机器学习——利用K-均值聚类算法对未标注数据分组
聚类是一种无监督的学习,它将相似的对象归到同一簇中。它有点像全自动分类。聚类方法几乎可以应用到所有对象,簇内的对象越相似,聚类的效果越好。
K-均值(K-means)聚类算法,之所以称之为K-均值是因为它可以发现k个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成。
簇识别(cluster identification)给出簇类结果的含义。假定有一些数据,现在将相似数据归到一起,簇识别会告诉我们这些簇到底都是些什么。
K-均值聚类算法
优点:容易实现
缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢
使用数据类型:数值型数据
K-均值是发现给定数据集的k个簇的算法。簇个数k是用户给定的,每一个簇通过其质心(centroid),即簇中所有点的中心来描述。
K-均值算法的工作流程是:
1.随机确定k个初始点作为质心
2.然后将数据集中的每个点分配到一个簇中,具体来讲,为每个点找到其最近的质心,并将其分配给该质心所对应的簇。
3.完成之后,每个簇的质心更新为该簇所有点的平均值。

原数据

from numpy import * def loadDataSet(fileName): #general function to parse tab -delimited floats
dataMat = [] #assume last column is target value
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = map(float,curLine) #map all elements to float()
dataMat.append(fltLine)
return dataMat def plotBestFit(file,clusterAssment): #画出数据集
import matplotlib.pyplot as plt
dataMat=loadDataSet(file) #数据矩阵和标签向量
dataArr = array(dataMat) #转换成数组
n = shape(dataArr)[0]
xcord1 = []; ycord1 = [] #声明两个不同颜色的点的坐标
xcord2 = []; ycord2 = []
for i in range(n): #绘出两个簇的聚类图
if (clusterAssment[i,0] == 0):
xcord1.append(dataArr[i,0]); ycord1.append(dataArr[i,1])
elif (clusterAssment[i,0] == 1):
xcord2.append(dataArr[i,0]); ycord2.append(dataArr[i,1])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='green', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='red')
plt.xlabel('X1'); plt.ylabel('X2');
plt.show() def distEclud(vecA, vecB): #计算两个向量的欧氏距离
return sqrt(sum(power(vecA - vecB, 2))) #la.norm(vecA-vecB) def randCent(dataSet, k): #为给定数据集构建一个包含k个随机质心的集合
n = shape(dataSet)[1]
centroids = mat(zeros((k,n)))
for j in range(n): #在n维向量中选出k个随机质心
minJ = min(dataSet[:,j])
rangeJ = float(max(dataSet[:,j]) - minJ) #分别求出X轴和Y轴的最大最小值之差
centroids[:,j] = mat(minJ + rangeJ * random.rand(k,1))
return centroids #返回k×n矩阵 def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent): #K-均值聚类算法
m = shape(dataSet)[0] #取得数据集的数量
clusterAssment = mat(zeros((m,2))) #簇分配结果矩阵,第一列记录簇索引值,第二列存储误差
centroids = createCent(dataSet, k) #生成初始质心
clusterChanged = True
while clusterChanged:
clusterChanged = False #停止条件
for i in range(m): #把每一个点分配到最近的簇中
minDist = inf; minIndex = -1
for j in range(k): #比较每一个点到两个簇的距离,把所有的点分成两个簇
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex: #只要有一个点被分配到另一个簇中,就重新计算质心后再次分配
clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2
#print centroids
for cent in range(k): #重新计算质心
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]] #取得给定簇的所有点
centroids[cent,:] = mean(ptsInClust, axis=0) #计算每个簇的均值,axis=0表示沿矩阵列方向进行均值计算
