【2023微博评论爬虫】用python爬上千条微博评论,突破15页限制!
您好,我是@马哥python说,一枚10年程序猿。
一、爬取目标
前些天我分享过一篇微博的爬虫:
马哥python说:【python爬虫案例】爬取微博任意搜索关键词的结果,以“唐山打人”为例
但我的学习群中的小伙伴频繁讨论微博评论的爬取,所以,我们再分享这篇微博评论的爬虫。
注意区分这两个爬虫:
上次:爬指定搜索关键词的搜索结果的博文数据
本次:爬单一微博的微博下方评论数据
二、展示爬取结果
首先,看下部分爬取数据:

爬取字段含:
微博id、评论页码、评论id、评论时间、评论点赞数、评论者IP归属地、评论者姓名、评论者id、评论者性别、评论者关注数、评论者粉丝数、评论内容。
三、爬虫代码
上次在文章中讲到,微博有3种访问方式,分别是:
PC端网页:https://weibo.com/
移动端:https://weibo.cn/
手机端:https://m.weibo.cn/
本次依然采用第3种访问方式爬取,即,通过手机端爬取。
打开张天爱的目标微博:https://m.weibo.cn/detail/4806418774099867
URL地址中的"4806418774099867"就是微博id了。
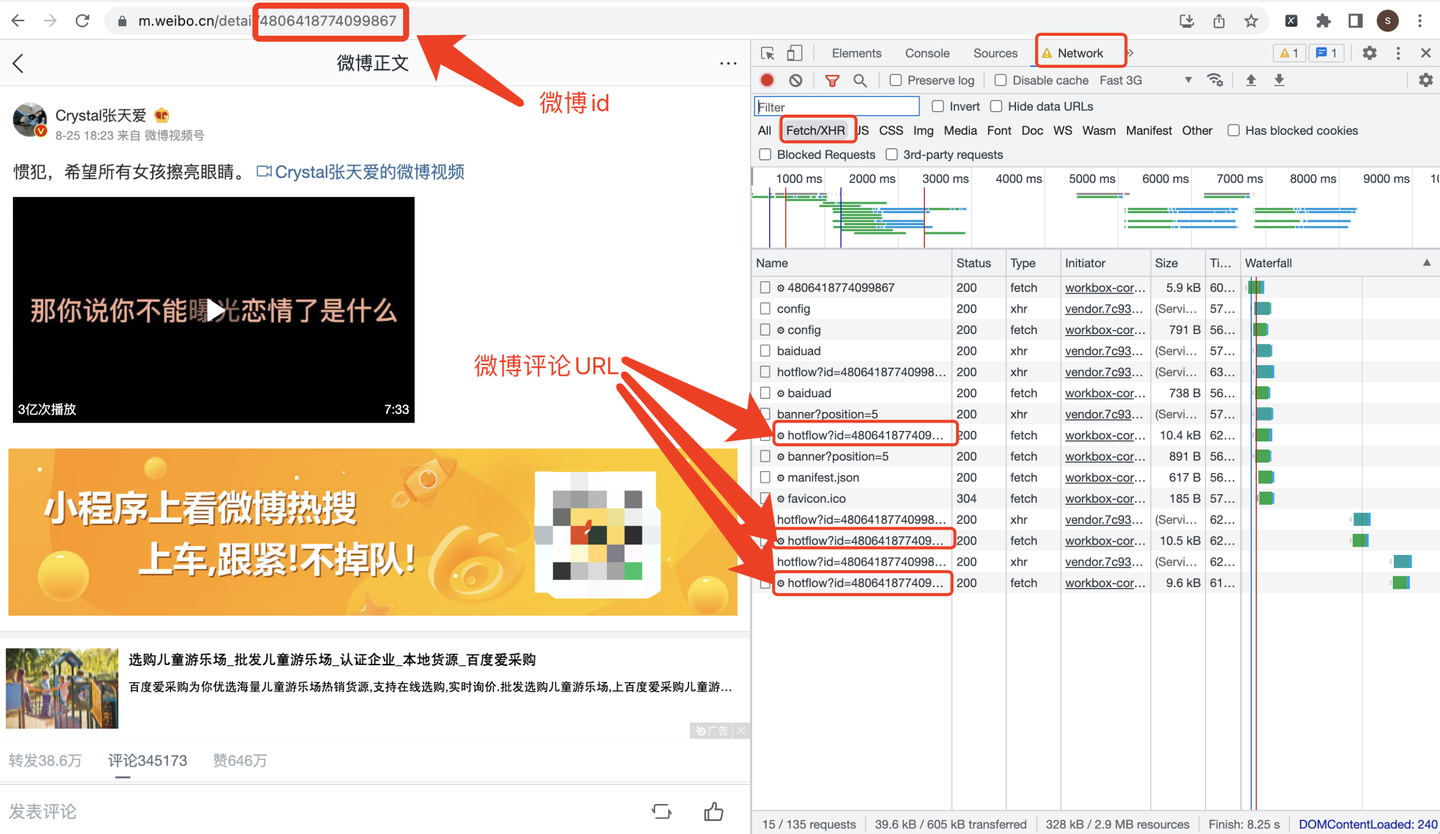
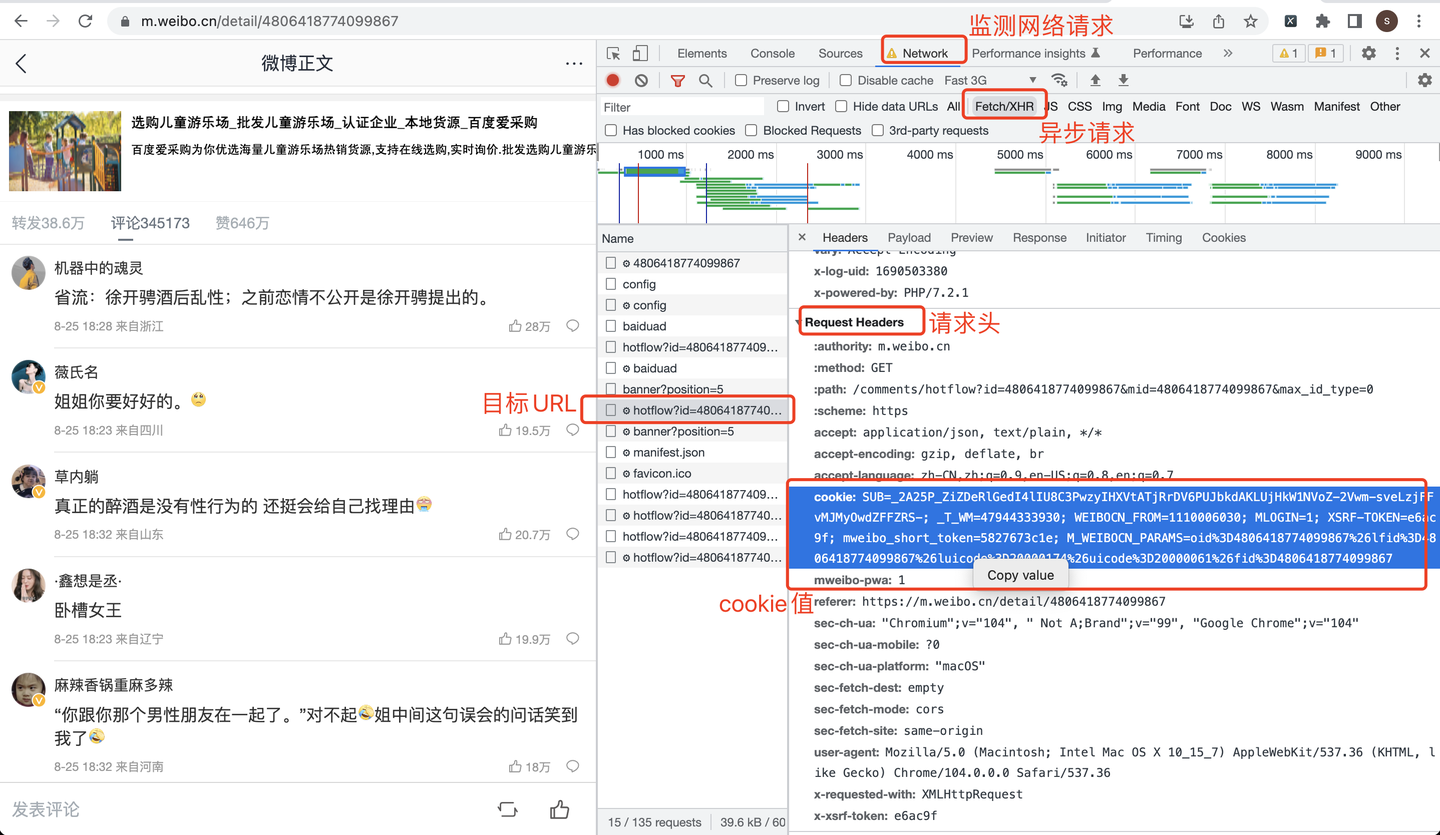
cookie从哪里获取呢?看截图:
把微博id带入到Python爬虫代码中,下面展示部分爬虫代码。
关键逻辑来了!
