ML: 降维算法-LLE
局部线性嵌入 (Locally linear embedding)是一种非线性降维算法,它能够使降维后的数据较好地保持原有 流形结构 。LLE可以说是流形学习方法最经典的工作之一。很多后续的流形学习、降维方法都与LLE有密切联系。
如下图,使用LLE将三维数据(b)映射到二维(c)之后,映射后的数据仍能保持原有的数据流形(红色的点互相接近,蓝色的也互相接近),说明LLE有效地保持了数据原有的流行结构。
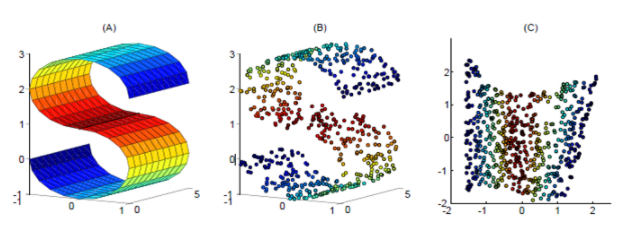
但是LLE在有些情况下也并不适用,如果数据分布在整个封闭的球面上,LLE则不能将它映射到二维空间,且不能保持原有的数据流形。那么我们在处理数据中,首先假设数据不是分布在闭合的球面或者椭球面上。
LLE算法认为每一个数据点都可以由其近邻点的线性加权组合构造得到。算法的主要步骤分为三步:
- 1、寻找每个样本点的k个近邻点;
- 2、由每个 样本点的近邻点计算出该样本点的局部重建权值矩阵;
- 3、由该样本点的局部重建权值矩阵和其近邻点计算出该样本点的输出值。
理解:对于图像X中每一个块X1
- 第一步是计算出每个样本点Xi的k个近邻点,即找出样本点的近邻域集合,此处计算可以通过欧几里德距离法求;
- 第二步是计算出样本点的局部重建权值矩阵W来使得重构块X1的误差最小化;
- 第三步将所有样本点映射到低维空间中达到降维的目的
其原理解释可参考:
R实现LLE算法包
R算法包 lle , 参考资料:https://cran.r-project.org/web/packages/lle/index.html
Usage: lle(X, m, k, reg = 2, ss = FALSE, p = 0.5, id = FALSE, nnk = TRUE, eps = 1, iLLE = FALSE, v = 0.99)
- X: 输入的数据对象
- m: 输入数据的内在维度,这个参数主要影响结果的可视化,实现的内在维度结果在算法中会自动进行计算
- k: 近邻个数,K的取值在算法中起到关键作用,如果K值太大,LLE不能体现局部特性。使得LLE算法趋向于PCA算法。反之取得太小,LLE便不能保持样本点在在低维空间中的拓扑结构。可使用
calc_k. 函数进行计算 - id: 逻辑变量,定义是否进行内存维度计算
Usage: calc_k(X, m, kmin=1, kmax=20, plotres=TRUE,parallel=FALSE, cpus=2, iLLE=FALSE)
- m: 输入数据的内在维度
- kmin: K最小值
- kmax: K最大值
- plotres:是否plot结果
- parallel: 是否使用并行计算
示例代码
> remove(list = ls())
> if (require(lle) == FALSE)
+ {
+ install.packages("lle")
+ }
>
> test <- iris[,1:4]
> le <- lle(test,5,20,id=TRUE)
finding neighbours
calculating weights
intrinsic dim: mean=3.96, mode=4
computing coordinates
> table(le$id) 3 4
6 144
从上面的结果发现,输入数据的内在维度为2,再通过calc_k计算最合适的K值
> k <- calc_k(test,2,kmin = 1,kmax = dim(test)[1])
snowfall 1.84-6.1 initialized: sequential execution, one CPU.
如下图,选择K值:50

根据计算优化的参数,重新进行数据计算
> le <- lle(test,2,50)
finding neighbours
calculating weights
computing coordinates
> newSet <- cbind(iris,as.data.frame(le$Y))
> head(newSet)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species V1 V2
1 5.1 3.5 1.4 0.2 setosa 0.5703337 -1.345773
2 4.9 3.0 1.4 0.2 setosa -0.7795944 -1.236492
3 4.7 3.2 1.3 0.2 setosa -0.8186908 -1.311557
4 4.6 3.1 1.5 0.2 setosa -1.2211154 -1.217567
5 5.0 3.6 1.4 0.2 setosa 0.5488266 -1.365494
6 5.4 3.9 1.7 0.4 setosa 1.9528668 -1.289062
结果图例显示
library(rgl)
plot_lle(le$Y,test)

ML: 降维算法-LLE的更多相关文章
- ML: 降维算法-概述
机器学习领域中所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中.降维的本质是学习一个映射函数 f : x->y,其中x是原始数据点的表达, y是数据点映射后的低维向量 ...