return centroids, clusterAssment #返回两个簇的质心、K-聚类结果以及误差
k=2,k-均值算法

k=4,k-均值算法
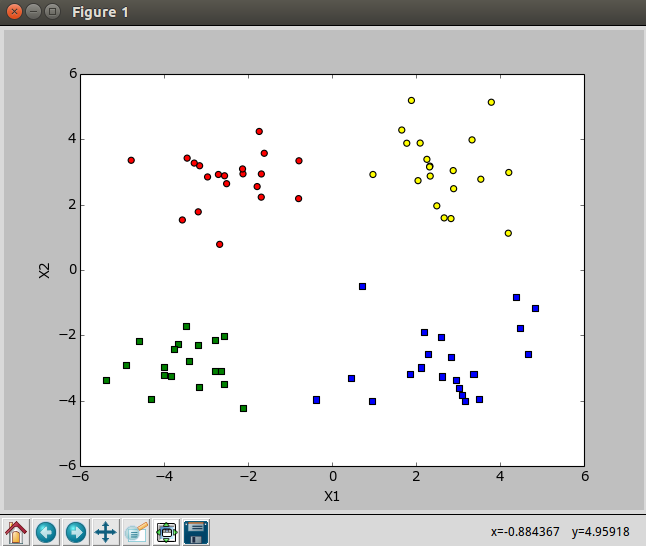
聚类的过程,较大的点表示质心




使用后处理来提高聚类性能
K-均值聚类中簇的数目k是一个用户预先定义的参数,用户需要知道怎么选取k值是正确的。
在包含簇分配结果的矩阵中保存这每个点的误差,即该点到簇质心的距离平方值,可以利用这个误差来评价聚类的质量。
一种用于度量聚类效果的指标是SSE(Sum of Squared Error,误差平方和)。SSE值越小表示数据点越接近于它们的质心,聚类效果也越好。因为对误差取了平方,因此桁架重视那些远离中心的点。
聚类的目标是在保持簇数不变的情况下提高簇的质量。
1.可以对生成的簇进行后处理,一种方式将具有最大SSE值的簇划分成两个簇。具体实现的时候,可以将最大簇包含的点过滤出来并在这些点上运行K-均值算法,其中的k设为2。
2.为了保持簇总数不变,可以将某两个簇进行合并。合并的方法是合并最近的质心,或者合并两个使得SSE增幅最小的质心。量化的方法有两种:
第一种思路是通过计算所有质心之间的距离,然后合并距离最近的两个点来实现。
第二种方法需要合并两个簇然后计算总SSE值。
必须在所有可能的两个簇上重复上述处理过程,知道找到合并最佳的两个簇为止。
二分K-均值算法
为克服K-均值算法收敛于局部最小值的问题,有人提出了另一个称为二分K-均值(bisecting K-mean)的算法。该算法首先将所有点作为一个簇,然后将该簇一分为二。之后选择其中一个簇继续进行划分,选择哪一个簇进行划分取决于对其划分是否可以最大程度降低SSE的值。上述基于SSE的划分过程不断重复,直达得到用户指定的簇数目为止。
另一种做法是选择SSE最大的簇进行划分,知道簇数目达到用户指定的数目为止。
def biKmeans(dataSet, k, distMeas=distEclud): #二分K-均值聚类算法
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
centroid0 = mean(dataSet, axis=0).tolist()[0] #计算每个簇的均值,axis=0表示沿矩阵列方向进行均值计算,并矩阵转换成列表
centList =[centroid0] #生成一个列表,存放初始质心(所有点的均值)
for j in range(m): #计算初始平方误差和
clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2
while (len(centList) < k): #当质心的数量还未达到用户设定的数量时
lowestSSE = inf
for i in range(len(centList)): #循环所有的簇,选取其中SSE最大的簇继续进行划分
ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:] #取得每一簇,初始只有一簇
centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas) #对每一簇进行2划分,centroidMat是质心,splitClustAss是划分索引
sseSplit = sum(splitClustAss[:,1]) #求SSE最大的簇进行2划分后的SSE和
sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1]) #求除SSE最大的簇之外的所有簇的SSE和
print "sseSplit, and notSplit: ",sseSplit,sseNotSplit
if (sseSplit + sseNotSplit) < lowestSSE: #把SSE最大的簇2划分之后的SSE总和与原来的SSE和进行比较
bestCentToSplit = i
bestNewCents = centroidMat
bestClustAss = splitClustAss.copy()
lowestSSE = sseSplit + sseNotSplit
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) #取出等于1的索引,令其等于新的簇,change 1 to 3,4, or whatever
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit #取出等于0的索引,令其等于SSE最大的簇
print 'the bestCentToSplit is: ',bestCentToSplit
print 'the len of bestClustAss is: ', len(bestClustAss)
print clusterAssment.T
raw_input()
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0] #replace a centroid with two best centroids
centList.append(bestNewCents[1,:].tolist()[0])
clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss#reassign new clusters, and SSE
return mat(centList), clusterAssment
机器学习——利用K-均值聚类算法对未标注数据分组的更多相关文章
- 机器学习:利用K-均值聚类算法对未标注数据分组——笔记
聚类: 聚类是一种无监督的学习,它将相似的对象归到同一个簇中.有点像全自动分类.聚类方法几乎可以应用于所有对象,簇内的对象越相似,聚类的效果越好.聚类分析试图将相似对象归入同一簇,将不相似对象归到不同 ...
