java中的ElasticSearch搜索引擎介绍。
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
安装
安装插件
ES工作原理
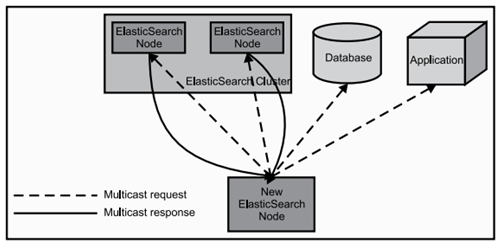
当ElasticSearch的节点启动后,它会利用多播(multicast)(或者单播,如果用户更改了配置)寻找集群中的其它节点,并与之建立连接。这个过程如下图所示:
官方代码
1 RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
new HttpHost("localhost", 9200, "http")));
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchSourceBuilder.aggregation(AggregationBuilders.terms("top_10_states").field("state").size(10));
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("social-*");
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest);
创建索引
/**
* 创建索引
*
* @param index
* @return
*/
public boolean createIndex(String index) {
if (!isIndexExist(index)) {
logger.info("index is not exits!");
}
CreateIndexResponse indexresponse = client.admin().indices().prepareCreate(index).execute().actionGet();
logger.info("success to create index " + indexresponse.isAcknowledged()); return indexresponse.isAcknowledged();
}
删除索引
/**
* 删除索引
*
* @param index
* @return
*/
public boolean deleteIndex(String index) {
if (!isIndexExist(index)) {
logger.info("index is not exits!");
}
DeleteIndexResponse dResponse = client.admin().indices().prepareDelete(index).execute().actionGet();
if (dResponse.isAcknowledged()) {
logger.info("delete index " + index + " successfully!");
} else {
logger.info("fail to delete index " + index);
}
return dResponse.isAcknowledged();
}
判断
/**
* 判断索引是否存在
*
* @param index
* @return
*/
public boolean isIndexExist(String index) {
IndicesExistsResponse inExistsResponse = client.admin().indices().exists(new IndicesExistsRequest(index)).actionGet();
if (inExistsResponse.isExists()) {
logger.info("index [" + index + "] is exist!");
} else {
logger.info("index [" + index + "] is not exist!");
}
return inExistsResponse.isExists();
}
/**
* 通过ID获取数据
*
* @param index 索引,类似数据库
* @param type 类型,类似表
* @param id 数据ID
* @param fields 需要显示的字段,逗号分隔(缺省为全部字段)
* @return
*/
public Map<String, Object> searchDataById(String index, String type, String id, String fields) {
GetRequestBuilder getRequestBuilder = client.prepareGet(index, type, id);
if (StringUtils.isNotEmpty(fields)) {
getRequestBuilder.setFetchSource(fields.split(","), null);
}
GetResponse getResponse = getRequestBuilder.execute().actionGet();
return getResponse.getSource();
} /**
* 使用分词查询
*
* @param index 索引名称
* @param type 类型名称,可传入多个type逗号分隔
* @param fields 需要显示的字段,逗号分隔(缺省为全部字段)
* @param matchStr 过滤条件(xxx=111,aaa=222)
* @return
*/
public List<Map<String, Object>> searchListData(String index, String type, String fields, String matchStr) {
return searchListData(index, type, 0, 0, null, fields, null, false, null, matchStr);
} /**
* 使用分词查询
*
* @param index 索引名称
* @param type 类型名称,可传入多个type逗号分隔
* @param fields 需要显示的字段,逗号分隔(缺省为全部字段)
* @param sortField 排序字段
* @param matchPhrase true 使用,短语精准匹配
* @param matchStr 过滤条件(xxx=111,aaa=222)
* @return
*/
public List<Map<String, Object>> searchListData(String index, String type, String fields, String sortField, boolean matchPhrase, String matchStr) {
return searchListData(index, type, 0, 0, null, fields, sortField, matchPhrase, null, matchStr);
} /**
* 使用分词查询
*
* @param index 索引名称
* @param type 类型名称,可传入多个type逗号分隔
* @param size 文档大小限制
* @param fields 需要显示的字段,逗号分隔(缺省为全部字段)
* @param sortField 排序字段
* @param matchPhrase true 使用,短语精准匹配
* @param highlightField 高亮字段
