基于神经网络的颜色恒常性—Fully Convolutional Color Constancy with Confidence-weighted Pooling
论文地址:
http://openaccess.thecvf.com/content_cvpr_2017/papers/Hu_FC4_Fully_Convolutional_CVPR_2017_paper.pdf
源代码(Python):
https://github.com/yuanming-hu/fc4
一、 任务描述
网络的主要目的是能够对偏色的图片估计光源,从而移除偏色,恢复图片真实颜色。为满足此类网络训练要求,需要数据集中不仅包括图片且需要提供图片的真实光源数据。
二、 数据集
解释网络原理前,先下载数据集并了解数据集,有助于后面原理的理解
数据集(Shi's Re-processing of Gehler's Raw Dataset):
http://www.cs.sfu.ca/~colour/data/shi_gehler/
下载的文件包括:
png_canon1d.zip
png_canon5d_1.zip
png_canon5d_2.zip
png_canon5d_3.zip
groundtruth_568.zip;
其中,前四个文件夹中是图片,最后一个文件夹中包括对应图片的光照数据。
下载后,将所有图片放入一个文件夹中,一共有568张图片

注:568张图片是16位RAW图像,电脑图片查看工具一般是8位的,所以显示纯黑
利用Python代码进行图片格式转换(训练时中并不需要此步骤),可以看到图片真实效果(借助下载文件中保存了真实光源文件real_illum_568.mat),效果如下图(8D5U5525.png):


(16bit RAW原图) (8bit 图)
代码如下:
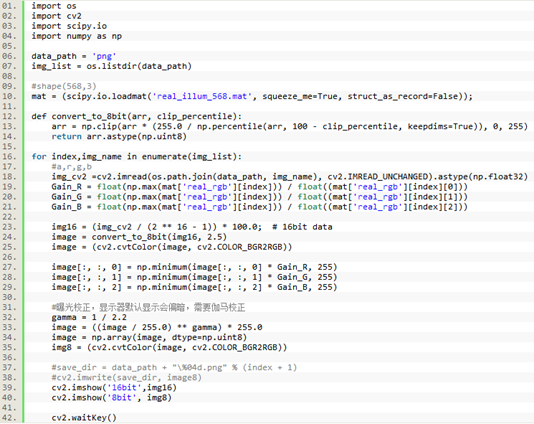
三、 网络原理
先看整个网络的结构图:
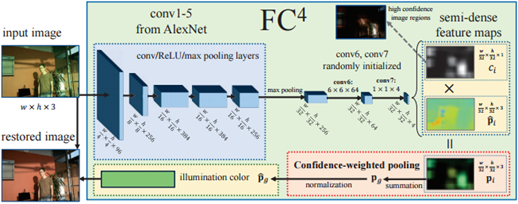
1) 网络结构:
论文使用全卷积网络,代替了全连接层,可以接受任意图像尺寸的输入 ,当然,训练时,输入还是需要归一化到大致相当的尺寸,保持统一尺度。同时,代码中使用SqueezeNet网络代替AlexNet网络,相较于AlexNet网络,SqueezeNet更轻量级,在保持同等分类精准率的前提下,模型参数缩小了50部。
2)输入图片
从上述网络框架图中看到输入图片‘input image’的w和h,并不是原始图片的大小,在此项目中w*h=512*512,即一个patch。
而512*512输入图片的产生原理:选择边长比例为【0.1~1】范围内随机值乘以原始图像的较短边,以此大小生成正方形裁剪框;以【-30°~+30°】范围内随机的角度值旋转原始图像,接着,从上述旋转操作结束后得到的图像中随机选择一点作为该方形裁剪框的左上角并开始裁剪,调整裁剪下来的图片大小到512*512。为了增强数据效果,512*512的图片可进行随机的上、下和左、右翻转,且,利用【0.6~1.4】中随机值调整图片RGB值及其光照信息(基于原始光照ground truth值),这样即完成了数据预处理工作,得到输入图片。
注:上述中涉及的数值均可在源代码文件config.py中进行动态设置
3)架构解析
首先,可以在ImageNet上预训练SqueezeNet,而对于分类作用的SqueezeNet网络提取到的是图片的语义信息,且光照不敏感的;论文中对网络结构进行改造,使用SqueezeNet的前5层卷积层,即输入的结构是:512*512*3,经过SqueezeNet的5层卷积层后得到的结构是:15*15*512;而语义信息会作为区分不同照度的置信权重,语义信息越多的,可认为其权重越大,越能影响决定最终光照。
接着,经过conv6和conv7两个卷积层降维后,结构变成:15*15*4;假设这样规定:经过conv7后得到的4通道数据中包括照明估计的三个颜色通道,第四通道为置信度权重c.
