selenium_采集药品数据
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门
https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6EmUbbW&id=564564604865
数据源
http://118.114.237.85:8081/searchbio.aspx
采集内容字段有的对不整齐,
def Get_one_table()函数需要修改

# -*- coding: utf-8 -*-
"""
Spyder Editor
采集思路:采一页,保存一页
This is a temporary script file.
"""
import requests,bs4,csv,time,selenium
from selenium import webdriver
list_allContent=[] site="http://piqianfa.scsyjs.org/"
site1="http://118.114.237.85:8081/searchbio.aspx"
charset="gb2312"
browser=webdriver.Firefox()
browser.get(site1)
pages=196 #这种方式采集下来很粗糙,容易错位
def Get_one_table():
elems=browser.find_elements_by_tag_name("tr")
content=elems[0].text
list_content=content.split("\n")
#列表内个数
num=len(list_content)
list_content2=list_content[3:num]
list_allContent.append(list_content2) return list_content2
'''
list_content2[2]
Out[13]: '批签蜀检201600220 人血白蛋白 20% 25ml 5g/瓶 201601A010 26931瓶 2021年1月22日
成都蓉生药业有限责任公司 该批制品符合规定,判定合格 2016-05-04'
''' def Write_table_to_csv(fileName,list_tableContent):
#对列表格式修改,字符串写入的格式不对
list_tableContent1=[i.split(" ") for i in list_tableContent]
file=open(fileName,'w',newline='')
writer1=csv.writer(file)
writer1.writerows(list_tableContent1)
file.close() def Click_next_page():
linkElem=browser.find_element_by_link_text("下一页")
linkElem.click() def Get_fileName():
pass for i in range(1,pages+1):
list_tableContent=Get_one_table()
Click_next_page()
fileName=str(i)+".csv"
Write_table_to_csv(fileName,list_tableContent)
def Get_one_table()函数需要修改
# -*- coding: utf-8 -*-
"""
Created on Fri May 6 10:24:18 2016 @author: Administrator
"""
import requests,bs4,csv,time,selenium
from selenium import webdriver
site1="http://118.114.237.85:8081/searchbio.aspx"
charset="gb2312"
browser=webdriver.Firefox()
browser.get(site1) elems=browser.find_elements_by_class_name("tb")
elems1= elems[1:]
content=[i.text for i in elems1] '''
elems=browser.find_elements_by_class_name("tr")
elems
Out[33]: [] elems=browser.find_elements_by_class_name("tb")
elems[1].text
Out[25]: '批签蜀检201600221' elems[2].text
Out[26]: '静注人免疫球蛋白(pH4)' elems[3].text
Out[27]: '2.5g(5%,50ml)/瓶' elems[4].text
Out[28]: '201602005' content
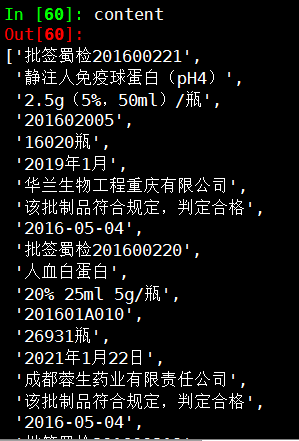
Out[60]:
['批签蜀检201600221',
'静注人免疫球蛋白(pH4)',
'2.5g(5%,50ml)/瓶',
'201602005',
'16020瓶',
'2019年1月',
'华兰生物工程重庆有限公司',
'该批制品符合规定,判定合格',
'2016-05-04',
'批签蜀检201600220',
'人血白蛋白',
'20% 25ml 5g/瓶',
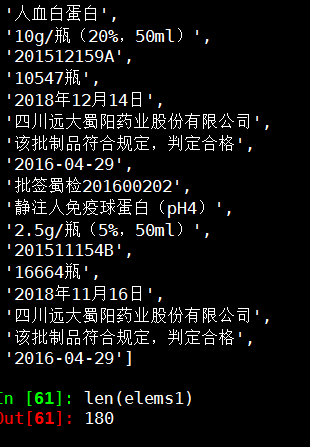
'批签蜀检201600202',
'静注人免疫球蛋白(pH4)',
'2.5g/瓶(5%,50ml)',
'201511154B',
'16664瓶',
'2018年11月16日',
'四川远大蜀阳药业股份有限公司',
'该批制品符合规定,判定合格',
'2016-04-29'] len(elems1)
Out[61]: 180 ''' '''
content=elems[0].text
list_content=content.split("\n")
#列表内个数
num=len(list_content)
list_content2=list_content[3:num]
'''
selenium_采集药品数据的更多相关文章
- selenium_采集药品数据2_采集所有表格
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- selenium_采集药品数据1_采集第一页表格
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- C#+HtmlAgilityPack+XPath带你采集数据(以采集天气数据为例子)
第一次接触HtmlAgilityPack是在5年前,一些意外,让我从技术部门临时调到销售部门,负责建立一些流程和寻找潜在客户,最后在阿里巴巴找到了很多客户信息,非常全面,刚开始是手动复制到Excel, ...