* @param matchStr 过滤条件(xxx=111,aaa=222)
* @return
*/
public List<Map<String, Object>> searchListData(String index, String type, Integer size, String fields, String sortField, boolean matchPhrase, String highlightField, String matchStr) {
return searchListData(index, type, 0, 0, size, fields, sortField, matchPhrase, highlightField, matchStr);
} /**
* 使用分词查询
*
* @param index 索引名称
* @param type 类型名称,可传入多个type逗号分隔
* @param startTime 开始时间
* @param endTime 结束时间
* @param size 文档大小限制
* @param fields 需要显示的字段,逗号分隔(缺省为全部字段)
* @param sortField 排序字段
* @param matchPhrase true 使用,短语精准匹配
* @param highlightField 高亮字段
* @param matchStr 过滤条件(xxx=111,aaa=222)
* @return
*/
public List<Map<String, Object>> searchListData(String index, String type, long startTime, long endTime, Integer size, String fields, String sortField, boolean matchPhrase, String highlightField, String matchStr) {
SearchRequestBuilder searchRequestBuilder = client.prepareSearch(index);
if (StringUtils.isNotEmpty(type)) {
searchRequestBuilder.setTypes(type.split(","));
}
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery(); if (startTime > 0 && endTime > 0) {
boolQuery.must(QueryBuilders.rangeQuery("processTime")
.format("epoch_millis")
.from(startTime)
.to(endTime)
.includeLower(true)
.includeUpper(true));
} //搜索的的字段
if (StringUtils.isNotEmpty(matchStr)) {
for (String s : matchStr.split(",")) {
String[] ss = s.split("=");
if (ss.length > 1) {
if (matchPhrase == Boolean.TRUE) {
boolQuery.must(QueryBuilders.matchPhraseQuery(s.split("=")[0], s.split("=")[1]));
} else {
boolQuery.must(QueryBuilders.matchQuery(s.split("=")[0], s.split("=")[1]));
}
}
}
} // 高亮(xxx=111,aaa=222)
if (StringUtils.isNotEmpty(highlightField)) {
HighlightBuilder highlightBuilder = new HighlightBuilder(); //highlightBuilder.preTags("<span style='color:red' >");//设置前缀
//highlightBuilder.postTags("</span>");//设置后缀 // 设置高亮字段
highlightBuilder.field(highlightField);
searchRequestBuilder.highlighter(highlightBuilder);
} searchRequestBuilder.setQuery(boolQuery); if (StringUtils.isNotEmpty(fields)) {
searchRequestBuilder.setFetchSource(fields.split(","), null);
}
searchRequestBuilder.setFetchSource(true); if (StringUtils.isNotEmpty(sortField)) {
searchRequestBuilder.addSort(sortField, SortOrder.DESC);
} if (size != null && size > 0) {
searchRequestBuilder.setSize(size);
} //打印的内容 可以在 Elasticsearch head 和 Kibana 上执行查询
// logger.info("\n{}", searchRequestBuilder); SearchResponse searchResponse = searchRequestBuilder.execute().actionGet(); long totalHits = searchResponse.getHits().totalHits;
long length = searchResponse.getHits().getHits().length; // logger.info("共查询到[{}]条数据,处理数据条数[{}]", totalHits, length); if (searchResponse.status().getStatus() == 200) {
// 解析对象
return setSearchResponse(searchResponse, highlightField);
}
return null;
} /**
* 使用分词查询,并分页
*
* @param index 索引名称
* @param type 类型名称,可传入多个type逗号分隔
* @param currentPage 当前页
* @param pageSize 每页显示条数
* @param startTime 开始时间
* @param endTime 结束时间
* @param fields 需要显示的字段,逗号分隔(缺省为全部字段)
* @param sortField 排序字段
* @param matchPhrase true 使用,短语精准匹配
* @param highlightField 高亮字段
* @param matchStr 过滤条件(xxx=111,aaa=222)
* @return
*/
public EsPage searchDataPage(String index, String type, int currentPage, int pageSize, long startTime, long endTime, String fields, String sortField, boolean matchPhrase, String highlightField, String matchStr) {
