Python数据分析 DataFrame 笔记
08,DataFrame创建
DataFrame是一个【表格型】的数据结构,可以看做是【由Series组成的字典】(共用同一个索引)。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values(Numpy的二维数组)
(8.1)DataFrame的创建
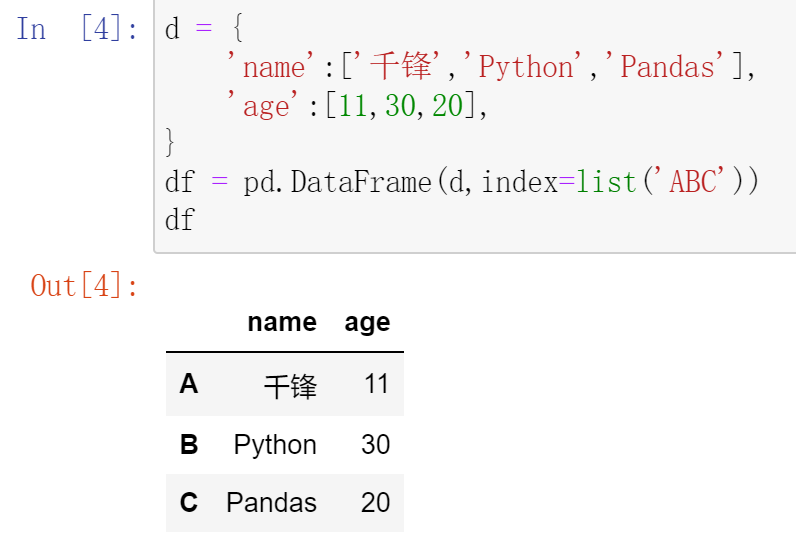
最常用的方法是传递一个字典来创建。DataFrame以字典的键作为每一【列】的名称,以字典的值(一个数组)作为每一列。此外,DataFrame会自动加上每一行的索引(和Series一样)。
同Series一样,若传入的列与字典的键不匹配,则相应的值为NaN。

DataFrame的基本属性和方法:
- values 值,二维ndarray数组
- columns 列索引
- index 行索引
- shape 形状
- head() 查看前几条数据,默认5条
- tail() 查看后几条数据,默认5条



其他创建DataFrame的方式

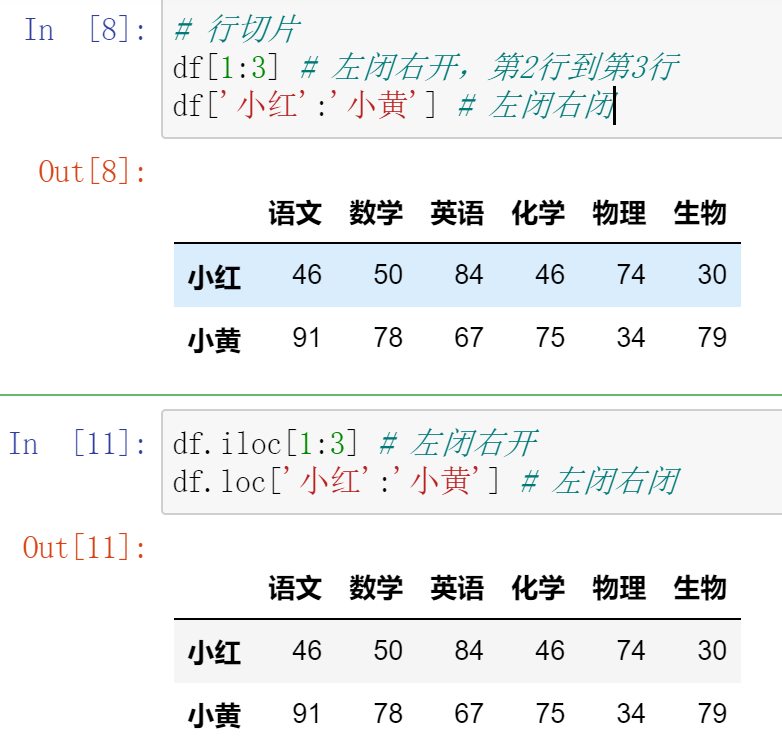
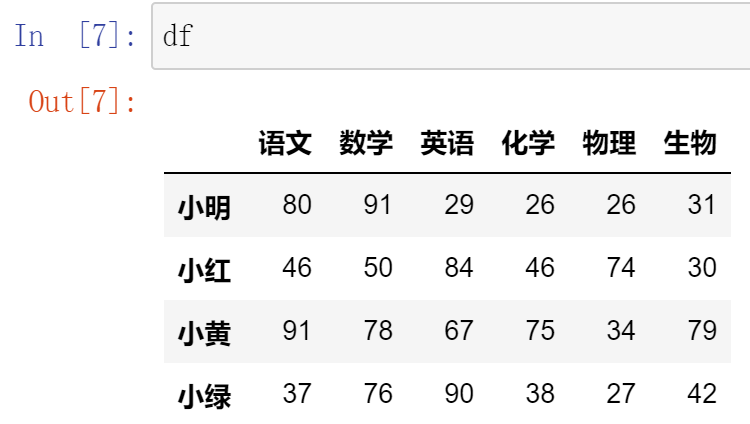
09,DataFrame切片
【注意】直接用中括号时:
- 索引优先对列进行操作
- 切片优先对行进行操作
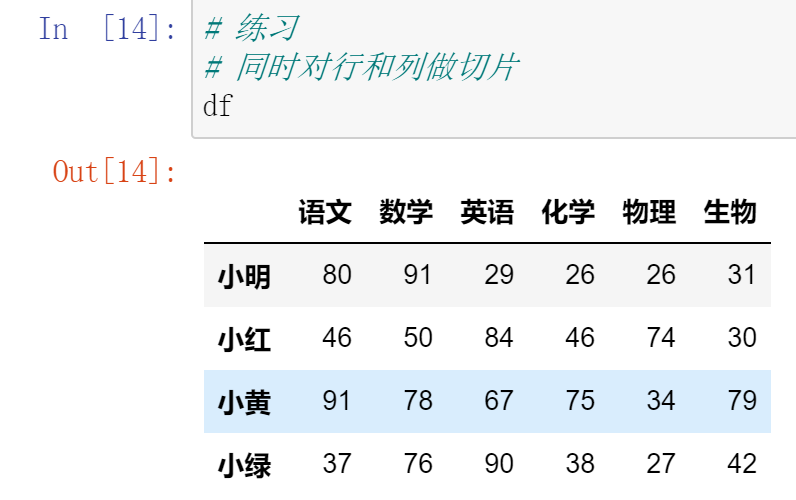
总结:
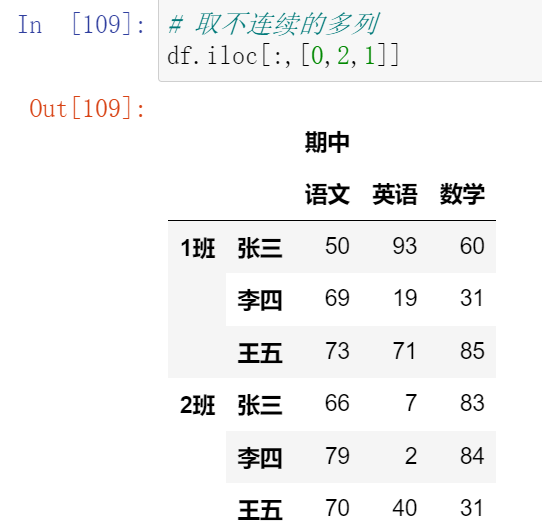
- 要么取一行或一列:索引
- 要么取连续的多行或多列:切片
- 要么取不连续的多行或多列:中括号
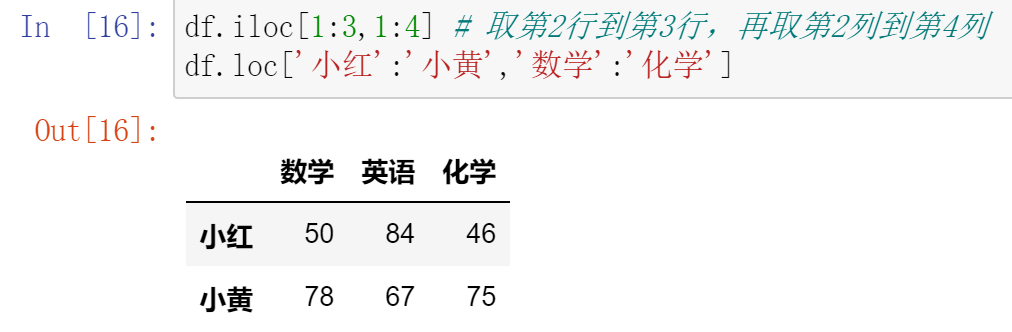
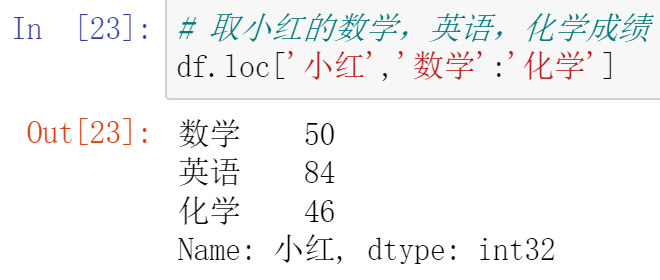

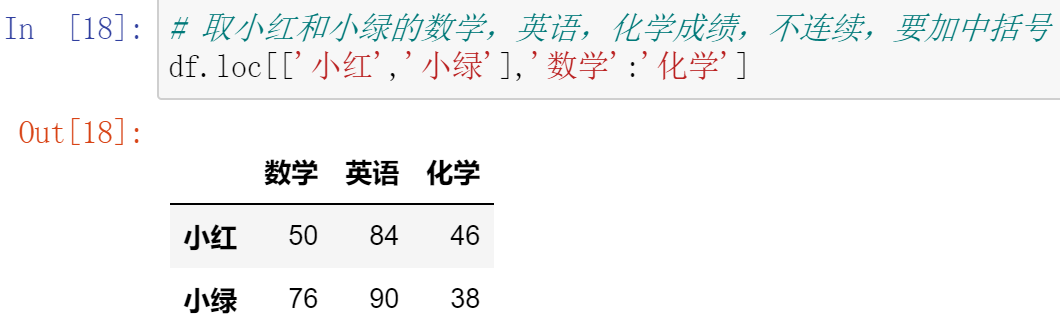


010,DataFrame运算
(10.1)DataFrame之间的运算
- 在运算中自动补齐不同索引的数据
- 如果索引不对应,则补NaN
- DataFrame没有广播机制
创建DataFrame df1 不同人员的各科目成绩,月考一

创建DataFrame df2 不同人员的各科目成绩,月考二

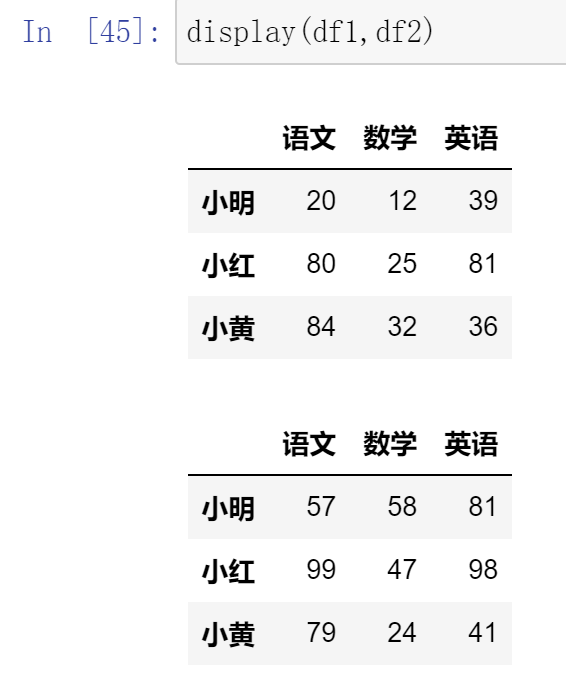
DataFrame和标量之间的运算
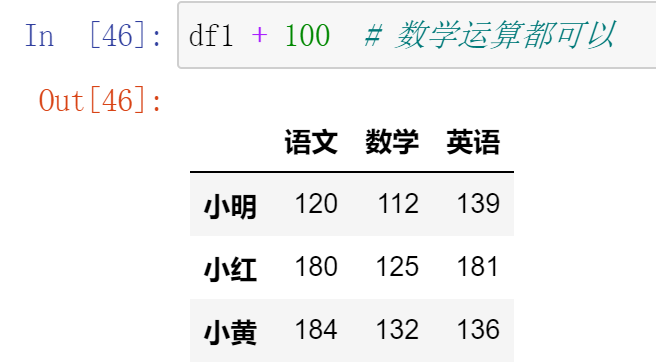
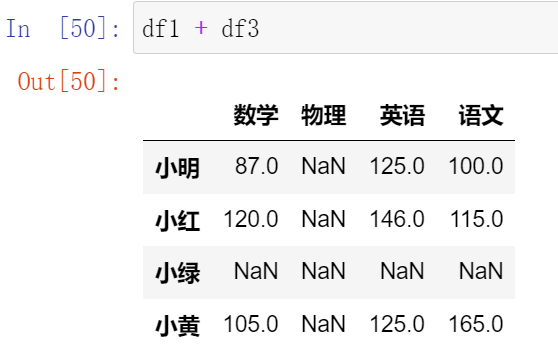
DataFrame之间的运算

