Iris花逻辑回归与实现
Iris花的分类是经典的逻辑回归的代表;但是其代码中包含了大量的python库的核心处理模式,这篇文章就是剖析python代码的文章。
#取用下标为2,3的两个feture,分别是花的宽度和长度;
#第一个维度取“:”代表着所有行,第二个维度代表列范围,这个参数模式其实和reshape很像
X = iris["data"][:, (2,3)]
y = (iris["target"]==2).astype(np.int) #分类做了数字转化,如果是Iris,ture,则强转为整型1,false则强转为0
log_reg = LogisticRegression(C=10**10) #设定C值,C代表精度,是控制外形边缘的准确度,值越大,则精度越高
log_reg.fit(X, y) #对于数据进行学习,获取模型参数,比如coef,intercepted等
# meshgrid是将参数中p1和p2进行坐标转换,下面将会详细介绍
# np.linspace则是将2.9到7等分500份,reshape(-1,1)代表行数根据实际情况,列数为1
x0, x1=np.meshgrid(np.linspace(2.9, 7, 500).reshape(-1, 1),
np.linspace(0.8, 2.7, 200).reshape(-1,1))
# raval和flatter意义很类似,只不过raval返回的引用,对于返回值的修改将会影响到原始数据(x0,x1),后者则返回copy,和原始数据无关
# 关于np.c_则是实现了数组的融合,下面有具体的示例
X_new = np.c_[(x0.ravel(), x1.ravel())]
# 回归的predic只是返回预测值(返回所有分类中最大的那个),predict_proba则是返回所有类别的预测值
y_probe = log_reg.predict_proba(X_new)
plt.figure(figsize=(10,4))
# 这个X[y==0, 0]表达的意思比较复杂,代表的是y值是0(0代表某个分类)的对应X值,这个说法完美解释了X[y==0],那么X[y==0, 0]的涵义就是X值的第一个特征值,
18 # 类似的X[y==0,1]代表X值的第二个特征值;从题头可以获知X是两个特征元组集合,第一个代表宽度,第二个代表长度;
plt.plot(X[y==0, 0], X[y==0,1], "bs")
plt.plot(X[y==1, 0], X[y==1, 1], "g^")
zz=y_probe[:, 1].reshape(x0.shape)
# contour的意思是等高线(下面有详细的介绍)
contour=plt.contour(x0, x1,zz, cmap=plt.cm.brg)
plt.clabel(contour, inline=1, fontsize=12) left_right=np.array([2.9, 7])
# 这个公式确实不知道是怎么来的,boundary的获取为什么是这个公式?
boundary = -(log_reg.coef_[0][0] * left_right + log_reg.intercept_[0]) / log_reg.coef_[0][1]
plt.plot(left_right, boundary, "k--", linewidth=3)
plt.text(3.2, 1.5, "Not iris", fontsize=14, color="b", ha="center")
plt.text(6.5, 2.25, "iris", fontsize=14, color="g", ha="center")
plt.axis([2.9, 7,0.8, 2.7])
plt.show()
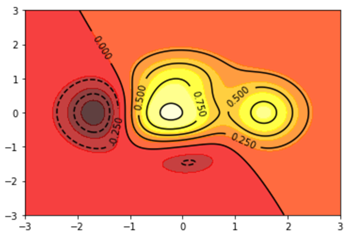
关于数据等高线的示例demo:
def height(x, y):
return (1-x/2+x**5+y**3)*np.exp(-x**2-y**2) x = np.linspace(-3, 3, 300)
y = np.linspace(-3, 3, 300)
X, Y = np.meshgrid(x, y)
plt.contourf(X, Y, height(X,Y), 10, alpha=0.75, cmap=plt.cm.hot)
C = plt.contour(X, Y, height(X, Y), colors="black")
plt.clabel(C, inline=True, fontsize=10)
plt.xticks()
plt.yticks()
plt.show()
Numpy.c_示例
>>> np.c_[np.array([1,2,3]), np.array([4,5,6])]
array([[1, 4],
[2, 5],
[3, 6]])
>>> np.c_[np.array([[1,2,3]]), 0, 0, np.array([[4,5,6]])]
array([[1, 2, 3, 0, 0, 4, 5, 6]])
参考
数据等高线
https://blog.csdn.net/qq_33506160/article/details/78450
关于meshgrid
https://www.cnblogs.com/sunshinewang/p/6897966.html
https://docs.scipy.org/doc/numpy/reference/generated/numpy.meshgrid.html
关于ravel
https://blog.csdn.net/liuweiyuxiang/article/details/78220080
https://docs.scipy.org/doc/numpy/reference/generated/numpy.ravel.html
关于numpy.c_
https://docs.scipy.org/doc/numpy/reference/generated/numpy.c_.html
关于coef_和intercept_(虽然我并没有看懂)
https://blog.csdn.net/u010099080/article/details/52933430?utm_source=itdadao&utm_medium=referral
Iris花逻辑回归与实现的更多相关文章
- 逻辑回归 Logistic Regression
逻辑回归(Logistic Regression)是广义线性回归的一种.逻辑回归是用来做分类任务的常用算法.分类任务的目标是找一个函数,把观测值匹配到相关的类和标签上.比如一个人有没有病,又因为噪声的 ...
