Druid + Grafana 应用实践
谈到大数据,大家首先想到的肯定是Hadoop,近年来互联网技术的快速增长催生了各类大体量数据的爆发,Hadoop最大的贡献在于帮助企业将那些低价值的事件流数据转化为高价值的聚合数据,为企业的经营决策提供数据支撑。但Hadoop擅长的是存储和获取大规模数据,但是它并不提供任何性能上的保证。从这个角度来讲,我们可以把Hadoop看作是一个很好的后端、批量处理和数据仓库系统。在一个需要高并发并且保证查询性能和数据可用性的场景下,Hadoop并不能满足需求, 因此而引出了我们今天要介绍的主角: Druid集群。
Druid是一套基于大数据集之上做实时统计分析而设计的开源系统,主要特点包含分布式、列存储、内存数据库、实时分析。当前版本 0.10.0 (官网:http://druid.io), 主要作者:杨仿金同学已回到中国,另一老外成立自己的公司,在Druid集群之上提供商业化服务,包含PloySQL、Pivot等增值化组件。

在五横一竖常规的大数据架构中,从数据采集、数据处理、数据分析、数据访问、数据应用每一层均提供N多可供选择的组件包,可谓是“百花齐放”、能让您选花了眼。Druid 主要优势在于实时流式数据的处理与高效OLAP分析,与其它开源组件优劣对比见上图。

Druid集群主要包含了以下几类角色:
Ø RealNode:封装了导入和查询事件数据的功能,经由这些节点导入的事件数据可以立刻被查询
Ø HistoricalNode:封装了加载和处理由实时节点创建的不可变数据块(segment)的功能。在很多现实世界的工作流程中,大部分导入到Druid集群中的数据都是不可变的,因此,历史节点通常是Druid集群中的主要工作组件。
Ø BrokerNode:扮演着历史节点和实时节点的查询路由的角色。
Ø CoordinatorNode:主要负责数据的管理和在历史节点上的分布。协调节点告诉历史节点加载新数据、卸载过期数据、复制数据、和为了负载均衡移动数据。
Ø 除了上面介绍的节点角色外,Druid还依赖于外部的三个组件:ZooKeeper, Metadata Storage, Deep Storage,数据与查询流的交互如上图,简述如下:
ü ① 实时数据写入到实时节点,会创建索引结构的Segment
ü ② 实时节点的Segment经过一段时间会转存到DeepStorage
ü ③ 元数据写入MySQL; 实时节点转存的Segment会在ZooKeeper中新增一条记录
ü ④ 协调节点从MySQL获取元数据,比如schema信息(维度列和指标列)
ü ⑤ 协调节点监测ZK中有新分配/要删除的Segment,写入ZooKeeper信息:历史节点需要加载/删除Segment
ü ⑥ 历史节点监测ZK, 从ZooKeeper中得到要执行任务的Segment
ü ⑦ 历史节点从DeepStorage下载Segment并加载到内存/或者将已经保存的Segment删除掉
ü ⑧ 历史节点的Segment可以用于Broker的查询路由
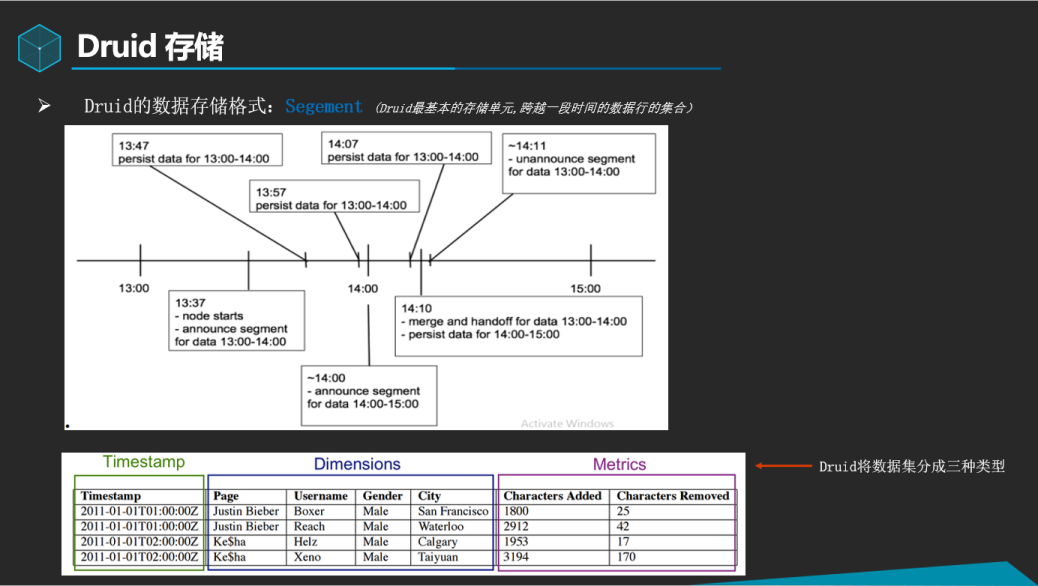
实时节点在处理数据导入、持久化、合并和传送这些阶段都是流动的,并且在这些处理阶段中不会有任何数据的丢失,数据流图如上:
Ø 节点启动于13:47,并且只会接受当前小时和下一小时的事件数据。当事件数据开始导入后,节点会宣布它为13:00到14:00这个时间段的Segment数据提供服务
Ø 每10分钟(这个时间间隔是可配置的),节点会将内存中的缓存数据刷到磁盘中进行持久化,在当前小时快结束的时候,节点会准备接收14:00到15:00的事件数据,一旦这个情况发生了,节点会准备好为下一个小时提供服务,并且会建立一个新的内存中的索引。
Ø 随后,节点宣布它也为14:00到15:00这个时段提供一个segment服务。节点并不是马上就合并13:00到14:00这个时段的持久化索引,而是会等待一个可配置的窗口时间,直到所有的13:00到14:00这个时间段的一些延迟数据的到来。这个窗口期的时间将事件数据因延迟而导致的数据丢失减低到最小。
Ø 在窗口期结束时,节点会合并13:00到14:00这个时段的所有持久化的索引合并到一个独立的不可变的segment中,并将这个segment传送走,一旦这个segment在Druid集群中的其他地方加载了并可以查询了,实时节点会刷新它收集的13:00到14:00这个时段的数据的信息,并且宣布取消为这些数据提供服务。