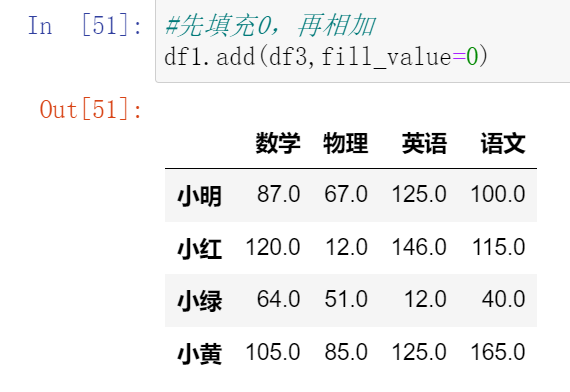
使用.add() 函数,填充数据

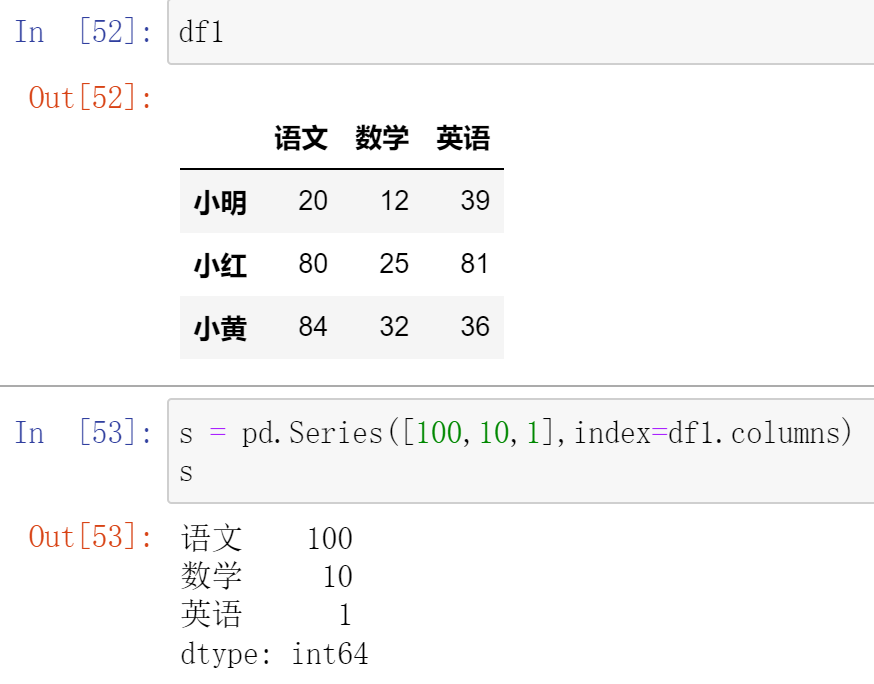
(10.2)Series与DataFrame之间的运算
- 使用Python操作符:以行为单位操作(参数必须是行),对所有行都有效。
- 类似于NumPy中二维数组与一维数组的运算,但可能出现NaN
- 使用Pandas操作函数:
- axis=0:以列为单位操作(参数必须为列),对所有列都有效。
- axis=1:以行为单位操作(参数必须为行),对所有行都有效。

011,创建层次化索引
(11.1)创建多层行索引
(11.1.1)隐式构造
最常见的方法是给DataFrame构造函数的index参数传递两个或更多的数组

- Series也可以创建多层索引

(11.1.2)显示构造pd.MultiIndex
- 使用数组

- 使用tuple

- 使用product
- 笛卡尔积

(11.2)多层列索引
除了行索引index,列索引columns也能用同样的方法创建多层索引
就是把pd.MultIndex. 移到columns那里去
012,多层索引中Series的索引和切片操作
(12.1)Series的操作
- 对于Series的操作,直接中括号[] 与使用.loc() 完全一样
(12.1.1)索引





(12.1.2)切片


013,多层索引中DataFrame的索引和切片操作
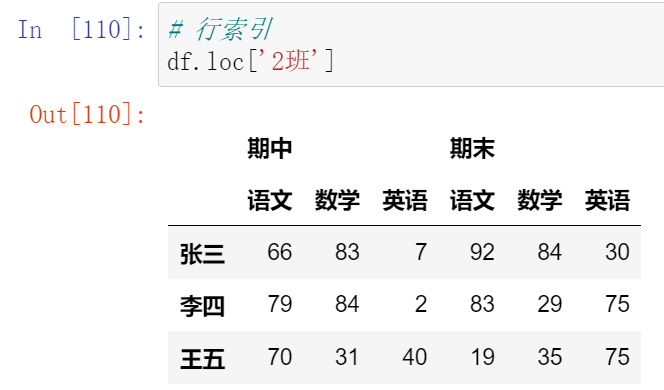
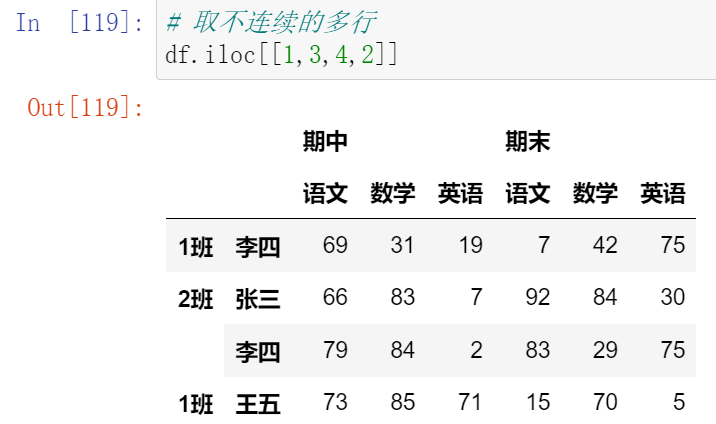
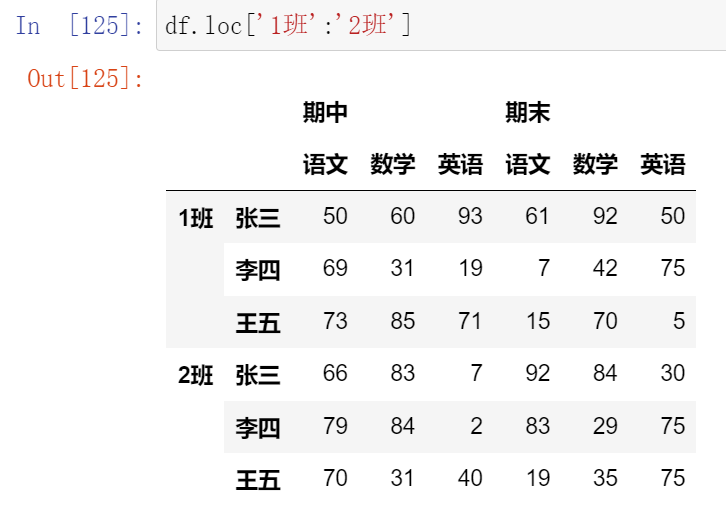
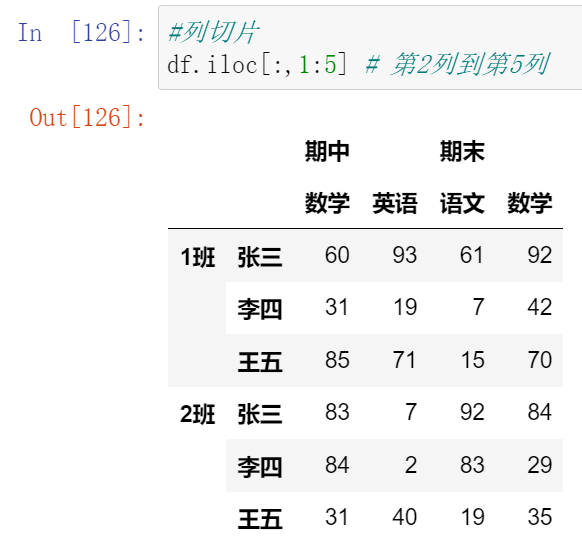
(13.1)索引
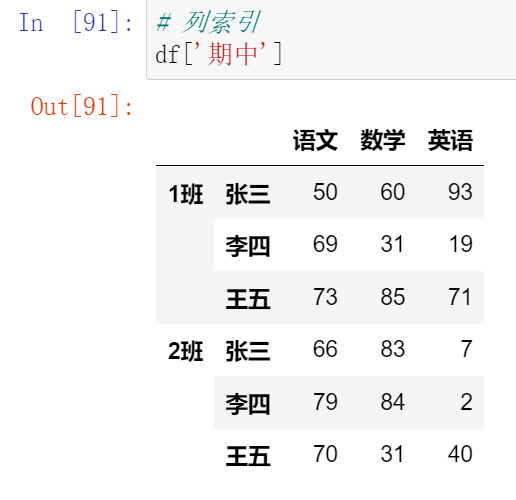
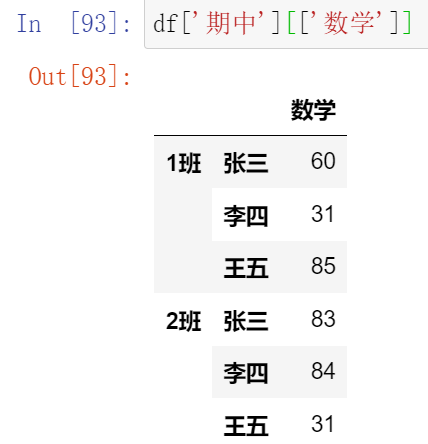