关键逻辑来了!
关键逻辑来了!
重要的事情说三遍,外加敲黑板!!
关键逻辑:(非常关键!如果处理不好,就只能爬到第1页,很多小伙伴卡在这了)
max_id的处理:
if page == 1: # 第一页,没有max_id参数
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id_type=0'.format(weibo_id, weibo_id)
else: # 非第一页,需要max_id参数
if max_id == '0': # 如果发现max_id为0,说明没有下一页了,break结束循环
print('max_id is 0, break now')
break
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id_type=0&max_id={}'.format(weibo_id,
weibo_id,
max_id)
如果是第一页,不用传max_id参数。
如果非第一页,需要传max_id参数,它的值来自于上一页的r.json()['data']['max_id']
下面,就是正常爬虫逻辑了。
首先,向微博页面发送请求:
r = requests.get(url, headers=headers) # 发送请求
print(r.status_code) # 查看响应码
print(r.json()) # 查看响应内容
下面,是解析数据的处理逻辑:
datas = r.json()['data']['data']
for data in datas:
page_list.append(page)
id_list.append(data['id'])
dr = re.compile(r'<[^>]+>', re.S) # 用正则表达式清洗评论数据
text2 = dr.sub('', data['text'])
text_list.append(text2) # 评论内容
time_list.append(trans_time(v_str=data['created_at'])) # 评论时间
like_count_list.append(data['like_count']) # 评论点赞数
source_list.append(data['source']) # 评论者IP归属地
user_name_list.append(data['user']['screen_name']) # 评论者姓名
user_id_list.append(data['user']['id']) # 评论者id
user_gender_list.append(tran_gender(data['user']['gender'])) # 评论者性别
follow_count_list.append(data['user']['follow_count']) # 评论者关注数
followers_count_list.append(data['user']['followers_count']) # 评论者粉丝数
最后,是保存数据的处理逻辑:
df = pd.DataFrame(
{
'微博id': [weibo_id] * len(time_list),
'评论页码': page_list,
'评论id': id_list,
'评论时间': time_list,
'评论点赞数': like_count_list,
'评论者IP归属地': source_list,
'评论者姓名': user_name_list,
'评论者id': user_id_list,
'评论者性别': user_gender_list,
'评论者关注数': follow_count_list,
'评论者粉丝数': followers_count_list,
'评论内容': text_list,
}
)
if os.path.exists(v_comment_file): # 如果文件存在,不再设置表头
header = False
else: # 否则,设置csv文件表头
header = True
# 保存csv文件
df.to_csv(v_comment_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
print('结果保存成功:{}'.format(v_comment_file))
篇幅有限,请求头、cookie、循环页码、数据清洗等其他细节不再赘述。
四、同步视频
详细讲解源码:
https://www.bilibili.com/video/BV1cd4y1R7Mf/
五、获取完整源码
附完整源码:【2023微博评论爬虫】用python爬上千条微博评论,突破15页限制!
推荐阅读:
微博评论分析大屏:马哥python说:【技术流吃瓜】python大屏分析"张天爱"微博网友评论
爬微博搜索结果:马哥python说:【python爬虫案例】爬取微博任意搜索关键词的结果,以“唐山打人”为例
【2023微博评论爬虫】用python爬上千条微博评论,突破15页限制!的更多相关文章
- python爬取网易云音乐评论及相关信息
python爬取网易云音乐评论及相关信息 urllib requests 正则表达式 爬取网易云音乐评论及相关信息 urllib了解 参考链接: https://www.liaoxuefeng.com ...
- XE中FMX操作ListBox,添加上千条记录(含图片)
我之前是想在ListBox的每个Item上添加一个图片,Item上所有的内容都是放在Object里赋值,结果发现加载一百条记录耗时四五秒: procedure TMainForm.AddItem; v ...
- python 爬取天猫美的评论数据
笔者最近迷上了数据挖掘和机器学习,要做数据分析首先得有数据才行.对于我等平民来说,最廉价的获取数据的方法,应该是用爬虫在网络上爬取数据了.本文记录一下笔者爬取天猫某商品的全过程,淘宝上面的店铺也是类似 ...
- python 爬取腾讯微博并生成词云
本文以延参法师的腾讯微博为例进行爬取并分析 ,话不多说 直接附上源代码.其中有比较详细的注释. 需要用到的包有 BeautifulSoup WordCloud jieba # coding:utf-8 ...