上图为我们正式集群DataSource 存储结构示意图,所有的NoSQL中都有数据分片的概念,比如ES的分片,HBase的Region,都表示的是数据的存储介质.为什么要进行分片,因为数据大了,不能都存成一个大文件吧?所以要拆分成小文件以便于快速查询. 伴随拆分通常都有合并小文件

通过实时采集充电日志,以按区域、场站等维度实时分析充电相关的指标分析为场景进行案例分享
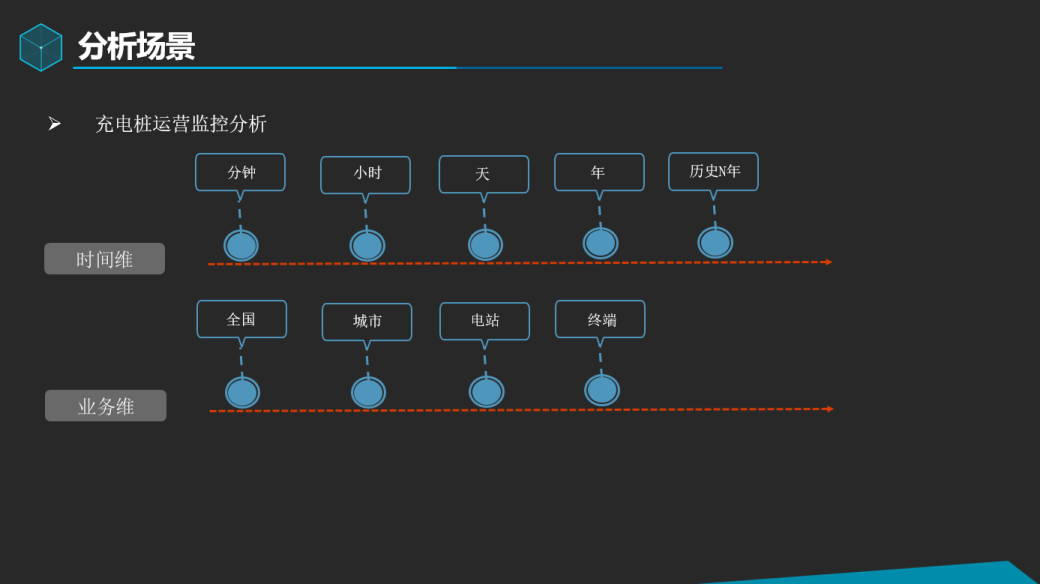
分享案例统计维度如上图