至此,可以看出FC4采用了一种选择机制,选择图像中的哪些色块用于估计,避免语义不明确的色块影响照度估计;网络中采用更大的带有更多的语义patch(以往论文中大多是32*32大小的patch),利用FC网络共享特性将局部估计结合到全局中,同时,利用置信度权重,可以将监督信号仅派发给训练期间具有语义的区域;简单来说:就是先估计所有局部区域的光源,接着聚合所有局部区域的光源信息形成最终结果。注:局部区域并不是一个patch,是其子集
如果希望预测的精度越高,则可以提供更多的patch,其覆盖率越高,精度自然也会更高,但效率会变低。
4)损失值计算
首先,先看下如何计算网络得到光源估计值,参照论文中的公式:
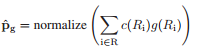
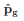 :patch的照度估计值
:patch的照度估计值
 :Ri区域的权重值
:Ri区域的权重值
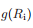 :Ri区域的照度估计值
:Ri区域的照度估计值
补充,基于上述公式的特点,源代码中conv7提供了两种结构方案:
① conv7:1*1*3,直接只输出非标准化的R,G,B,并简单地取和和归一化,使用长度进行加权计算。
② conv7:1*1*4,输出归一化的RGB颜色通道和权重通道,如同上面公式中进行加权求和。
如果假设真实光照值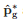 ,则计算损失值的公式如下:
,则计算损失值的公式如下:
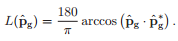
通过不断地迭代训练,优化损失值,得出最终照度估计值,作用于输入图片上,即完成了网络的目的,得到‘去偏色’图片。
四、 网络复现
1) 复现SqueezeNet
作者提供了SqueezeNet在ImageNet上预训练的模型文件model.pkl,版本是python2.7的,如果您的环境也是如此,则不需要复现SqueezeNet,如果不是,可以按照下面步骤进行复现
Github: https://github.com/DeepScale/SqueezeNet
SqueezeNet网络Caffe版本的地址,可以下载进行训练,其复现方式可以参考https://www.cnblogs.com/wangyong/p/8616939.html,这里就省略具体过程了。
训练结束后,可以得到后缀为.caffemodel的模型文件,依据源代码中需求将.caffemodel文件转换为.pkl文件,python代码如下:
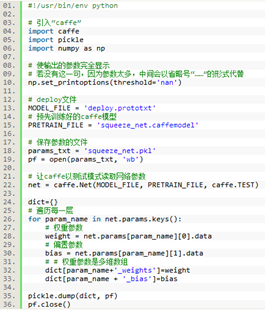
将生成的squeeze_net.pkl替换源代码中的data/squeeze_net文件夹下的model.pkl
2) 图片预处理
数据集是一共568张RAW格式的图片,附带每张图片的真实光源信息,同时,在下载的源代码中,还有每张图片中的Macbeth Color Checker(颜色检查器)的坐标信息文件。
作者将568张图片分成了三批,以进行三重交叉验证,增强网络训练效果,其中:
第一批:189张图片
第二批:191张图片
第三批:188张图片
因为FCN网络会学习到图片中的颜色信息作为语义来影响照度估计,所以,需要将图片中颜色丰富的color checker去掉以免干扰结果,作者的做法是根据color checker的坐标信息,将其位置处像素置黑,去除干扰。
最后,生成三个后缀为.pkl的文件,关于细节可以参看源代码文件datasets.py
3) 训练和测试网络
依据作者在Github上的说明,可以按照其步骤进行训练和测试;下面是我测试出来的图片效果,复现了仅有三个输出类别的SuqeezeNet网络:


作为一枚技术小白,写这篇笔记的时候参考了很多博客论文,在这里表示感谢,同时,转载请注明出处......
基于神经网络的颜色恒常性—Fully Convolutional Color Constancy with Confidence-weighted Pooling的更多相关文章
- Fully Convolutional Networks for Semantic Segmentation 译文
Fully Convolutional Networks for Semantic Segmentation 译文 Abstract Convolutional networks are powe ...
- 深度学习白平衡(Color Constancy,AWB):ICCV2019论文解析
深度学习白平衡(Color Constancy,AWB):ICCV2019论文解析 What Else Can Fool Deep Learning? Addressing Color Constan ...