- 毕设二:python 爬取京东的商品评论
# -*- coding: utf-8 -*- # @author: Tele # @Time : 2019/04/14 下午 3:48 # 多线程版 import time import reque ...
- python 爬取腾讯视频评论
import urllib.request import re import urllib.error headers=('user-agent','Mozilla/5.0 (Windows NT 1 ...
- Python爬取10000条“爆款剧”——《三十而已》热评,并做可视化
前言 继<隐秘的角落>后,又一部“爆款剧”——<三十而已>获得了口碑收视双丰收,王漫妮.顾佳.钟晓芹三个女主角的故事线频频登上微博热搜.该剧于2020年7月17日在东方卫视首播 ...
- python脚本实现接口自动化轻松搞定上千条接口用例
接口自动化目前是测试圈主流的一个话题,我也在网上搜索了很多关于自动化的关键词,大多数博主分享的python做接口自动化都是以开源的框架,比如:pytest.unittest+ddt(数据驱动) 最常见 ...
- python爬取千库网
url:https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/ 有水印 但是点进去就没了 这里先来测试是否有反爬虫 import requests ...
- 将Excel上千条数据写入到数据库中
简要说明:因工作需要,需要一张Excel表格中的所有数据导入到数据库中.如下表,当然这只是一部分,一共一千多条. 前期处理: 首先要保证上图中的Excel表格中的数据不能为空,如果有为空的数据,可以稍 ...
随机推荐
- SpringCloud微服务集成Dubbo
1.Dubbo介绍 Apache Dubbo 是一款易用.高性能的 WEB 和 RPC 框架,同时为构建企业级微服务提供服务发现.流量治理.可观测.认证鉴权等能力.工具与最佳实践.用于解决微服务架构下 ...
- YOLOv4: 虽迟但到,大型调优现场,43mAP/83FPS | 论文速递
YOLOv4在速度和准确率上都十分优异,作者使用了大量的trick,论文也写得很扎实,在工程还是学术上都有十分重要的意义,既可以学习如何调参,也可以了解目标检测的trick. 来源:晓飞的算法工程 ...
- 化腐朽为神奇的QueryMapping
化腐朽为神奇的QueryMapping 老车除了报废没别的方法? 应用系统就像老车,经过十几二十年的使用,积累了大量里程数据,但是英雄迟暮,反应迟钝,时不时还要病休.但就这样报废,推到重来,如果没有充 ...
- KingbaseES V8R6集群运维案例--cluster模式备份sys_backup.sh init故障
KingbaseES V8R6集群运维案例--cluster模式备份sys_backup.sh init故障 案例说明: 通过脚本方式部署KingbaseES V8R6集群后,在'cluster'模式 ...
- KingbaseES 复制冲突之锁类型冲突
背景 昨天遇到客户现场的一个有关复制冲突的问题 备库报错:ERROR: canceling statement due to conflict with recovery,user was holdi ...
- Java实现哈希表
2.哈希表 2.1.哈希冲突 冲突位置,把数据构建为链表结构. 装载因子=哈希表中的元素个数 / (散列表)哈希表的长度 装载因子越大,说明链表越长,性能就越低,那么哈希表就需要扩容,把数据迁移到新的 ...
- #环#nssl 1487 图
题目 在一个\(n\)个节点\(n\)条边的连通图中, 每条边的权值为两个端点的权值的和. 已知各边权值,求各点权值 (保证环的大小一定是奇数) 分析 考虑断掉环的某一条边,设根节点的答案为\(ax+ ...
- #Tarjan,SPFA,差分约束系统#BZOJ 2330 AcWing 368 银河
题目 分析 首先这明显是一道差分约束题,但是无解的情况确实比较恶心, 考虑它的边权为0或1,无解当且仅当某个强连通分量内的边至少一条边边权为1, 那么用有向图的Tarjan缩点后跑SPFA就可以了 代 ...
- #深搜,期望#CF105B Dark Assembly
洛谷题目传送门 CODEFORCES传送门 分析 题目强调贿赂要在投票开始前完成说明分糖和成功率可以分开计算 那么分糖考虑直接暴搜,由于题目并没有说糖必须全部分完, 所以每一次分完一颗糖后均要求当前状 ...
- 密码学系列之:IDEA
密码学系列之:IDEA 目录 简介 IDEA简介 IDEA原理 IDEA子密钥的生成 简介 IDEA的全称是International Data Encryption Algorithm,也叫做国际加 ...