- 无监督学习——K-均值聚类算法对未标注数据分组
无监督学习 和监督学习不同的是,在无监督学习中数据并没有标签(分类).无监督学习需要通过算法找到这些数据内在的规律,将他们分类.(如下图中的数据,并没有标签,大概可以看出数据集可以分为三类,它就是一个 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- 机器学习之K均值聚类
聚类的核心概念是相似度或距离,有很多相似度或距离的方法,比如欧式距离.马氏距离.相关系数.余弦定理.层次聚类和K均值聚类等 1. K均值聚类思想 K均值聚类的基本思想是,通过迭代的方法寻找K个 ...
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
随机推荐
- java编码过滤器
1.java编码过滤器的作用: java过滤器能够对目标资源的请求和响应进行截取,过滤信息执行的优先级高于servlet. 2.java过滤器的使用: (1)编写一个普通的java类,实现Filter ...
- mac maven
下载Maven 下载地址 : https://maven.apache.org/download.cgi 解压zip包到指定目录 例如: /Users/Walid/Desktop/develop/to ...
- Kali v2.1.2 for Raspberry Pi 3B
最新的下载地址是: https://www.offensive-security.com/kali-linux-arm-images/ 按照官网的说法是找不到树莓派版本的SHA1SUM和SHA1SUM ...
- redis参考文档
本文为之前整理的关于redis的文档,放到博客上一份,也方便我以后查阅. redis简介 Redis是一个开源的.高性能的.基于键值对的缓存与存储系统, 通过提供多种键值数据类型来适应不同场景下的缓存 ...
- [笔记]linux磁盘管理
sudo mount -r /dev/sda3 /mnt/vista 只读挂载 sudo umount sudo umount -r 无法卸载时只读重新挂载 mount -t(指明设备类型) 可用参数 ...
- Windows批处理:自动开关程序
公司有台14年组装的PC,时常无故重启,所以编写了个然并卵的批处理来测试稳定性. 打开程序.bat @echo off title Start Software color 2F : "C: ...
- 收集几个不错的最新win10系统64位和32位系统Ghost版下载
系统来自转载:系统妈 ◆ 版本特点 该版本安装后可利用微软公开的Windows10 KMS密钥激活,且右小角无版本水印. KMS客户端密钥:NPPR9-FWDCX-D2C8J-H872K-2YT43, ...
- 数组,集合分割函数,join()
join函数定义如下: // 串联类型为 System.String 的 System.Collections.Generic.IEnumerable<T> 构造集合的成员,其中在每个成员 ...
- ngx_http_core_module模块.md
Directives aio Syntax: aio on | off | threads[=pool]; Default: aio off; Context: http, server, locat ...
- 监控系统Opserver的配置调试
Stack Exchange开源其监控系统Opserver有一段时间了.之前在项目中用过他们的MiniProfile来分析页面执行效率和帮助新人了解项目,当他们开源了其监控系统的时候正好部门也在关注监 ...