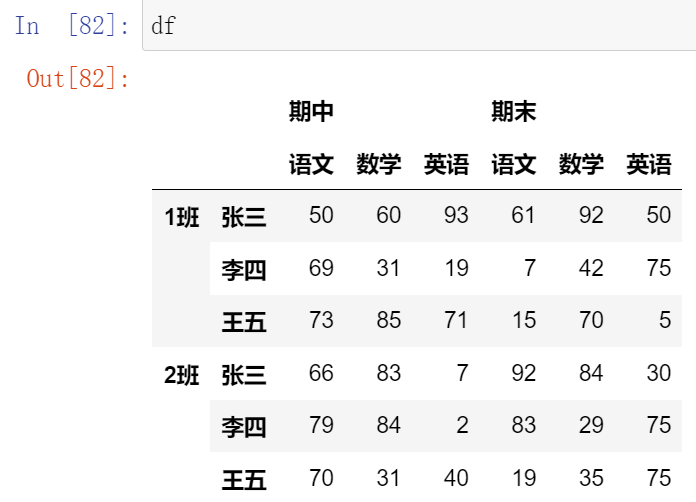


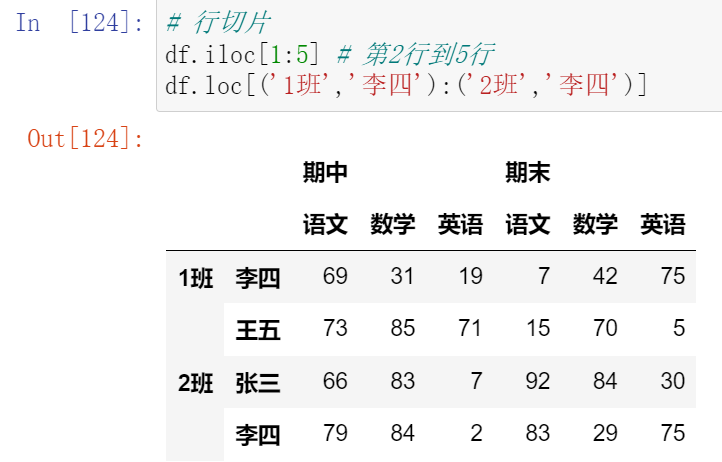
(13.2)切片

014,索引的堆叠

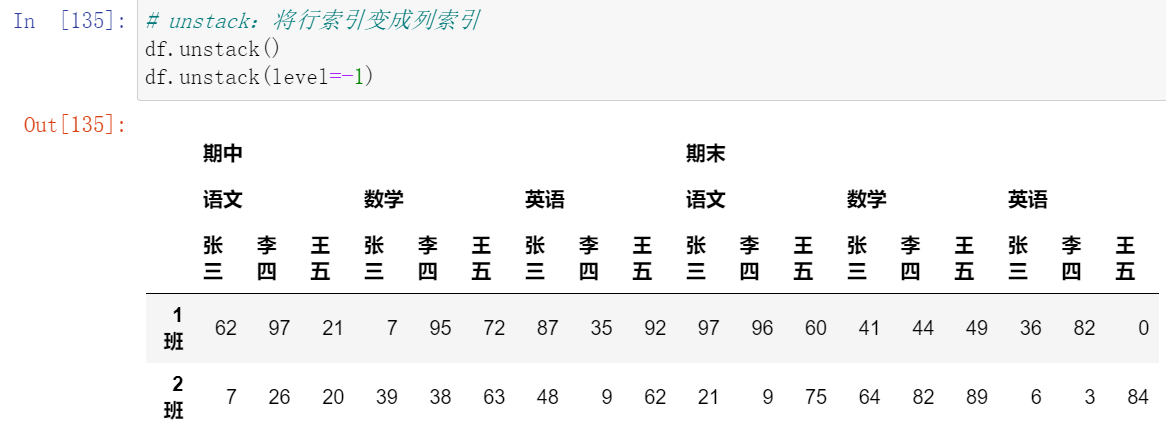
(14.1)stack():将列索引变成行索引

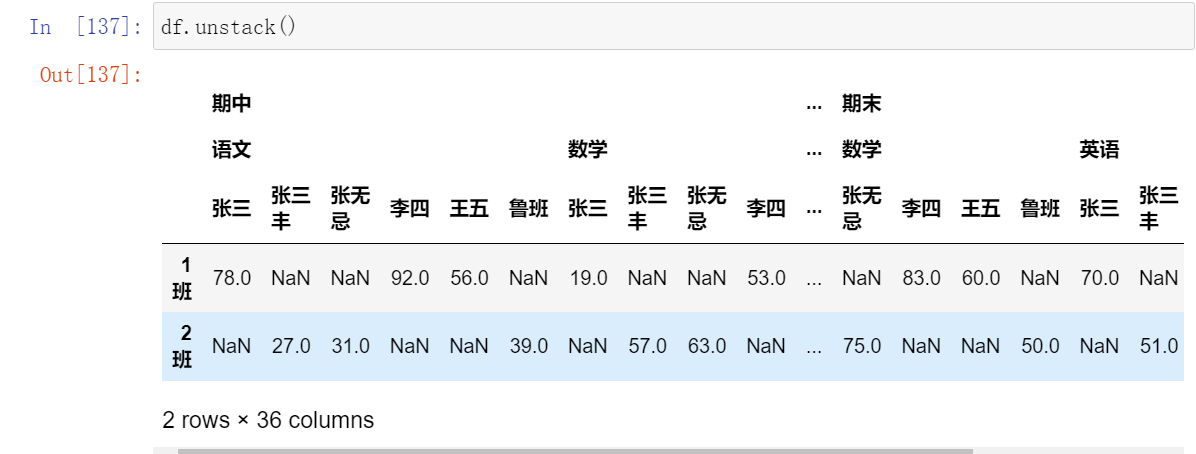
(14.2)unstack():将行索引变成列索引
(14.3)使用fill_value填充


015,聚合操作
(15.1)DataFrame聚合函数
- 求和
- 平均值
- 最大值
- 最小值等



(15.2)多层索引聚合操作

016,数据合并concat
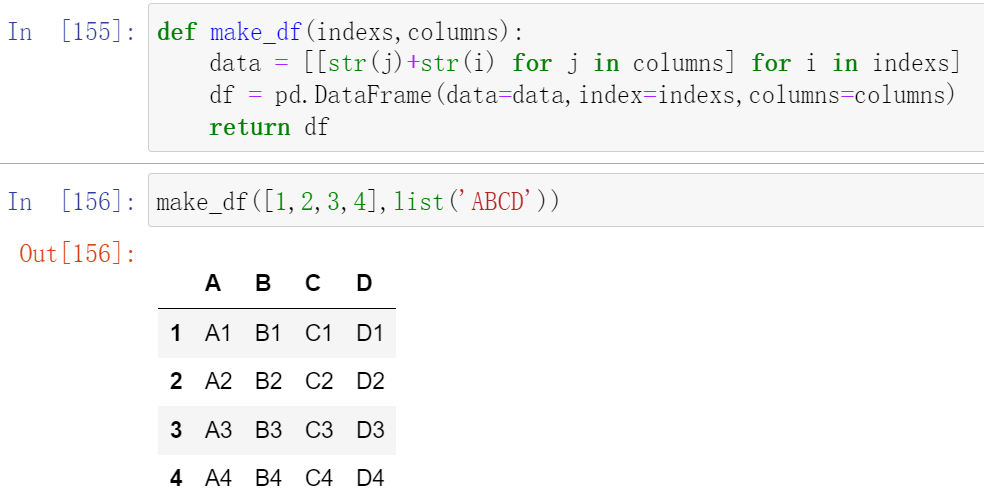
为方便讲解,我们首先定义一个生成DataFrame的函数:
示例:
使用pd.concat()级联
pandas使用pd.concat函数,与np.concatenate函数类似
(16.1)简单级联


忽略行索引 ignore_index

使用多层索引 keys

(16.2)不匹配级联
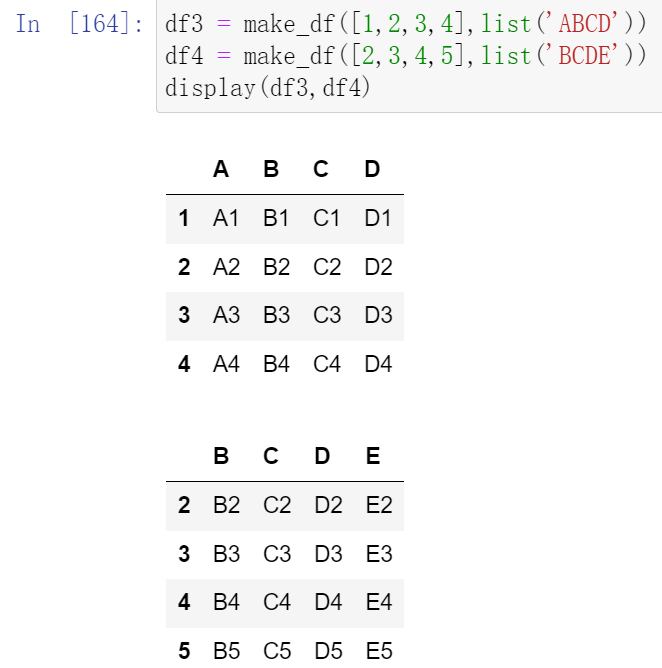
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致

外连接:补NaN(默认模式)

内连接:只连接匹配的项

017,数据合并merge合并1
- 类似于MySQL中表和表直接的合并
- merge与concat的区别在于,merge需要依据某一共同的行或列来进行合并
- 使用pd.merge() 合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
- 每一列元素的顺序不要求一致
(17.1)一对一合并

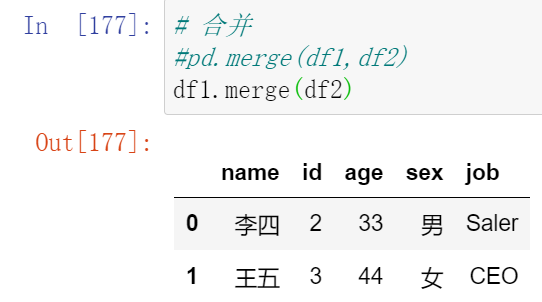
(17.2)多对一合并
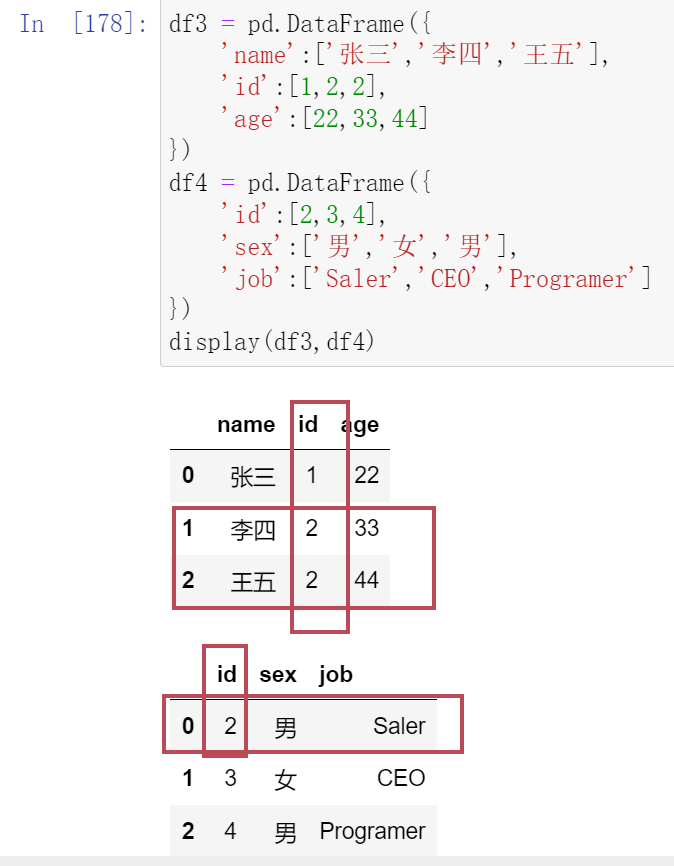

(17.3)多对多合并


(17.4)key的规范化
- 使用on = 显式指定哪一列为key,当2个DataFrame有多列相同时使用



- 使用left_on和right_on指定左右两边的列作为key,当左右两边的key都不相等时使用


- 当左边的列和右边的index相同的时候,使用right_index=True
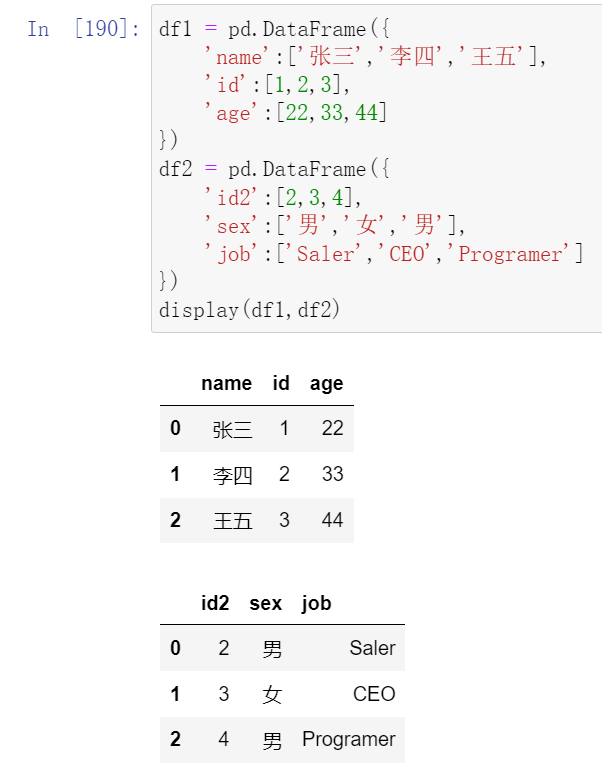
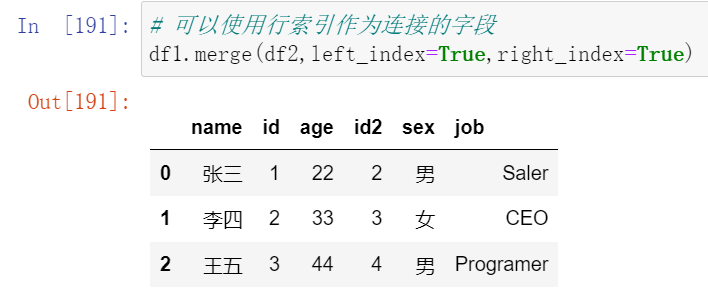
018,数据合并merge合并2
(18.1)内合并与外合并
- 内合并:只保留两者都有的key(默认模式)
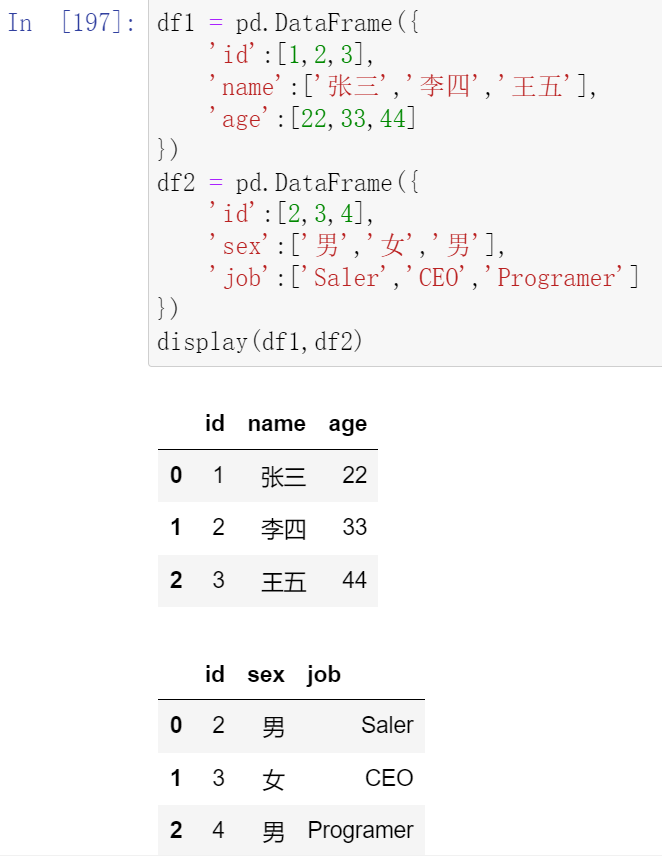