- ML: 降维算法-LE
PCA的降维原则是最小化投影损失,或者是最大化保留投影后数据的方差.LDA降维需要知道降维前数据分别属于哪一类,而且还要知道数据完整的高维信息.拉普拉斯特征映射 (Laplacian Eigenmap ...
- ML: 降维算法-LDA
判别分析(discriminant analysis)是一种分类技术.它通过一个已知类别的“训练样本”来建立判别准则,并通过预测变量来为未知类别的数据进行分类.判别分析的方法大体上有三类,即Fishe ...
- ML: 降维算法-PCA
PCA (Principal Component Analysis) 主成份分析 也称为卡尔胡宁-勒夫变换(Karhunen-Loeve Transform),是一种用于探索高维数据结 ...
- 四大机器学习降维算法:PCA、LDA、LLE、Laplacian Eigenmaps
四大机器学习降维算法:PCA.LDA.LLE.Laplacian Eigenmaps 机器学习领域中所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中.降维的本质是学习一个映 ...
- 【转】四大机器学习降维算法:PCA、LDA、LLE、Laplacian Eigenmaps
最近在找降维的解决方案中,发现了下面的思路,后面可以按照这思路进行尝试下: 链接:http://www.36dsj.com/archives/26723 引言 机器学习领域中所谓的降维就是指采用某种映 ...
- 降维算法整理--- PCA、KPCA、LDA、MDS、LLE 等
转自github: https://github.com/heucoder/dimensionality_reduction_alo_codes 网上关于各种降维算法的资料参差不齐,同时大部分不提供源 ...
- 【机器学习基础】无监督学习(2)——降维之LLE和TSNE
在上一节介绍了一种最常见的降维方法PCA,本节介绍另一种降维方法LLE,本来打算对于其他降维算法一并进行一个简介,不过既然看到这里了,就对这些算法做一个相对详细的学习吧. 0.流形学习简介 在前面PC ...
- sklearn LDA降维算法
sklearn LDA降维算法 LDA(Linear Discriminant Analysis)线性判断别分析,可以用于降维和分类.其基本思想是类内散度尽可能小,类间散度尽可能大,是一种经典的监督式 ...
随机推荐
- 三层交换机实现VLAN间通信
实验要求:使用三层交换机,让同一vlan的主机能通信,不同vlan的主机也能通信 拓扑如下: 涉及内容: 1.VTP的创建和配置 2.vlan的创建和划分 3.三层交换机的配置 4.端口的trunk模 ...
- SpringBatch Sample (一)(Hello World)
通过前面两篇关于Spring Batch文章的介绍,大家应该已经对Spring Batch有个初步的概念了.这篇文章,将通过一个”Hello World!”实例,和大家一起探讨关于Spring Bat ...
- Python之路,第十八篇:Python入门与基础18
python3 面向对象编程2 类方法: @classmethod 作用:1,类方法是只能访问类变量的方法: 2,类方法需要使用@classmethod 装饰器定义: 3,类方法的第一个参数是类的实 ...
- python sort、sorted高级排序技巧
文章转载自:脚本之家 Python list内置sort()方法用来排序,也可以用python内置的全局sorted()方法来对可迭代的序列排序生成新的序列. 1)排序基础 简单的升序排序是非常容易的 ...
- HDU - 5157 :Harry and magic string (回文树,求多少对不相交的回文串)
Sample Input aca aaaa Sample Output 3 15 题意: 多组输入,每次给定字符串S(|S|<1e5),求多少对不相交的回文串. 思路:可以用回文树求出以每个位置 ...
- innerHTML与innerText功能的强大
例: <div id="study"> <span style="color:red">学习</span>study < ...
- java错误:找不到或无法加载主类
问题: 在 windows cmd 中编译后,运行 java 文件时,出现此错误 分析: 源文件 ClientDemo.java: package netdemo; public class Clie ...
- 2017.5.11 MapReduce运行机制
和HDFS一样,MapReduce也是采用Master/Slave的架构 MapReduce1包含4个部分:Client.JobTracker.TaskTracker和Task Client 将JAR ...
- web四则混合运算2
一.设计思路: 先出题(String型)(上周已经实现),再写方法计算结果,加入控制有无乘除法,范围,参与计算数,出题数,页码显示等简单功能,有无括号和分数的计算目前还没能实现. 二.代码: 界面 & ...
- (25)Django中操作cookie与session组件(添加cookie和删除cookie)
cookie是存在于客户端浏览器上的键值对,是明文的 cookie是当用户访问网站时候和数据提起携带过去,安全性比较差, 容易被拦截 session存在于服务端的键值对,是一串加密的字符串 当用户登陆 ...