数据流处理示意图

扩展Grafana可视化组件的数据源插件、UI插件

按区域实时监控每分钟充电指标,通过选择左上角的导航面板中不同的区域,触发Dashboard内其它面板数据刷新

基于场站实时监控,支持全文检索或选择高级过滤的方式快速定位电站,选中第一列的小眼睛,行背景变绿,触发当前电站下面板内其它部件数据刷新。

同样原理,更细粒度下到终端的实时监控。
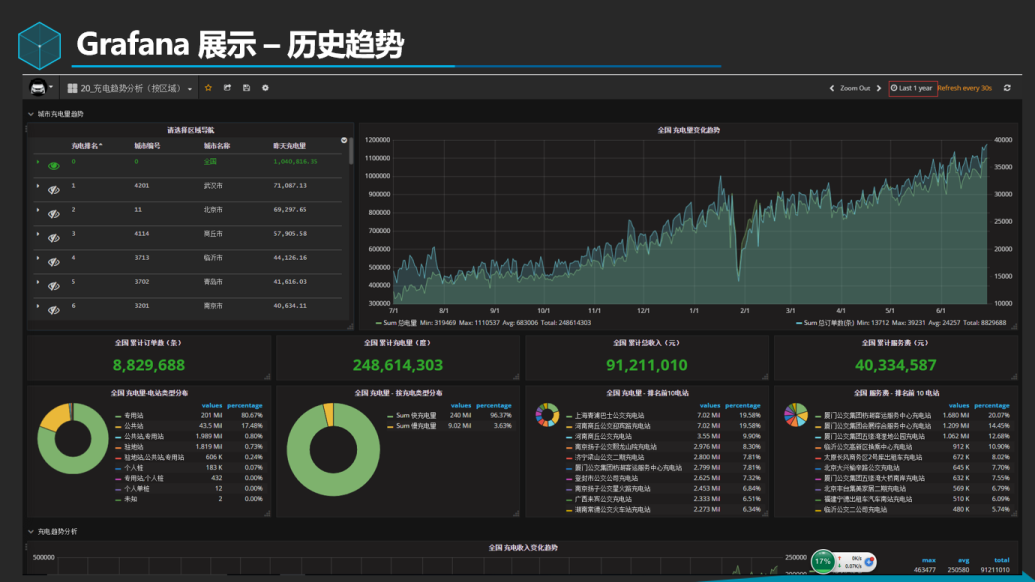
历史年度数据趋势分析
大数据需要伴随着业务的驱动来发挥其应有的价值,需要大家的共同参与来一步步夯实其底层的基础平台,期待着下一期更精彩的技术分享。
Druid + Grafana 应用实践的更多相关文章
- Druid SQL和Security在美团点评的实践
分享嘉宾:高大月@美团点评,Apache Kylin PMC成员,Druid Commiter 编辑整理:Druid中国用户组 6th MeetUp 出品平台:DataFunTalk -- 导读: 长 ...
- 基于InfluxDB+Grafana打造大数据监控利器--转
这是一个大数据爆发的时代.面对信息的激流.多元化数据的涌现,我们在获取.存储.传输.理解.分析.应用.维护大数据时,无疑需要一种便捷的信息交流通道,以便快速.有效.准确地理解和驾驭这个过程.本文将通过 ...
- 使用 Prometheus + Grafana 对 Kubernetes 进行性能监控的实践
1 什么是 Kubernetes? Kubernetes 是 Google 开源的容器集群管理系统,其管理操作包括部署,调度和节点集群间扩展等. 如下图所示为目前 Kubernetes 的架构图,由 ...
- spring boot + mybatis + druid配置实践
最近开始搭建spring boot工程,将自身实践分享出来,本文将讲述spring boot + mybatis + druid的配置方案. pom.xml需要引入mybatis 启动依赖: < ...
- 基于Grafana的监控数据钻取功能应用实践
互联网企业中,随着机器规模以及业务量的爆发式增长,监控数据逐渐成为一种大数据,对监控大数据的分析,包括数据采集.数据缓存.数据聚合分析.数据存储.数据展现等几个阶段.不同阶段有不同的解决方案及支撑工具 ...
- OneAPM大讲堂 | 监控数据的可视化分析神器 Grafana 的告警实践
文章系国内领先的 ITOM 管理平台供应商 OneAPM 编译呈现. 概览 Grafana 是一个开源的监控数据分析和可视化套件.最常用于对基础设施和应用数据分析的时间序列数据进行可视化分析,也可以用 ...
- prometheus+grafana监控mysql最佳实践
导航 前言 环境准备 安装Docker 安装prometheus 安装mysqld_exporter prometheus采集数据 安装grafana grafana配置数据源 感谢您的阅读,预计阅读 ...
- 使用Prometheus+Grafana监控MySQL实践