- 外合并 how='outer':补NaN
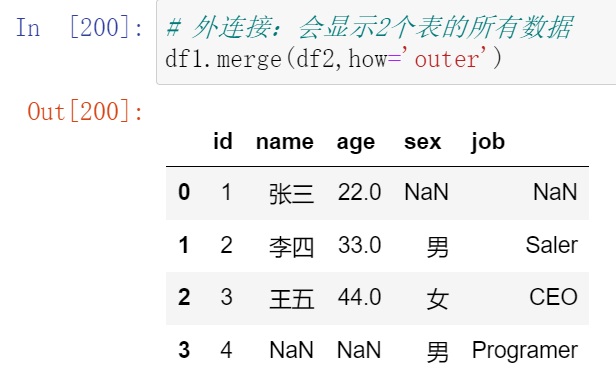
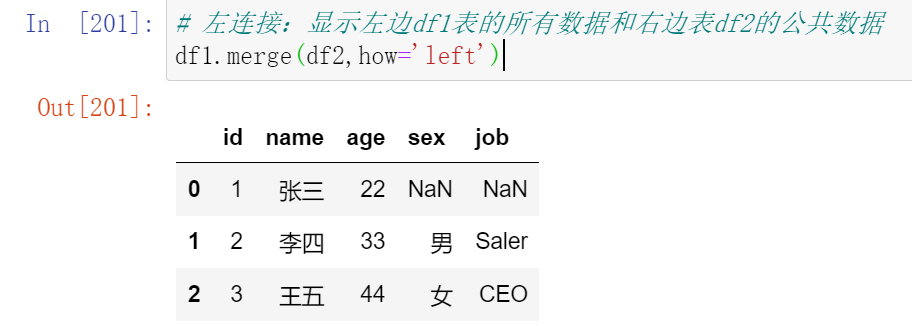
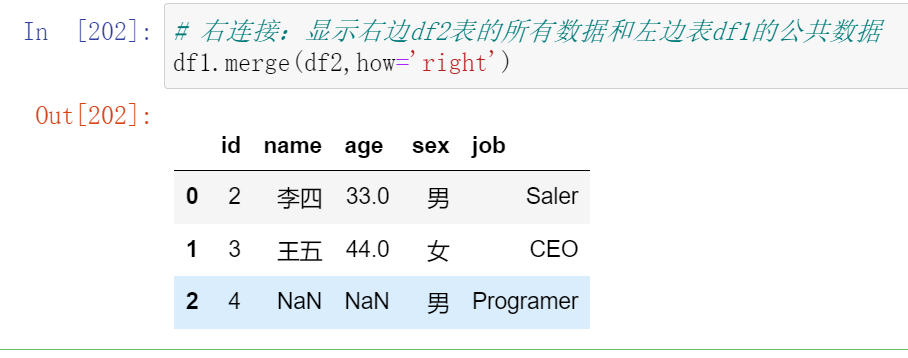
- 左合并,右合并:how='left',how='right'
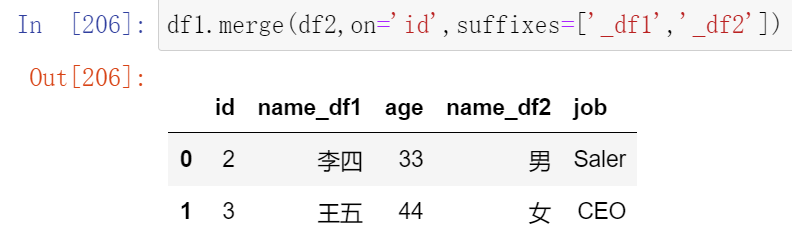
(18.2)列冲突的解决
当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个列作为key,配合suffixes指定冲突列名
可以使用suffixes=自己指定后缀

merge合并总结:
- 合并有三种现象:一对一,多对一,多对多。
- 合并默认会找相同的列名进行合并,如果有多个列名相同,用on来指定。
- 如果没有列名相同,但是数据又相同,可以通过left_on,right_on来分别指定要合并的列。
- 如果想和index合并,使用left_index,right_index来指定。
- 如果多个列相同,合并之后可以通过suffixes来区分。
- 还可以通过how来控制合并的结果,默认是内合并,还有外合并outer,左合并left,右合并right。
019,缺失值处理nan
np.nan是浮点类型,能参与到计算中。但计算的结果总是NaN。

020,缺失值检测
(20.1)Pandas中None与np.nan都视作np.nan
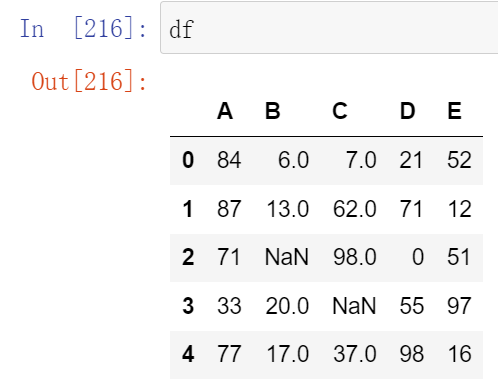
- 创建DataFrame

- 使用DataFrame行索引与列索引修改DataFrame数据


(20.2)pandas中None与np.nan的操作
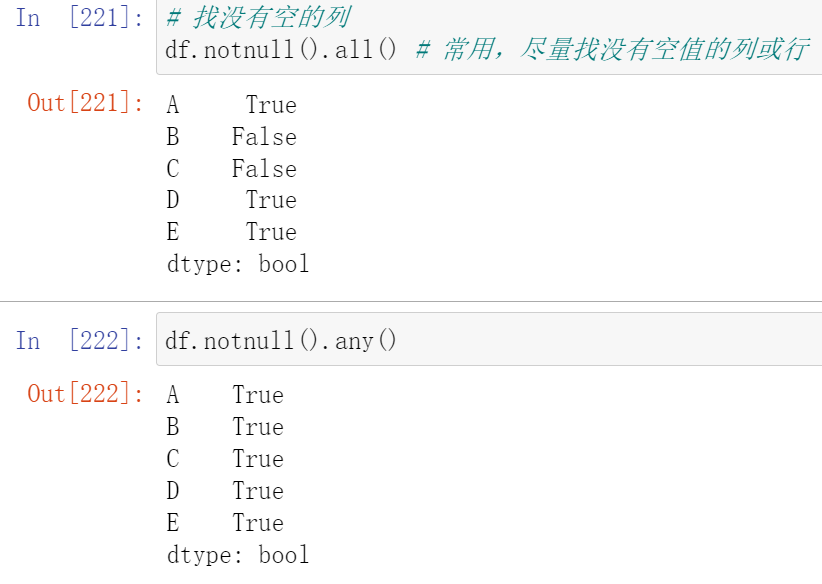
(20.2.1)判断函数
- isnull()
- notnull()



021,缺失值处理_过滤数据
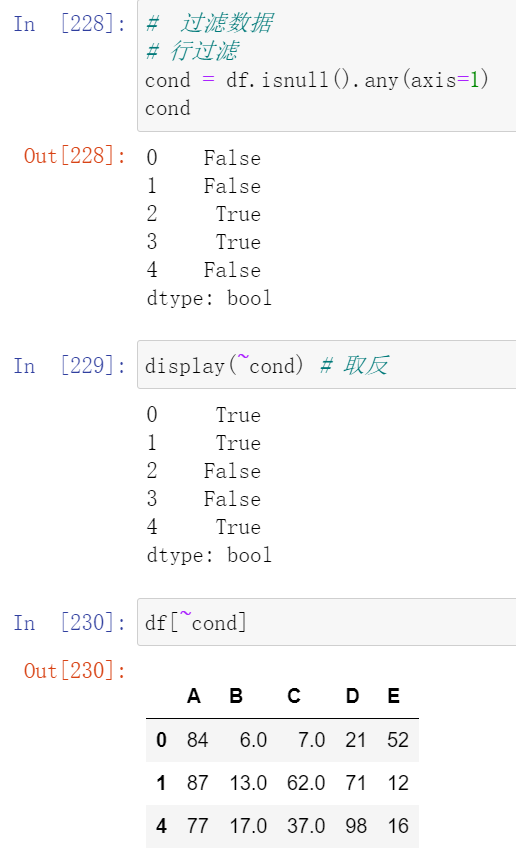
(21.1)使用bool值过滤数据
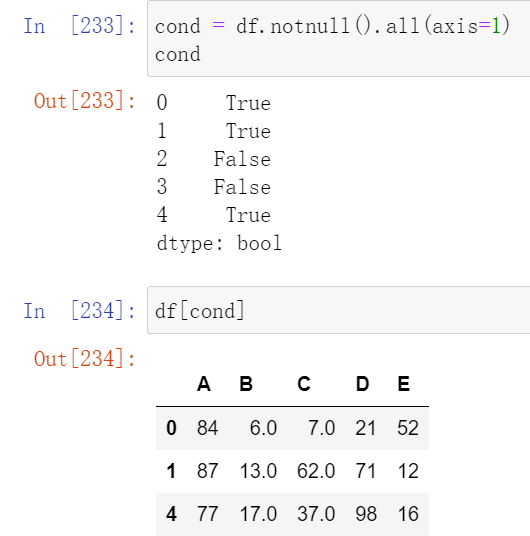
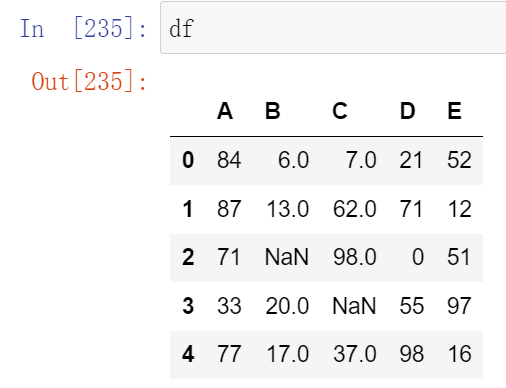
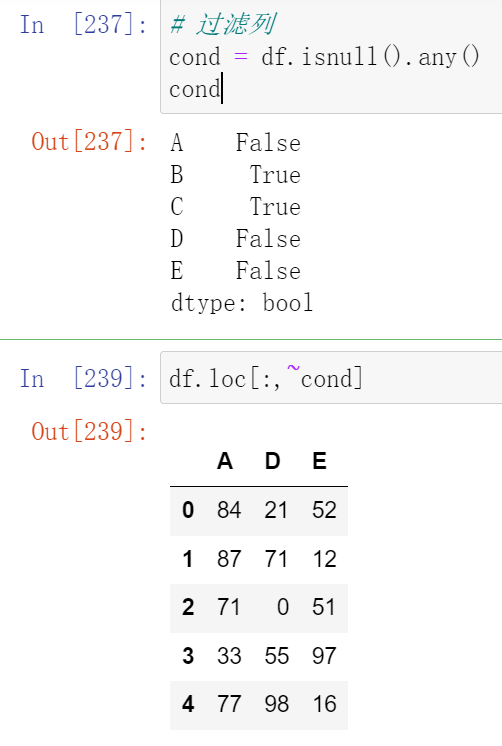