- Gobblin采集kafka数据
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 找时间记录一下利用Gobblin采集kafka数据的过程,话不多说,进入正题 一.Gobblin ...
- API例子:用Python驱动Firefox采集网页数据
1,引言 本文讲解怎样用Python驱动Firefox浏览器写一个简易的网页数据采集器.开源Python即时网络爬虫项目将与Scrapy(基于twisted的异步网络框架)集成,所以本例将使用Scra ...
- Performance Monitor采集性能数据
Performance Monitor采集性能数据 Windows本身为我们提供了很多好用的性能分析工具,大家日常都使用过资源管理器,在里面能即时直观的看到CPU占用率.物理内存使用量等信息.此外新系 ...
- 【Android 应用开发】分析各种Android设备屏幕分辨率与适配 - 使用大量真实安卓设备采集真实数据统计
.主要是为了总结一下 对这些概念有个直观的认识; . 作者 : 万境绝尘 转载请注明出处 : http://blog.csdn.net/shulianghan/article/details/198 ...
- Android 音视频开发(四):使用 Camera API 采集视频数据
本文主要将的是:使用 Camera API 采集视频数据并保存到文件,分别使用 SurfaceView.TextureView 来预览 Camera 数据,取到 NV21 的数据回调. 注: 需要权限 ...
- 分析各种Android设备屏幕分辨率与适配 - 使用大量真实安卓设备采集真实数据统计
一. 数据采集 源码GitHub地址 : -- SSH : git@github.com:han1202012/DisplayTest.git; -- HTTP : https://github.co ...
随机推荐
- Sprint 冲刺第三阶段第6-10天
这几天一直都在整理我们之前的内容,检查会不会有细节问题.例如界面跳转.颜色等. 因为一直没办法找到guitub存放位置.于是在这里存放一些主代码. MainActivity.java package ...
- 开源RabbitMQ操作组件
开源RabbitMQ操作组件 对于目前大多的.NET项目,其实使用的技术栈都是差不多,估计现在很少用控件开发项目的了,毕竟一大堆问题.对.NET的项目,目前比较适合的架构ASP.NET MVC,ASP ...
- 7-Python3从入门到实战—基础之数据类型(字典-Dictionary)
Python从入门到实战系列--目录 字典的定义 字典是另一种可变容器模型,且可存储任意类型对象:使用键-值(key-value)存储,具有极快的查找速度: 字典的每个键值(key=>value ...
- Beta阶段敏捷冲刺二
一.举行站立式会议 1.当天站立式会议照片一张 2.团队成员报告 林楚虹 (1) 昨天已完成的工作:连接上数据库 (2) 今天计划完成的工作:修改学习界面单词获取 (3) 工作中遇到的困难:虽然前天询 ...
- 震旦199打印机扫描A4文件
1.需要扫描的A4文件放入输稿器 2.使用数据线将打印机.电脑连接 3.在电脑中右键打印机,选择扫描功能 4.如下图,选择选项后,点击扫描即可
- python数据相关性分析 (计算相关系数)
#-*- coding: utf-8 -*- #餐饮销量数据相关性分析 计算相关系数 from __future__ import print_function import pandas as pd ...
- k8s 1.9 安装
测试环境 主机 系统 master CentOS 7.3 node CentOS 7.3 2.关闭selinux(所有节点都执行) [root@matser ~]# getenforce Disabl ...
- python之tkinter使用-Grid(网格)布局管理器
# 使用tkinter编写登录窗口 # Grid(网格)布局管理器会将控件放置到一个二维的表格里,主控件被分割为一系列的行和列 # stricky设置对齐方式,参数N/S/W/E分别表示上.下.左.右 ...
- BZOJ1030[JSOI2007]文本生成器——AC自动机+DP
题目描述 JSOI交给队员ZYX一个任务,编制一个称之为“文本生成器”的电脑软件:该软件的使用者是一些低幼人群,他们现在使用的是GW文本生成器v6版.该软件可以随机生成一些文章―――总是生成一篇长度固 ...
- 【Linux】memcache和memcached的自动安装
赶时间所以写一个简单的一个脚本,没有优化,想优化的可以学习下shell,自己优化下. 且行且珍惜,源码包+脚本领取处 链接:https://pan.baidu.com/s/1wIFR1wY-luDKs ...