一.介绍Prometheus Prometheus(普罗米修斯)是一套开源的监控&报警&时间序列数据库的组合,起始是由SoundCloud公司开发的.随着发展,越来越多公司和组织接受采 ...
- Druid在有赞的实践
转载一篇自己在公司博客上的文章 一.Druid介绍 Druid 是 MetaMarket 公司研发,专为海量数据集上的做高性能 OLAP (OnLine Analysis Processing)而设计 ...
随机推荐
- 性能测试-11.Linux服务器使用NMON监控指标
一.NMON使用 首先下载nmon软件http://nmon.sourceforge.net/pmwiki.php?n=Site.Download,打开这个网站下载符合自己操作系统的硬件的相关nmon ...
- 【Python】etree方法生成,解析xml
#练习:另一种遍历xml文件的方式etree,xpathimport systry: import xml.etree.cElementTree as ET #前面带c的都是比较快的,效率高且不占内存 ...
- zookeeper和dubbo中出现的问题
报错出现timeout关键字 解决:在服务发布时,添加timeout字段 <!-- 5.服务发布 --> <dubbo:service interface="com.sxt ...
- java多线程和Calendar(日历)常用API
一.进程与线程 进程是一个可执行的程序一次运行的过程 线程是程序中的一个执行流 一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个主线程 二.Calendar import java.u ...
- math、numpy、pandas NaN 判断
>> np.nan == np.nan False >> np.nan is np.nan True >> math.nan is np.nan False > ...
- C语音下改变const变量的值的奇葩方法
恶心,超恶心~~
- APK模式下,epg版本升级,需要做同步
采用安卓盒子(APK模式),需要在管理节点做一个同步: 同步目录: /var/www/html/upgradestb 从管理节点向三台业务节点同步: 2018/01/19 conf/server.co ...
- BZOJ4426 :最大生产率(贪心+决策单调性DP)
题意:给出N个人,现在让你分P组,每组的工作效率是最小结束时间-最大开始时间,要求每一组的效率的正数,求最大效率和.N<1000 思路: 把包含至少一个其他的分到A组:否则到B组. A组的要么单 ...
- Container(容器)
容器可以管理对象的生命周期.对象与对象之间的依赖关系,您可以使用一个配置文件(通常是XML),在上面定义好对象的名称.如何产生(Prototype 方式或Singleton 方式). 哪个对象产生之后 ...
- 简易计算器的java实现
伪代码 public class MainTestwei { 定义两个数组,List<Double> number和 List<Character>calculation分别用 ...