(21.2)过滤函数dropna
(21.2.1)可以选择过滤的是行还是列(默认为行)
ps:这里数据变了


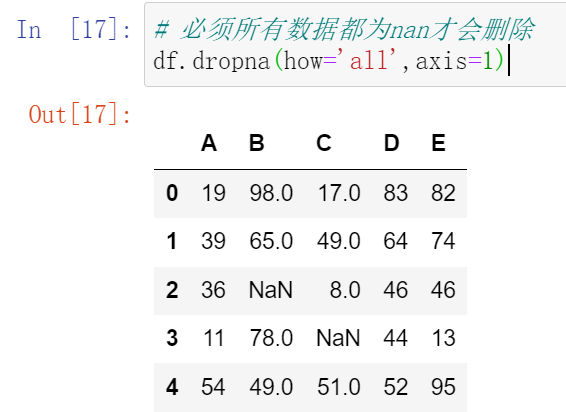
(21.2.2)也可以选择过滤的方式 how = 'all'
(21.2.3)inplace=True 修改原数据

022,缺失值处理_填充空值
(22.1)填充函数 fillna() Series/DataFrame
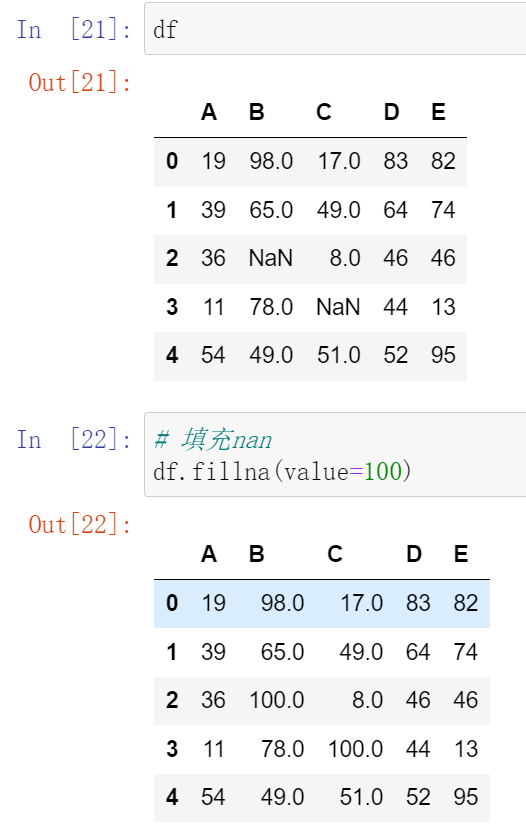
(22.2)可以选择前向填充还是后向填充
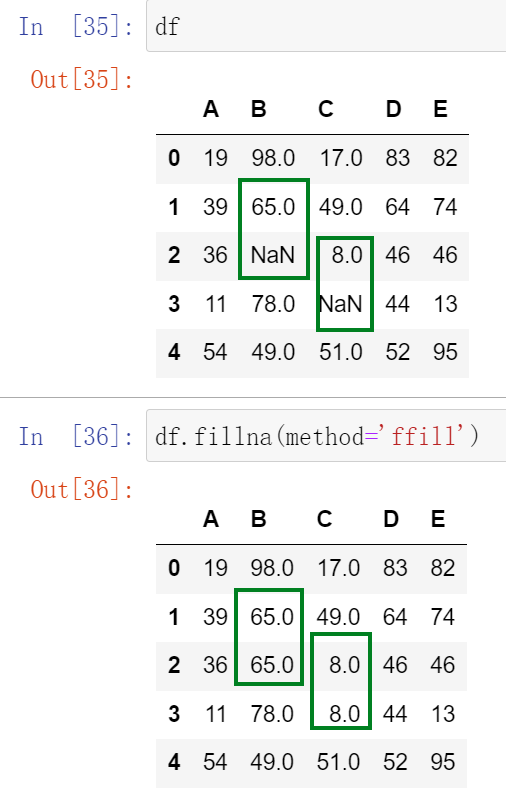

重新创建数据

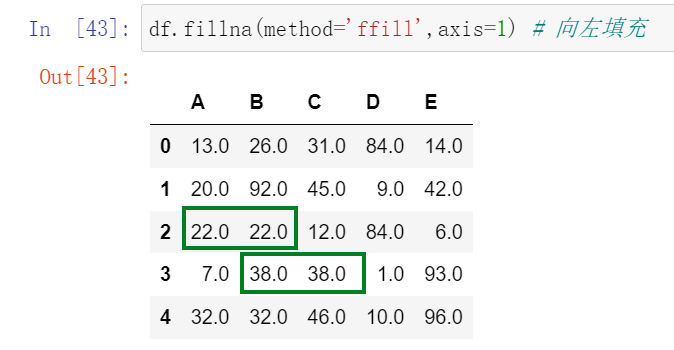
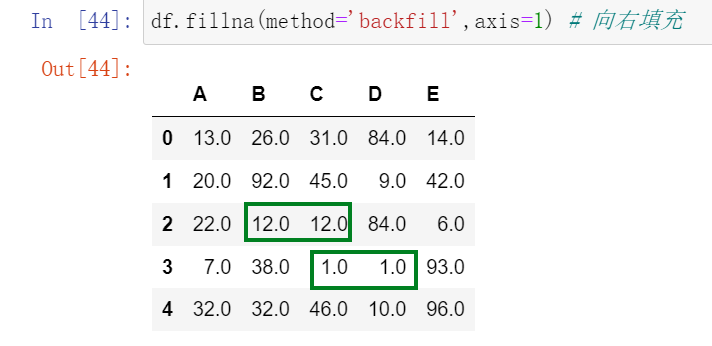
也可以不用重新创建数据,因为没有用到 inplace=True
023,重复值处理
(23.1)使用duplicated() 函数检测重复的行
- 返回元素为布尔类型的Series对象
- 每个元素对应一行,如果该行不是第一次出现,则元素为True




(23.2)使用drop_duplicates() 函数删除重复的行


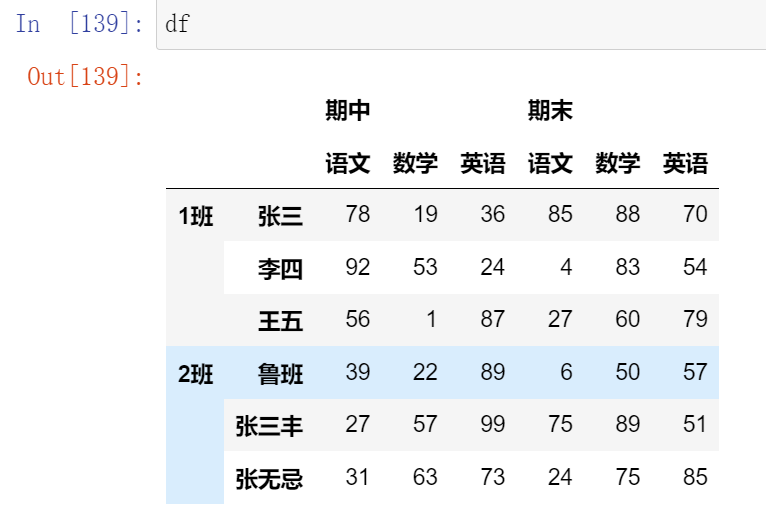
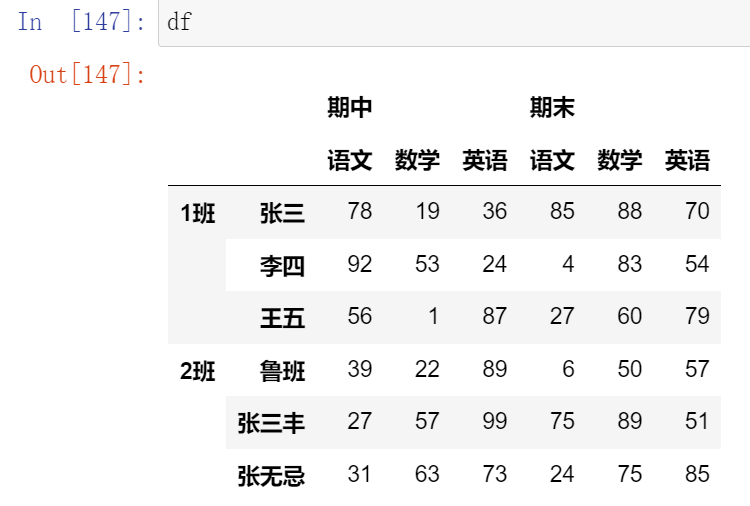
024,替换元素replace
使用replace() 函数,对values进行替换操作

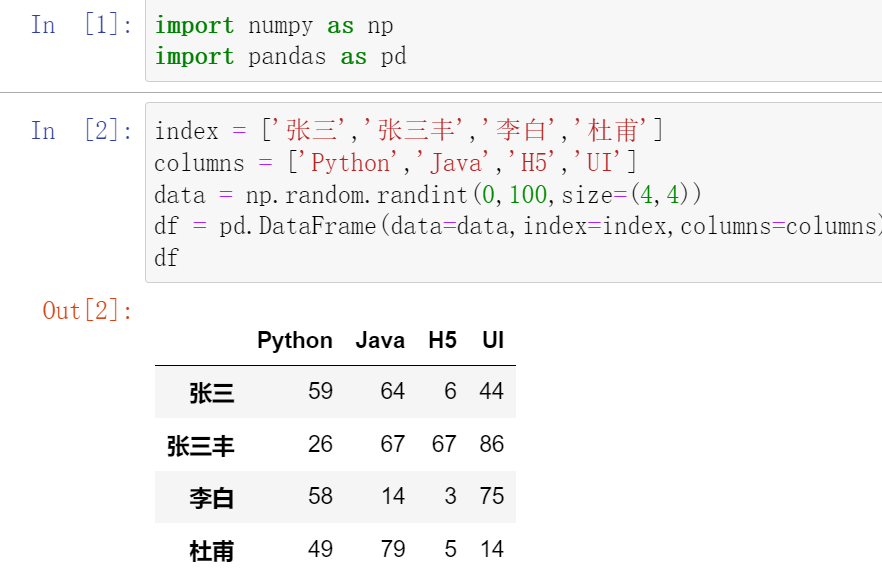
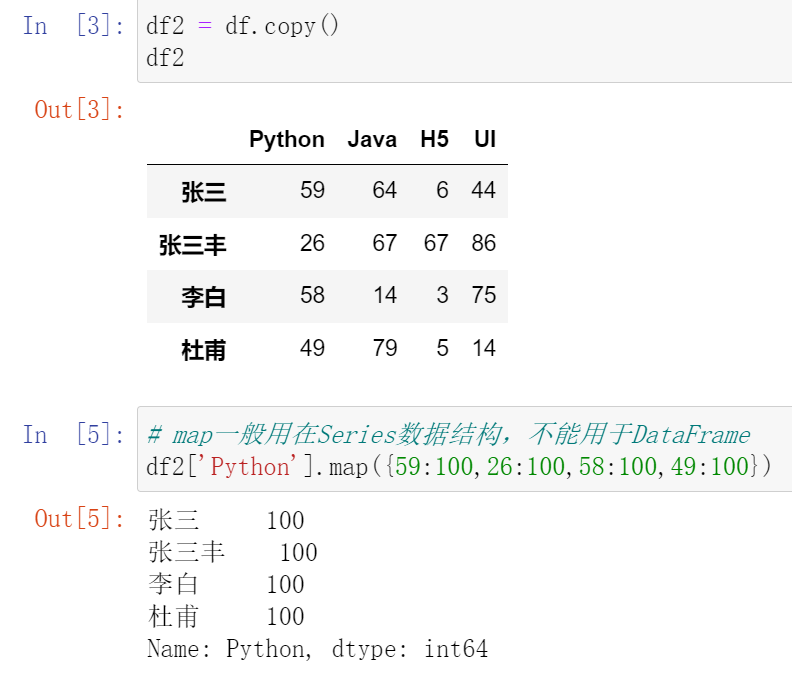
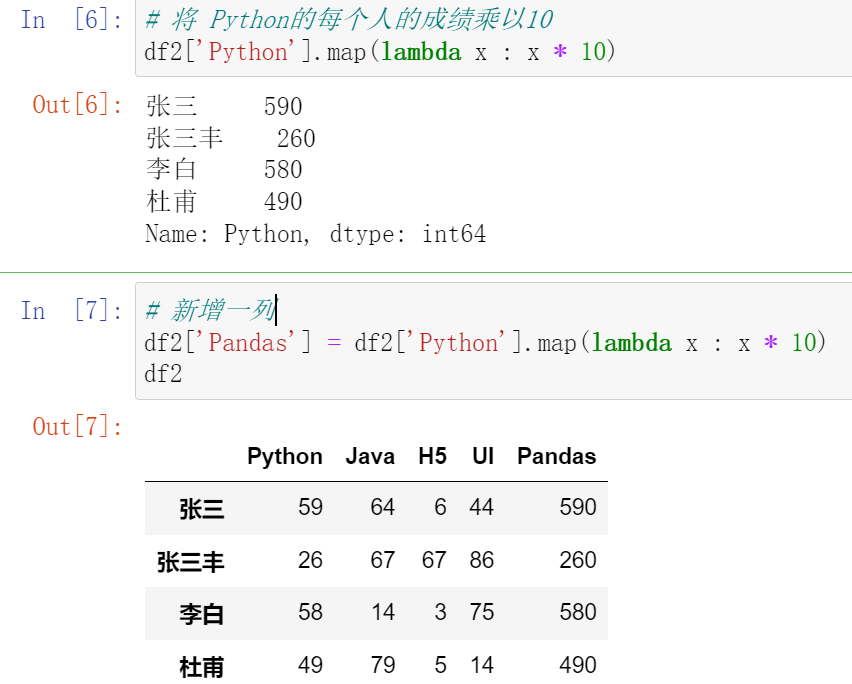
025,数据映射map
map()函数中可以使用lamba函数
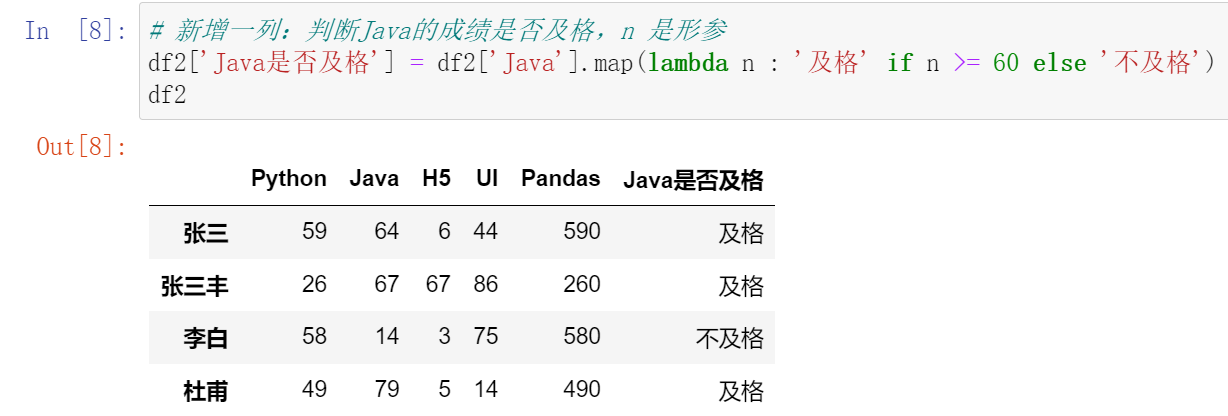