SearchRequestBuilder searchRequestBuilder = client.prepareSearch(index);
if (StringUtils.isNotEmpty(type)) {
searchRequestBuilder.setTypes(type.split(","));
}
searchRequestBuilder.setSearchType(SearchType.QUERY_THEN_FETCH); // 需要显示的字段,逗号分隔(缺省为全部字段)
if (StringUtils.isNotEmpty(fields)) {
searchRequestBuilder.setFetchSource(fields.split(","), null);
} //排序字段
if (StringUtils.isNotEmpty(sortField)) {
searchRequestBuilder.addSort(sortField, SortOrder.DESC);
} BoolQueryBuilder boolQuery = QueryBuilders.boolQuery(); if (startTime > 0 && endTime > 0) {
boolQuery.must(QueryBuilders.rangeQuery("@timestamp")
.format("epoch_millis")
.from(startTime)
.to(endTime)
.includeLower(true)
.includeUpper(true));
} // 查询字段
if (StringUtils.isNotEmpty(matchStr)) {
for (String s : matchStr.split(",")) {
String[] ss = s.split("=");
if (ss.length > 1) {
if (matchPhrase == Boolean.TRUE) {
boolQuery.must(QueryBuilders.matchPhraseQuery(s.split("=")[0], s.split("=")[1]));
} else {
boolQuery.must(QueryBuilders.matchQuery(s.split("=")[0], s.split("=")[1]));
}
}
}
} // 高亮(xxx=111,aaa=222)
if (StringUtils.isNotEmpty(highlightField)) {
HighlightBuilder highlightBuilder = new HighlightBuilder(); //highlightBuilder.preTags("<span style='color:red' >");//设置前缀
//highlightBuilder.postTags("</span>");//设置后缀 // 设置高亮字段
highlightBuilder.field(highlightField);
searchRequestBuilder.highlighter(highlightBuilder);
} searchRequestBuilder.setQuery(QueryBuilders.matchAllQuery());
searchRequestBuilder.setQuery(boolQuery); // 分页应用
searchRequestBuilder.setFrom(currentPage).setSize(pageSize); // 设置是否按查询匹配度排序
searchRequestBuilder.setExplain(true); //打印的内容 可以在 Elasticsearch head 和 Kibana 上执行查询
// logger.info("\n{}", searchRequestBuilder); // 执行搜索,返回搜索响应信息
SearchResponse searchResponse = searchRequestBuilder.execute().actionGet(); long totalHits = searchResponse.getHits().totalHits;
long length = searchResponse.getHits().getHits().length; // logger.debug("共查询到[{}]条数据,处理数据条数[{}]", totalHits, length); if (searchResponse.status().getStatus() == 200) {
// 解析对象
List<Map<String, Object>> sourceList = setSearchResponse(searchResponse, highlightField); return new EsPage(currentPage, pageSize, (int) totalHits, sourceList);
}
return null;
} /**
* 高亮结果集 特殊处理
*
* @param searchResponse
* @param highlightField
*/
private List<Map<String, Object>> setSearchResponse(SearchResponse searchResponse, String highlightField) {
List<Map<String, Object>> sourceList = new ArrayList<Map<String, Object>>();
StringBuffer stringBuffer = new StringBuffer(); for (SearchHit searchHit : searchResponse.getHits().getHits()) {
searchHit.getSource().put("id", searchHit.getId()); if (StringUtils.isNotEmpty(highlightField)) { System.out.println("遍历 高亮结果集,覆盖 正常结果集" + searchHit.getSource());
Text[] text = searchHit.getHighlightFields().get(highlightField).getFragments(); if (text != null) {
for (Text str : text) {
stringBuffer.append(str.string());
}
//遍历 高亮结果集,覆盖 正常结果集
searchHit.getSource().put(highlightField, stringBuffer.toString());
}
}
sourceList.add(searchHit.getSource());
}
return sourceList;
}
java中的ElasticSearch搜索引擎介绍。的更多相关文章
- Java中使用elasticsearch搜索引擎实现简单查询、修改等操作-已在项目中实际应用
以下的操作环境为:jdk:1.8:elasticsearch:5.2.0 maven架包下载坐标为: <dependency> <groupId>org.elasticsear ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- 三十八 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticse ...
