NO.5 算法测试(词条统计)
一、安装Eclipse
下载Eclipse,解压安装,例如安装到/usr/local,即/usr/local/eclipse
4.3.1版本下载地址:http://pan.baidu.com/s/1eQkpRgu
如果插件安装成功,打开Windows—Preferences后,在窗口左侧会有Hadoop Map/Reduce选项,点击此选项,在窗口右侧设置Hadoop安装路径。

4、配置Map/Reduce Locations
打开Windows—Open Perspective—Other

在右下方看到如下图所示
点击Map/Reduce Location选项卡,点击右边小象图标,打开Hadoop Location配置窗口:
输入Location Name,任意名称即可.配置Map/Reduce Master和DFS Mastrer,Host和Port配置成与core-site.xml的设置一致即可。

点击"Finish"按钮,关闭窗口。
点击左侧的DFSLocations—>myhadoop(上一步配置的location name),如能看到user,表示安装成功

如果如下图所示表示安装失败,请检查Hadoop是否启动,以及eclipse配置是否正确。使用eclipse版本与jdk的版本对应,可以多安装几个jdk,灵活切换调用。

三、新建WordCount项目
File—>Project,选择Map/Reduce Project,输入项目名称WordCount等。
在WordCount项目里新建class,名称为WordCount,代码如下:

2、拷贝本地Test1.txt 到HDFS的input里
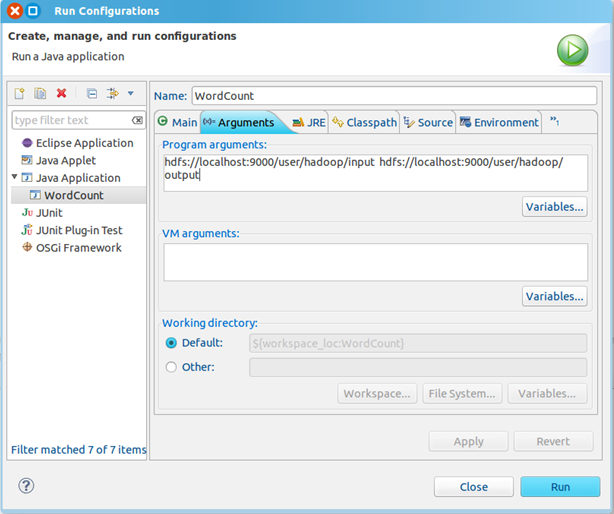
3、点击WordCount.java,右键,点击Run As—>Run Configurations,配置运行参数,即输入和输出文件夹
点击Run按钮,运行程序。