026,修改索引名rename

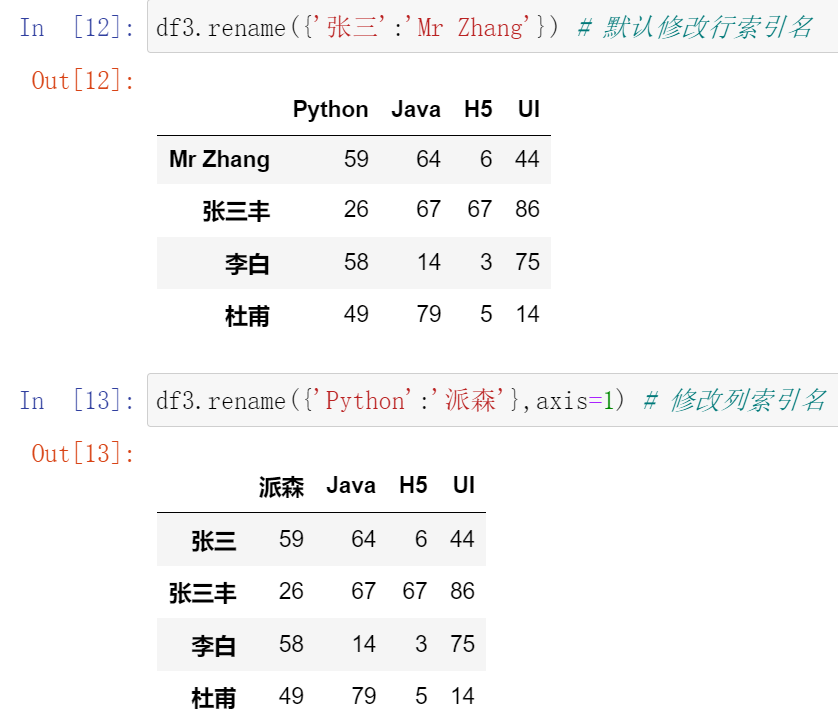
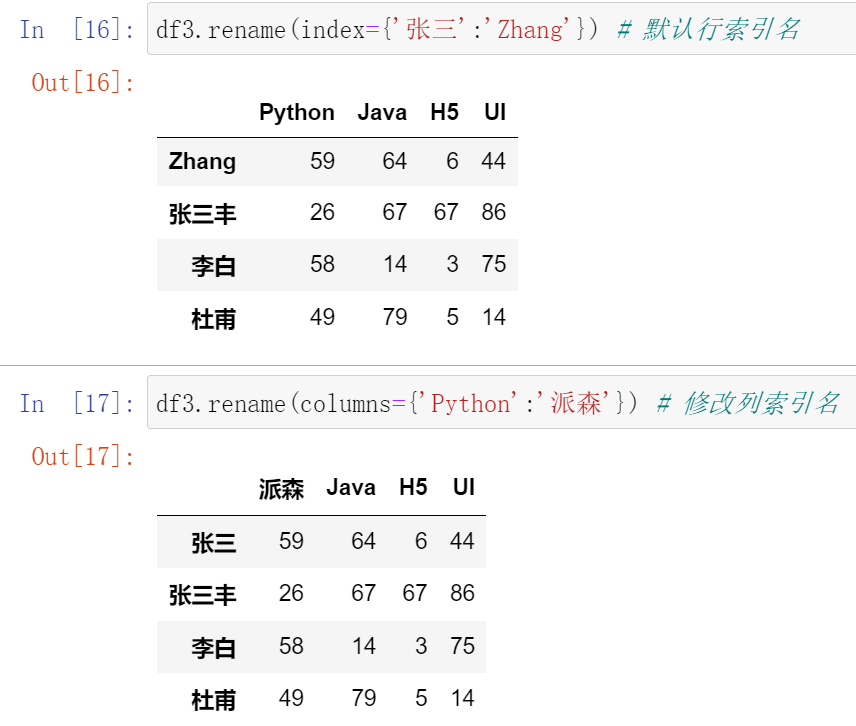
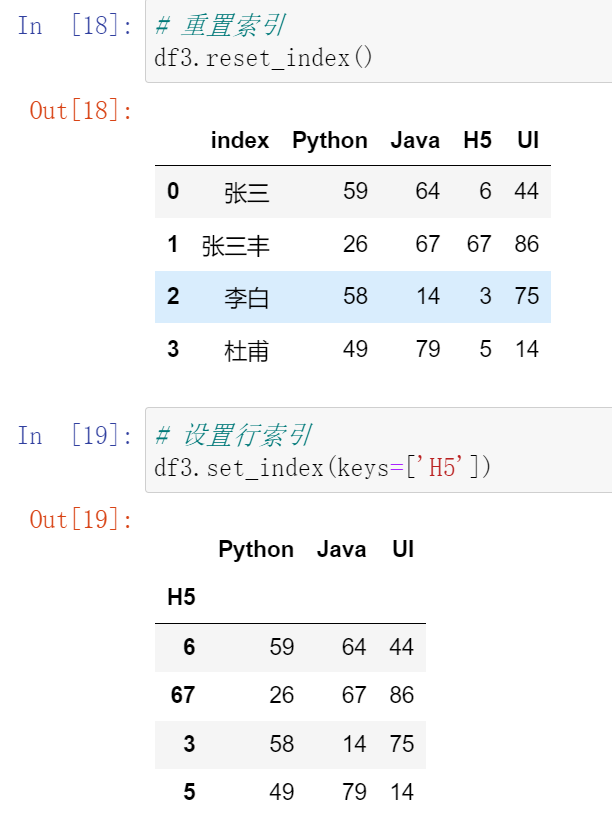
027,重置索引reset_index和设置索引set_index
028,数据处理apply
apply() 函数:既支持 Series,也支持DataFrame
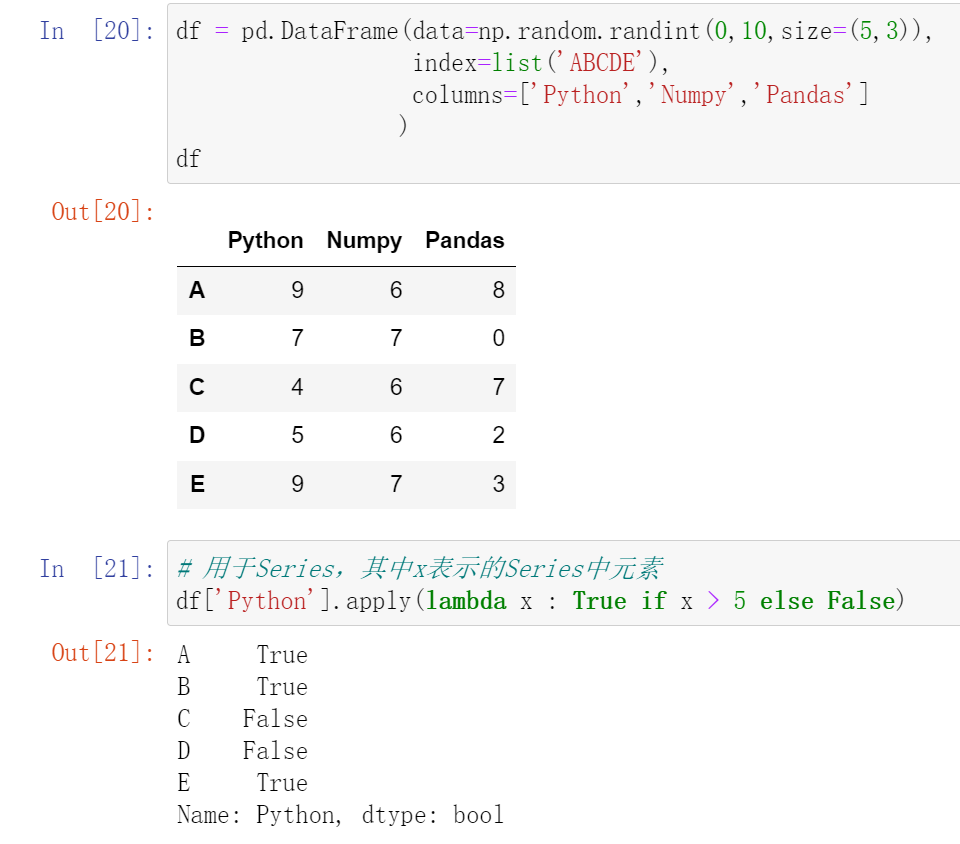
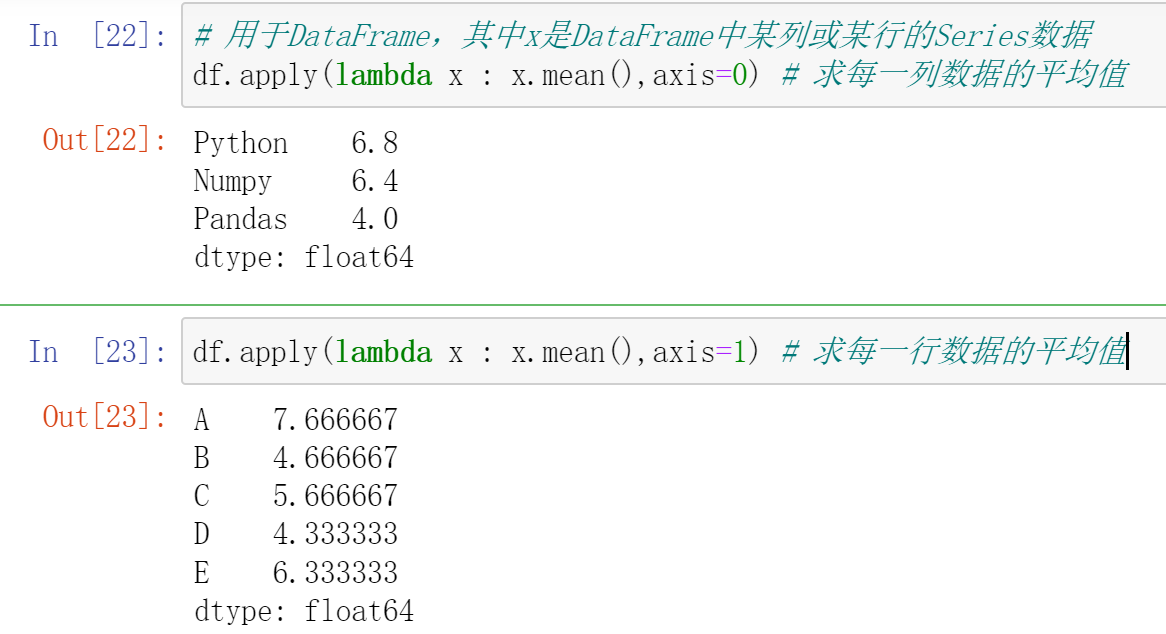