- logistic逻辑回归公式推导及R语言实现
Logistic逻辑回归 Logistic逻辑回归模型 线性回归模型简单,对于一些线性可分的场景还是简单易用的.Logistic逻辑回归也可以看成线性回归的变种,虽然名字带回归二字但实际上他主要用来二 ...
- scikit-learn中机器学习模型比较(逻辑回归与KNN)
本文源自于Kevin Markham 的模型评估:https://github.com/justmarkham/scikit-learn-videos/blob/master/05_model_eva ...
- 吴裕雄 python 机器学习——逻辑回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- sklearn逻辑回归
sklearn逻辑回归 logistics回归名字虽然叫回归,但实际是用回归方法解决分类的问题,其形式简洁明了,训练的模型参数还有实际的解释意义,因此在机器学习中非常常见. 理论部分 设数据集有n个独 ...
- Sklearn实现逻辑回归
方法与参数 LogisticRegression类的各项参数的含义 class sklearn.linear_model.LogisticRegression(penalty='l2', dual=F ...
- Spark MLlib回归算法------线性回归、逻辑回归、SVM和ALS
Spark MLlib回归算法------线性回归.逻辑回归.SVM和ALS 1.线性回归: (1)模型的建立: 回归正则化方法(Lasso,Ridge和ElasticNet)在高维和数据集变量之间多 ...
- PytorchZerotoAll学习笔记(五)--逻辑回归
逻辑回归: 本章内容主要讲述简单的逻辑回归:这个可以归纳为二分类的问题. 逻辑,非假即真.两种可能,我们可以联想一下在继电器控制的电信号(0 or 1) 举个栗子:比如说你花了好几个星期复习的考试(通 ...
- 机器学习方法(五):逻辑回归Logistic Regression,Softmax Regression
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术.应用感兴趣的同学加入. 前面介绍过线性回归的基本知识, ...
随机推荐
- <顺序访问><随机访问><HDFS>
Overview 如果你了解过HDFS,至少看过这句话吧: HDFS is a filesystem designed for storing very large files with stream ...
- 五、LCD屏填充纯色
废话不说,直接上代码: lcd.c #include "lcd.h" static int PEN_COLOR = LCD_RED; /* 定义画笔(前景)颜色 */ static ...
- ios中字典转模型的创建以及简单用法
// appModel.h // Created by zzqqrr on 17/8/19. // #import <Foundation/Foundation.h> @interface ...
- ios手动添加数组字典(NSMutableDictionary)
@property (nonatomic,strong) NSArray *imageData;//定义一个数组 -(NSArray *)imageDate { if(_imageDate==nil) ...
- SpringBoot集成Swagger2实现Restful(类型转换错误解决办法)
1.pom.xml增加依赖包 <dependency> <groupId>io.springfox</groupId> <artifactId>spri ...
- 对于maven的一些命令
- Quartz 原理
Quartz API :http://www.quartz-scheduler.org/api/2.2.0/ http://www.boyunjian.com/javadoc/org.apache.s ...
- C语言——第三次作业(2)
作业要求一 PTA作业的提交列表 第一次作业 第二次作业 一道编程题: 有一个axb的数组,该数组里面顺序存放了从1到a*b的数字.其中a是你大学号的前三位数字,b是你大学号的后四位数字,比如你的学号 ...
- i.MX6 u-boot 怎么确定板级头文件
/********************************************************************** * i.MX6 u-boot 怎么确定板级头文件 * 说 ...
- SEGMENTATION FAULT IN LINUX 原因与避免
https://www.cnblogs.com/no7dw/archive/2013/02/20/2918372.html