- 白*衡(Color Constancy,无监督AWB):CVPR2019论文解析
白*衡(Color Constancy,无监督AWB):CVPR2019论文解析 Quasi-Unsupervised Color Constancy 论文链接: http://openaccess. ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- 论文笔记之:Fully Convolutional Attention Localization Networks: Efficient Attention Localization for Fine-Grained Recognition
Fully Convolutional Attention Localization Networks: Efficient Attention Localization for Fine-Grain ...
- 论文学习:Fully Convolutional Networks for Semantic Segmentation
发表于2015年这篇<Fully Convolutional Networks for Semantic Segmentation>在图像语义分割领域举足轻重. 1 CNN 与 FCN 通 ...
- 论文翻译:2020_FLGCNN: A novel fully convolutional neural network for end-to-end monaural speech enhancement with utterance-based objective functions
论文地址:FLGCNN:一种新颖的全卷积神经网络,用于基于话语的目标函数的端到端单耳语音增强 论文代码:https://github.com/LXP-Never/FLGCCRN(非官方复现) 引用格式 ...
- 论文阅读笔记三十五:R-FCN:Object Detection via Region-based Fully Convolutional Networks(CVPR2016)
论文源址:https://arxiv.org/abs/1605.06409 开源代码:https://github.com/PureDiors/pytorch_RFCN 摘要 提出了基于区域的全卷积网 ...
- 【Detection】R-FCN: Object Detection via Region-based Fully Convolutional Networks论文分析
目录 0. Paper link 1. Overview 2. position-sensitive score maps 2.1 Background 2.2 position-sensitive ...
随机推荐
- Spring的 AOP底层用到两种代理机制
JDK 的动态代理:针对实现了接口的类产生代理.CGlib 的动态代理:针对没有实现接口的类产生代理,应用的是底层的字节码增强的技术 生成当前类的子类对象 JDK动态代理实现1. 创建接口和对应实现类 ...
- 自学Aruba5.3.3-Aruba安全认证-有PEFNG 许可证环境的认证配置Captive-Portal
点击返回:自学Aruba之路 自学Aruba5.3.3-Aruba安全认证-有PEFNG 许可证环境的认证配置Captive-Portal 1. Captive-Portal认证配置前言 1.1 新建 ...
- 牛客练习赛 小D的剑阵 解题报告
小D的剑阵 题意链接: https://ac.nowcoder.com/acm/contest/369/F 来源:牛客网 现在你有 \(n\) 把灵剑,其中选择第i把灵剑会得到的 \(w_i\) 攻击 ...
- SpringBoot集成RocketMQ
实战,用案例来说话 前面已经说了JMS和RocketMQ一些概念和安装,下面使用SpringBoot来亲身操作一下. 生产者的操作 SpringBoot项目创建完成,引入依赖是第一步: <dep ...
- 前端学习 -- Html&Css -- 框架集
框架集和内联框架的作用类似,都是用于在一个页面中引入其他的外部的页面,框架集可以同时引入多个页面,而内联框架只能引入一个,在h5标准中,推荐使用框架集,而不使用内联框架. 使用frameset来创建一 ...
- Android DownloadManager 的使用
分类: android 技巧2013-05-28 10:32 3278人阅读 评论(1) 收藏 举报 目录(?)[+] 从Android 2.3(API level 9)开始Android用系 ...
- 从C,C++,JAVA和C#看String库的发展(一)----C语言和C++篇
转自: http://www.cnblogs.com/wenjiang/p/3266305.html 基本上所有主流的编程语言都有String的标准库,因为字符串操作是我们每个程序员几乎每天都要遇到的 ...
- 代码大片出现报错,请重新编译——Clean
工作空间中项目莫名大片报错,可能是各种意外原因导致的代码编译错误,可以选 菜单栏的 Project,Clean一下全部项目,系统会自动重新编译所有项目,有时会有奇效.
- spring对事务的配置
接下来我将给大家介绍spring事务配置的两种方式: 1.基于XML的事务配置.2.基于注解方式的事务配置. 前言:在我们详细介绍spring的两种声明式事务管理之前,我们需要先理解这些概念 1)sp ...
- Pentaho data integration(kettle) 在Mac上启动不了
环境 MacOS Mojave (10.14.1) Pentaho Data Integration 8.2 Java 8 现象 从官方下载下来最新的安装包,解压之后,双击Data Integrati ...