029,数据处理transform
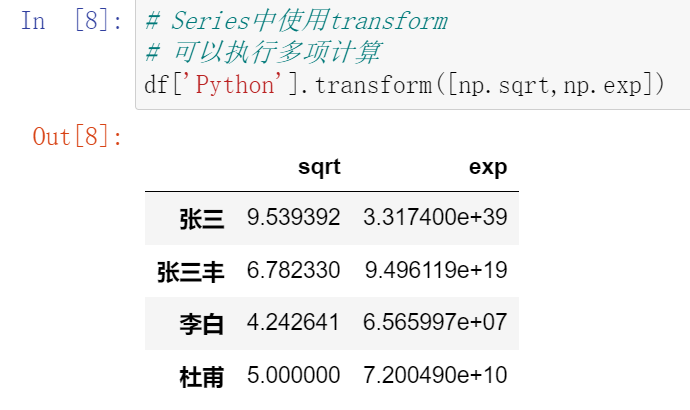

030,异常值检测和过滤1
(30.1)describe() :查看每一列的描述性统计量
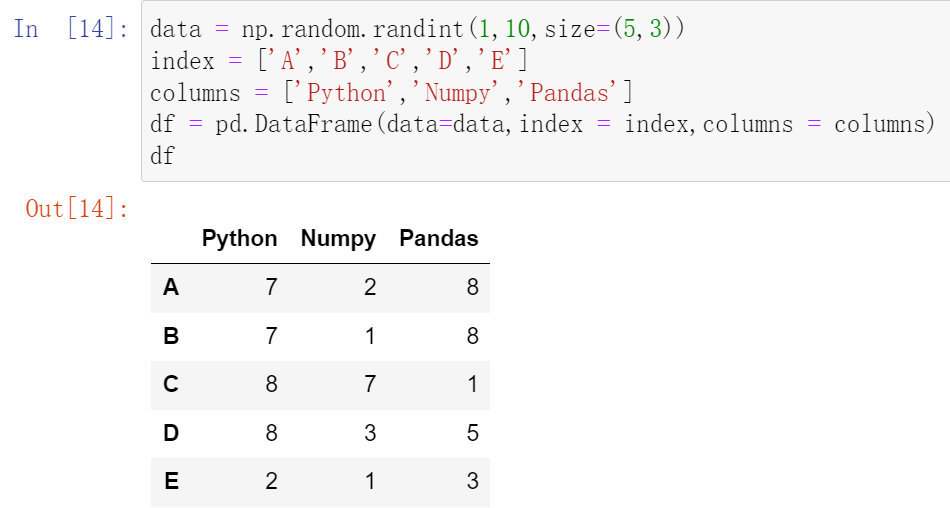
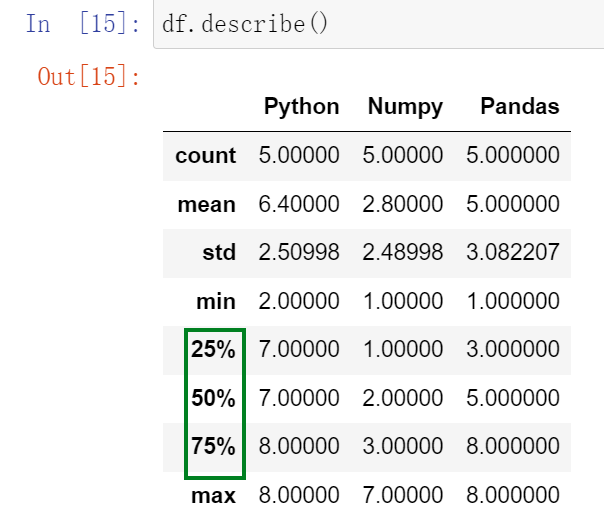
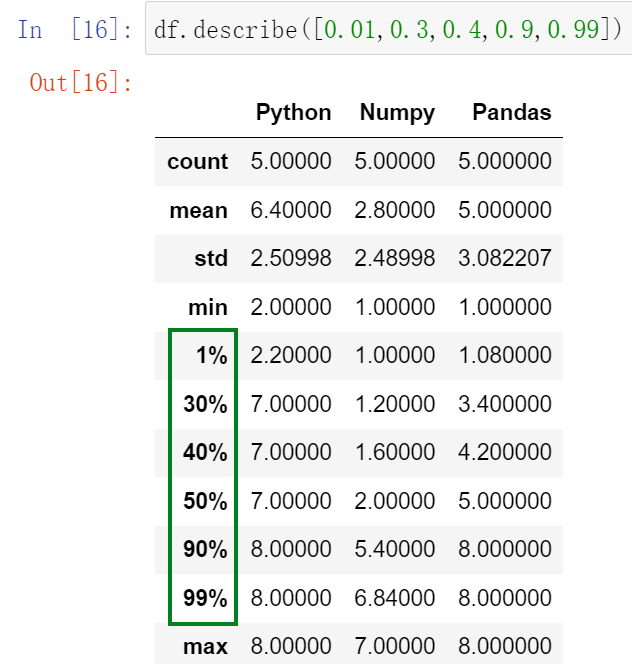
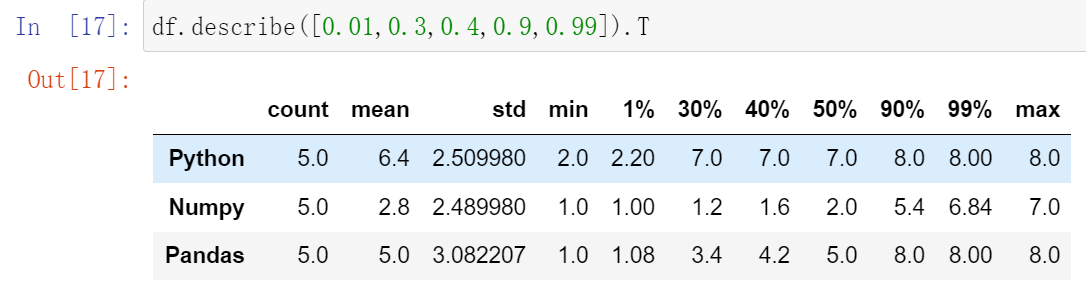
(30.2)df.std() :可以求得DataFrame对象每一列的标准差

(30.3)df.drop() :删除特定索引

031, 异常值检测和过滤2
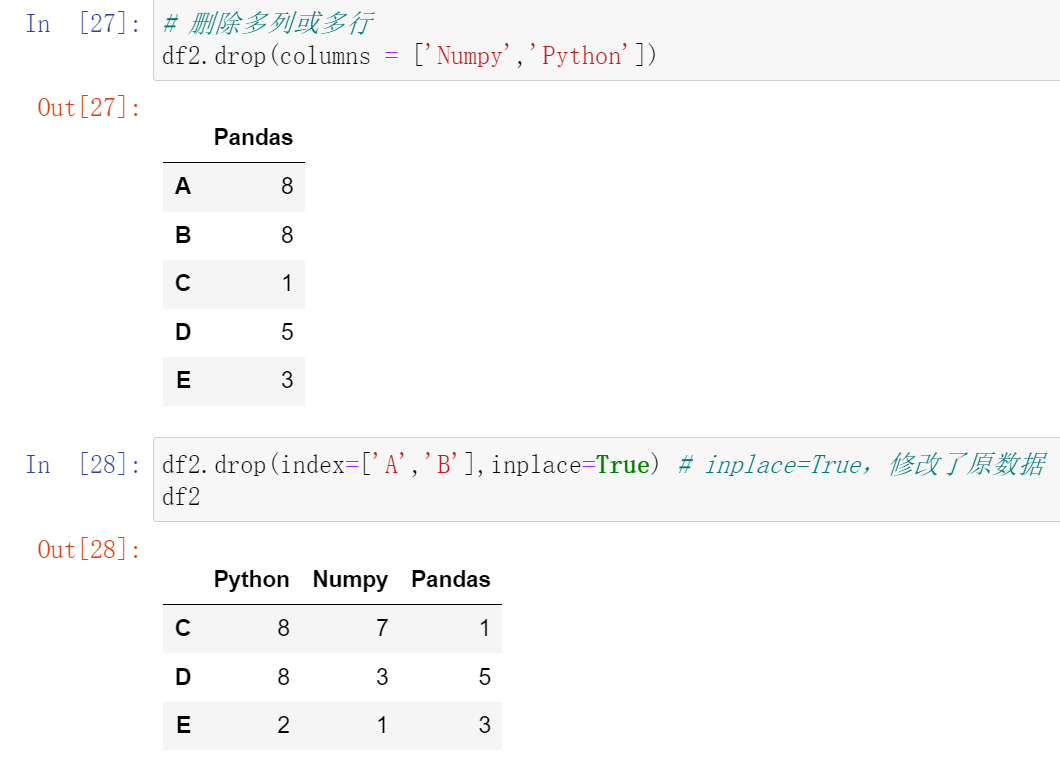
(31.1)unique() :唯一,去重
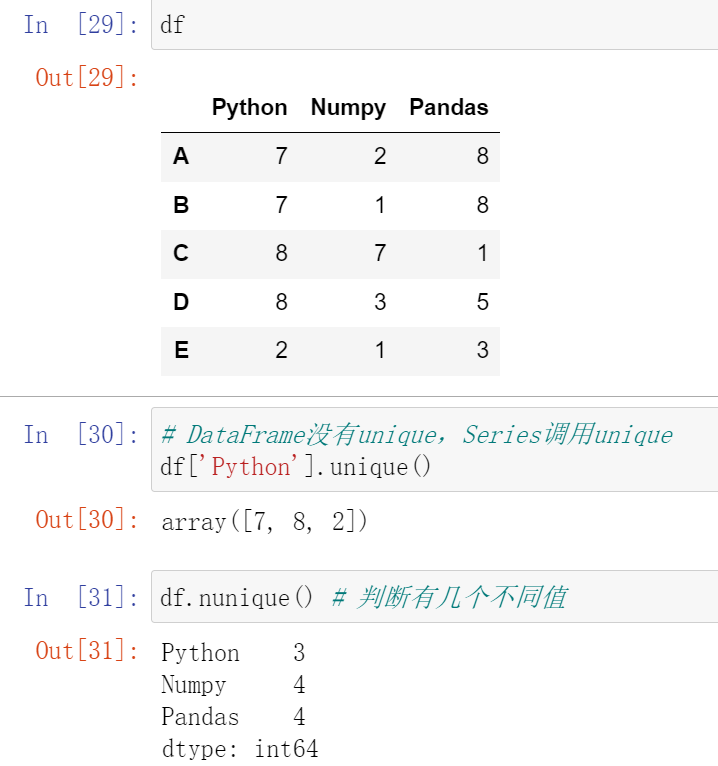
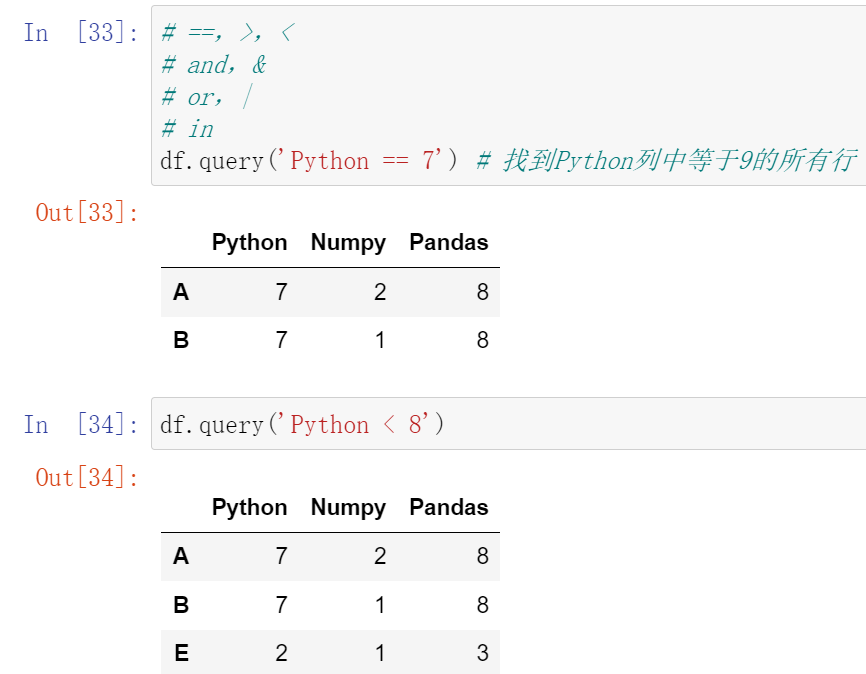
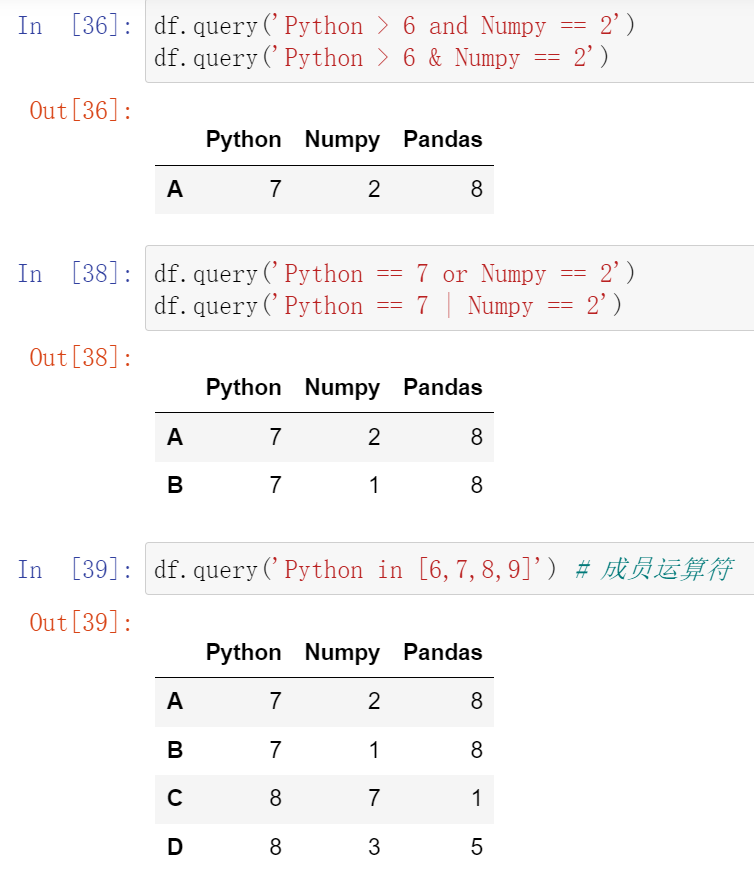
(31.2)df.query:按条件查询

