selenium_采集药品数据
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门
https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6EmUbbW&id=564564604865
数据源
http://118.114.237.85:8081/searchbio.aspx
采集内容字段有的对不整齐,
def Get_one_table()函数需要修改

# -*- coding: utf-8 -*-
"""
Spyder Editor
采集思路:采一页,保存一页
This is a temporary script file.
"""
import requests,bs4,csv,time,selenium
from selenium import webdriver
list_allContent=[] site="http://piqianfa.scsyjs.org/"
site1="http://118.114.237.85:8081/searchbio.aspx"
charset="gb2312"
browser=webdriver.Firefox()
browser.get(site1)
pages=196 #这种方式采集下来很粗糙,容易错位
def Get_one_table():
elems=browser.find_elements_by_tag_name("tr")
content=elems[0].text
list_content=content.split("\n")
#列表内个数
num=len(list_content)
list_content2=list_content[3:num]
list_allContent.append(list_content2) return list_content2
'''
list_content2[2]
Out[13]: '批签蜀检201600220 人血白蛋白 20% 25ml 5g/瓶 201601A010 26931瓶 2021年1月22日
成都蓉生药业有限责任公司 该批制品符合规定,判定合格 2016-05-04'
''' def Write_table_to_csv(fileName,list_tableContent):
#对列表格式修改,字符串写入的格式不对
list_tableContent1=[i.split(" ") for i in list_tableContent]
file=open(fileName,'w',newline='')
writer1=csv.writer(file)
writer1.writerows(list_tableContent1)
file.close() def Click_next_page():
linkElem=browser.find_element_by_link_text("下一页")
linkElem.click() def Get_fileName():
pass for i in range(1,pages+1):
list_tableContent=Get_one_table()
Click_next_page()
fileName=str(i)+".csv"
Write_table_to_csv(fileName,list_tableContent)
def Get_one_table()函数需要修改
# -*- coding: utf-8 -*-
"""
Created on Fri May 6 10:24:18 2016 @author: Administrator
"""
import requests,bs4,csv,time,selenium
from selenium import webdriver
site1="http://118.114.237.85:8081/searchbio.aspx"
charset="gb2312"
browser=webdriver.Firefox()
browser.get(site1) elems=browser.find_elements_by_class_name("tb")
elems1= elems[1:]
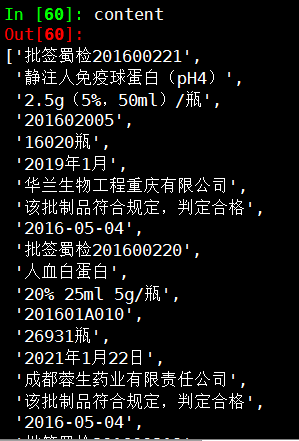
content=[i.text for i in elems1] '''
elems=browser.find_elements_by_class_name("tr")
elems
Out[33]: [] elems=browser.find_elements_by_class_name("tb")
elems[1].text
Out[25]: '批签蜀检201600221' elems[2].text
Out[26]: '静注人免疫球蛋白(pH4)' elems[3].text
Out[27]: '2.5g(5%,50ml)/瓶' elems[4].text
Out[28]: '201602005' content
Out[60]:
['批签蜀检201600221',
'静注人免疫球蛋白(pH4)',
'2.5g(5%,50ml)/瓶',
'201602005',
'16020瓶',
'2019年1月',
'华兰生物工程重庆有限公司',
'该批制品符合规定,判定合格',
'2016-05-04',
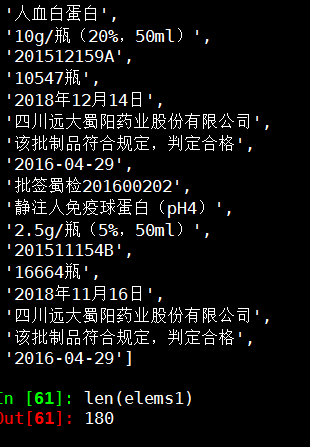
'批签蜀检201600220',
'人血白蛋白',
'20% 25ml 5g/瓶',
'批签蜀检201600202',
'静注人免疫球蛋白(pH4)',
'2.5g/瓶(5%,50ml)',
'201511154B',
'16664瓶',
'2018年11月16日',
'四川远大蜀阳药业股份有限公司',
'该批制品符合规定,判定合格',
'2016-04-29'] len(elems1)
Out[61]: 180 ''' '''
content=elems[0].text
list_content=content.split("\n")
#列表内个数
num=len(list_content)
list_content2=list_content[3:num]
'''
selenium_采集药品数据的更多相关文章
- selenium_采集药品数据2_采集所有表格
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- selenium_采集药品数据1_采集第一页表格
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- C#+HtmlAgilityPack+XPath带你采集数据(以采集天气数据为例子)
第一次接触HtmlAgilityPack是在5年前,一些意外,让我从技术部门临时调到销售部门,负责建立一些流程和寻找潜在客户,最后在阿里巴巴找到了很多客户信息,非常全面,刚开始是手动复制到Excel, ...