- Java基础-JAVA中常见的数据结构介绍
Java基础-JAVA中常见的数据结构介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.什么是数据结构 答:数据结构是指数据存储的组织方式.大致上分为线性表.栈(Stack) ...
- 史上最全 Java 中各种锁的介绍
更多精彩原创内容请关注:JavaInterview,欢迎 star,支持鼓励以下作者,万分感谢. 锁的分类介绍 乐观锁与悲观锁 锁的一种宏观分类是乐观锁与悲观锁.乐观锁与悲观锁并不是特定的指哪个锁(J ...
- java中多线程入门有趣介绍
我们在网上可以看到所有有关于java的线程的基本概念的很多解释,不乏有很多详细经典的解释和代码解说.但是我们的很多初学者看完不能有一个直观的印象,特别是一些没有编程基础的学习者,很多时候要花很多时间去 ...
- java中数据流的简单介绍
java中的I/O操作主要是基于数据流进行操作的,数据流表示了字符或者字节的流动序列. java.io是数据流操作的主要软件包 java.nio是对块传输进行的支持 数据流基本概念 “流是磁盘或其它外 ...
- Java学习路线:Java中的位移运算符介绍
学习java本来就是一件日积月累的事情,或许你通过自学能掌握一些皮毛技术,学到java的一些基本大面,但想要做到精通,还是需要自己技术的日积月累和工作经验的不断积累. 今天给大家分享的技术知识是:ja ...
- Java中系统属性Properties介绍 System.getProperty()参数大全
在JDK文档中System类中有这样的方法getProperties()在此方法的详细介绍中有下面的参数可供使用: java.version Java 运行时环境版本 java.vendor J ...
随机推荐
- java直接生成zip压缩文件精简代码(跳过txt文件)
/** * @param args */ public static void main(String[] args) throws Exception{ ZipOutputStream zos = ...
- 几个常见的Mysql索引问题
1. 选择性较低的列是否适合加索引? 索引选择性等于列中不重复(distinct)的行数量(也叫基数),与记录总数的比值.范围在0-1之间.数值越大,索引越快. 例如主键是唯一的,不重复的,所以选择性 ...
- k8s(5)-拓展服务
在之前我们创建了一个部署,然后通过服务公开它.部署只创建了一个Pod来运行我们的应用程序.当流量增加时,我们需要扩展应用程序以满足用户需求. 通过更改部署中的副本数来完成扩展. 1. 拓展部署 这里将 ...
- OpenGL——天空盒子模型
加载天空盒子的六个jpg图片,不知道为什么加载不出顶部和底部的jpg图片.没有解决. 加载来自http://www.custommapmakers.org/skyboxes.php的tga图片,没有问 ...
- Windows下安装配置Yaf框架的方法及创建典型合理的Demo目录结构
Yaf是一个C语言编写的PHP框架,由鸟哥Laruence开发的高性能框架: Yaf官方文档:http://www.laruence.com/manual/index.html 第一步:安装PHP扩展 ...
- iOS - 如何得到UIImage的大小
把UIImage 转换为NSData,然后拿到NSData的大小 NSData * imageData = UIImageJPEGRepresentation(image,); length = [i ...
- CF1B Spreadsheets
题意翻译 人们常用的电子表格软件(比如: Excel)采用如下所述的坐标系统: 第一列被标为A,第二列为B,以此类推,第26列为Z.接下来为由两个字母构成的列号: 第27列为AA,第28列为AB... ...
- Map 嵌套存储Map
import java.util.HashMap;import java.util.Iterator;import java.util.Set;import java.util.Map.Entry; ...
- js中级小知识1
首先我们复习之前的小知识,本期博客与之前有关 js数据类型 基本数据类型:string undefined null boolean numbe ...
- height:100%
子元素的高度设置为height:100%时 继承父元素的高度为border+height 子元素的高度为height: 此时父元素的 box-sizing:content-box: border-bo ...