4、运行完成后,查看运行结果
方法2:
展开DFS Locations,如下图所示,双击打开part-r00000查看结果

////////////////////////////////////////////////////////////////////////////
(1)将文件拆分为splits,并由MapReduce框架自动完成分割,将每一个split分割为<key,value>对
(2)每一对<key,value>调用一次map函数,处理后生产新的<key,value>对,由Context传递给reduce处理
(3)Mapper对<key,value>对进行按key值进行排序,并执行Combine过程,将key值相同的value进行合并。最后得到Mapper的最终输出结果
NO.5 算法测试(词条统计)的更多相关文章
- AI算法测评(二)--算法测试流程
根据算法测试过程中遇到的一些问题和管理规范, 梳理出算法测试工作需要关注的一些点: 编号 名称 描述信息 备注 1 明确算法测试需求 明确测试目的 明确测试需求, 确认测试需要的数据及场景 明确算法服 ...
- 交易准实时预警 kafka topic 主题 异常交易主题 低延迟 event topic alert topic 内存 算法测试
https://www.ibm.com/developerworks/cn/opensource/os-cn-kafka/index.html 周 明耀2015 年 6 月 10 日发布 示例:网络游 ...
- Java实现 蓝桥杯VIP 算法提高 分数统计
算法提高 分数统计 时间限制:1.0s 内存限制:512.0MB 问题描述 2016.4.5已更新此题,此前的程序需要重新提交. 问题描述 给定一个百分制成绩T,将其划分为如下五个等级之一: 9010 ...
- AI大厂算法测试心得:人脸识别关键指标有哪些?
仅仅在几年前,程序员要开发一款人脸识别应用,就必须精通算法的编写.但现在,随着成熟算法的对外开放,越来越多开发者只需专注于开发垂直行业的产品即可. 由调查机构发布的<中国AI产业地图研究> ...
- 算法导论-顺序统计-快速求第i小的元素
目录 1.问题的引出-求第i个顺序统计量 2.方法一:以期望线性时间做选择 3.方法二(改进):最坏情况线性时间的选择 4.完整测试代码(c++) 5.参考资料 内容 1.问题的引出-求第i个顺序统计 ...
- 基于JaCoCo的Android测试覆盖率统计(二)
> 本文章是我上一篇文章的升级版本,详见地址:https://www.cnblogs.com/xiaoluosun/p/7234606.html ## 为什么要做这个?1. 辛辛苦苦写了几百条测 ...
- 08.手写KNN算法测试
导入库 import numpy as np from sklearn import datasets import matplotlib.pyplot as plt 导入数据 iris = data ...
- 计算机算法-C语言-统计字母数字个数解
Question:输入一串以“?”结尾的字符,分别统计其中字母数字的个数,输出字母及数字的个数. Solve: #include<stdio.h> #include<stdlib.h ...
- 算法打基础——顺序统计(找第k小数)
这次主要是讲如何在线性时间下找n个元素的未排序序列中第k小的数.当然如果\(k=1 or k=n\),即找最大最小 数,线性时间内遍历即可完成,当拓展到一般,如中位数时,相关算法就值得研究了.这里还要 ...
随机推荐
- BZOJ.3227.[SDOI2008]红黑树tree(树形DP 思路)
BZOJ orz MilkyWay天天做sxt! 首先可以树形DP:\(f[i][j][0/1]\)表示\(i\)个点的子树中,黑高度为\(j\),根节点为红/黑节点的最小红节点数(最大同理). 转移 ...
- [P3369]普通平衡树(Splay版)
模板,不解释 #include<bits/stdc++.h> using namespace std; const int mxn=1e5+5; int fa[mxn],ch[mxn][2 ...
- CY7C68013 USB接口相机开发记录 - 第三天:固件修改
上篇说了驱动怎么配置,这篇记录下对应的设备固件怎么配置.首先看下我们工程结构: 摘自官方文档AN61345 STARTUP.A51是建立工程时自动生成的文件,下面所有文件都是手动添加的.对于下面的几个 ...
- AsyncLocal<T>与ThreadLocal<T>区别研究
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- Flask 三方组件 Flask-Session
使用 from flask import session, Flask from flask_session import Session from redis import Redis app = ...
- docker 清理容器的命令
执行以下命令会彻底清除所有容器. docker rm -f $(docker ps -qa) rm -rf /var/lib/etcd /var/lib/cni /var/run/calico rm ...
- 经典SQL面试题(转)
以下题目都在MySQL上测试可行,有疏漏或有更优化的解决方法的话欢迎大家提出,我会持续更新的:) 有三个表,如果学生缺考,那么在成绩表中就不存在这个学生的这门课程成绩的记录,写一段SQL语句,检索出每 ...
- C#_02.14_基础五_.NET类
C#_02.14_基础五_.NET类 一.类实例: 我们前面说过类是一个模板,我们通过类创建一个又一个的实例,通常情况下类当中的变量是每一个实例都各有一份的,互相不影响,而静态字段是除外的,静态字段是 ...
- pygame 笔记-1 按键控制方块移动
背景:家里的娃慢慢长大了,准备教一些儿童入门的编程知识,研究了一阵麻省理工的scratch 2 虽然不错,但是功能有限,很多高级点的东西玩不出来.所以就有了这一系列,先提前自学一下,顺便拿来练手pyt ...
- 挖矿病毒 qW3xT.2 最终解决方案
转自:https://blog.csdn.net/hgx13467479678/article/details/82347473 1,cpu 100%, 用top 查看cpu100 2,删掉此进程 c ...