,15个小说的信息全部会显示而过,有时因为屏幕太小,无法显示全所有的小说信息,那么,在这篇文章 ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
随机推荐
- 20165305 苏振龙《Java程序设计》第二周学习总结
代码托管(ch2,ch3) 脚本截图 教材内容总结 类型.变量与运算符 基本类型 整数(short.int.long) 字节(byte) 浮点数(float/double) 字符(char)将一个数字 ...
- 集合——iterator迭代器
Iterator接口: Iterator接口使用: 其中,集合Collection接口的定义也是使用多态,必须要创建它的子类对象才行,子类接口也是不能直接创建对象的(List接口): 其中wihle的 ...
- Redis性能监控
参考地址: redis教程:http://www.runoob.com/redis/redis-tutorial.html redis百度百科:https://baike.baidu.com/item ...
- Linux服务器配置---安装nfs
安装nfs NFS是Network File System的缩写,即网络文件系统.客户端通过挂载的方式将NFS服务器端共享的数据目录挂载到本地目录下. 由于NFS支持的功能很多,不同功能会使用不同程序 ...
- 单台主机上DB2 10.5和arcgis 10.4 空间数据库配置
该篇文章重点参考arcgis官网说明:http://enterprise.arcgis.com/zh-cn/server/10.4/publish-services/linux/register-db ...
- .NET 常用ORM之SubSonic
一.SubSonic简单介绍 SubSonic是一个类似Rails的开源.NET项目.你可以把它看作是一把瑞士军刀,它可以用来构建Website和通过ORM方式来访问数据.Rob Conery和Eri ...
- Python+OpenCV图像处理(三)—— Numpy数组操作图片
一.改变图片每个像素点每个通道的灰度值 (一) 代码如下: #遍历访问图片每个像素点,并修改相应的RGB import cv2 as cv def access_pixels(image): prin ...
- 深度点评五种常见WiFi搭建方案
总结十年无线搭建经验,针对企业常见的五种办公室无线网络方案做个简要分析,各种方案有何优劣,又适用于那种类型的企业. 方案一:仅路由器或AP覆盖 简述:使用路由器或AP覆盖多个无线盲区,多个AP的部署实 ...
- 使用 ffmpeg 转换视频格式
ffmpeg 是 *nix 系统下最流行的音视频处理库,功能强大,并且提供了丰富的终端命令,实是日常视频处理的一大利器! 实例 flac 格式转 mp3 音频格式转换非常简单: ffmpeg -i i ...
- logger日志模块
简单配合模式: import logging#简单配置logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(filename)s ...