- Gobblin采集kafka数据
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 找时间记录一下利用Gobblin采集kafka数据的过程,话不多说,进入正题 一.Gobblin ...
- API例子:用Python驱动Firefox采集网页数据
1,引言 本文讲解怎样用Python驱动Firefox浏览器写一个简易的网页数据采集器.开源Python即时网络爬虫项目将与Scrapy(基于twisted的异步网络框架)集成,所以本例将使用Scra ...
- Performance Monitor采集性能数据
Performance Monitor采集性能数据 Windows本身为我们提供了很多好用的性能分析工具,大家日常都使用过资源管理器,在里面能即时直观的看到CPU占用率.物理内存使用量等信息.此外新系 ...
- 【Android 应用开发】分析各种Android设备屏幕分辨率与适配 - 使用大量真实安卓设备采集真实数据统计
.主要是为了总结一下 对这些概念有个直观的认识; . 作者 : 万境绝尘 转载请注明出处 : http://blog.csdn.net/shulianghan/article/details/198 ...
- Android 音视频开发(四):使用 Camera API 采集视频数据
本文主要将的是:使用 Camera API 采集视频数据并保存到文件,分别使用 SurfaceView.TextureView 来预览 Camera 数据,取到 NV21 的数据回调. 注: 需要权限 ...
- 分析各种Android设备屏幕分辨率与适配 - 使用大量真实安卓设备采集真实数据统计
一. 数据采集 源码GitHub地址 : -- SSH : git@github.com:han1202012/DisplayTest.git; -- HTTP : https://github.co ...
随机推荐
- 软件工程导论课后习题Github作业(把一个英文句子中的单词次序逆序,单词中字母正常排列)
Java源代码 package yly; import java.util.Scanner; public class ruanjian { public static void main(St ...
- Python学习笔记(二)——数据类型
1.数据类型 Python有五个标准的数据类型: Numbers(数字) String(字符串) List(列表) Tuple(元组) Dictionary(字典) 2.Python数字类型 Pyth ...
- Sublime Text3前端必备插件
安装Package Control 在安装插件之前,需要让sublime安装Package Control.打开Sublime Text的控制台,快捷键ctrl + ~,在控制台中输入以下代码. im ...
- ECharts设置y轴显示
参考地址:https://www.w3cschool.cn/echarts_tutorial/echarts_tutorial-no3h2cul.html yAxis: { type: 'value' ...
- 什么是Consul
什么是Consul Consul文档简要整理 什么是Consul? Consul是一个用来实现分布式系统的服务发现与配置的开源工具.他主要由多个组成部分: 服务发现:客户端通过Consul提供服务,类 ...
- PHP文件系统操作常用函数
虽然PHP提供很多内置的文件处理函数,但是分得特别细,有一些操作需要多个函数一起使用才能达到目标,比如删除非空文件夹的所有内容,遍历文件夹等功能,下面各个函数是学习的时候整理的,有的是教程里的,有的是 ...
- HDU 2075 A|B?
http://acm.hdu.edu.cn/showproblem.php?pid=2075 Problem Description 正整数A是否能被正整数B整除,不知道为什么xhd会研究这个问题,来 ...
- [转载] Oracle在windows下面的自动备份以及删除今天的脚本..
@echo off echo ================================================ echo Windows环境下Oracle数据库的自动备份脚本 echo ...
- 使用Hexo搭建Github静态博客
1. 环境环境 1.1 安装Git 默认配置就好 1.2 安装node.js 下载:http://nodejs.org/download/ 安装时直接保持默认配置即可. 2. 配置Github 1.1 ...
- 归并排序详解(python实现)
因为上个星期leetcode的一道题(Median of Two Sorted Arrays)所以想仔细了解一下归并排序的实现. 还是先阐述一下排序思路: 首先归并排序使用了二分法,归根到底的思想还是 ...