032,异常值检测和过滤3
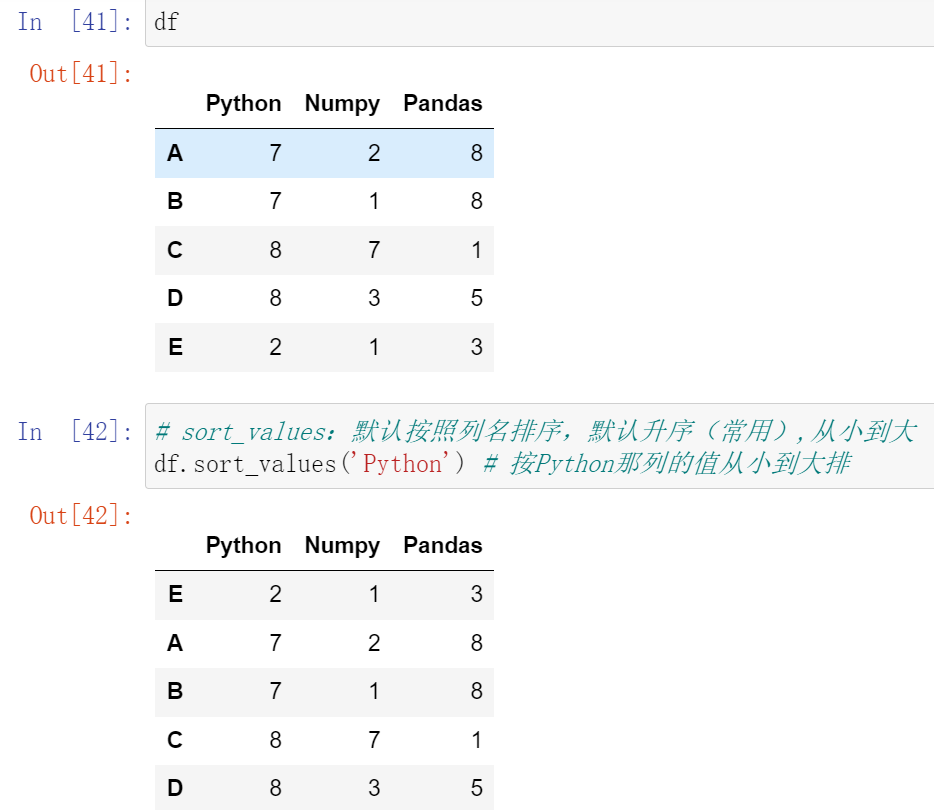
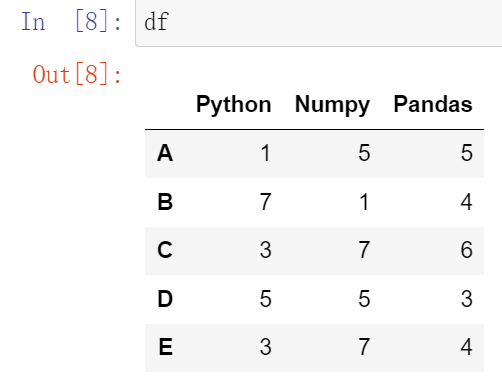
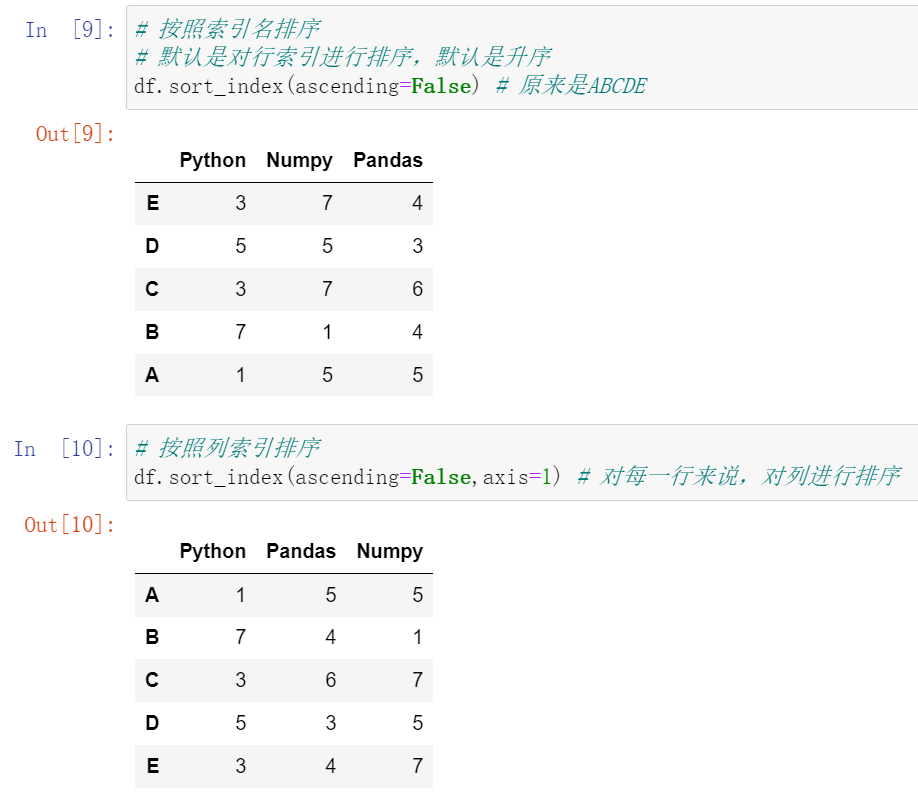
(32.1)df.sort_values():根据值排序;df.sort_index():根据索引排序

重新创建数据
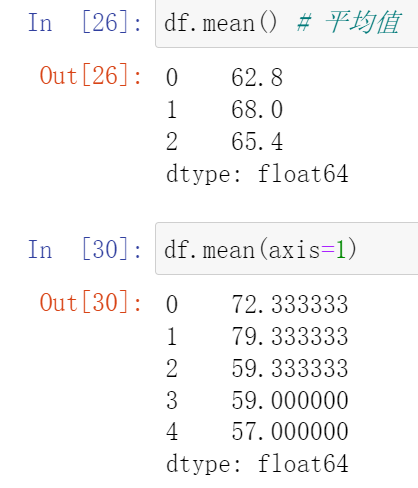
035,常用聚合函数(count,max,min,median,sum,mean)






038,数据分组聚合
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单个的数值。
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心:groupby()函数
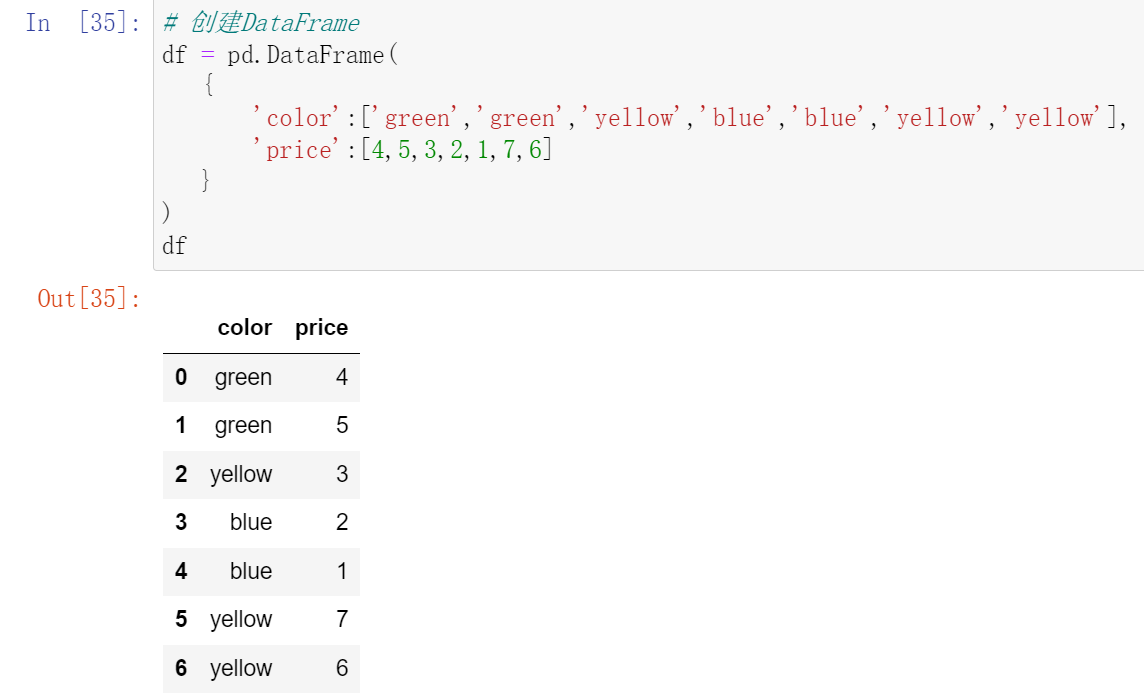

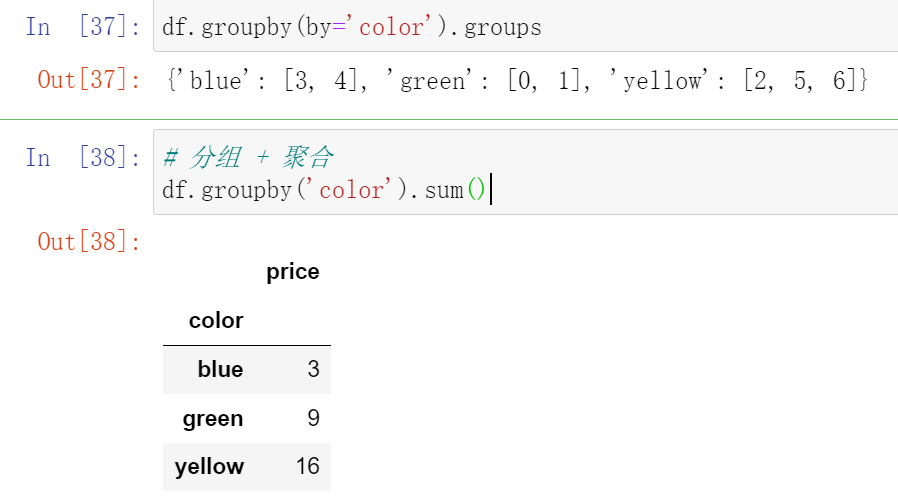
使用.groups属性查看各行的分组情况:
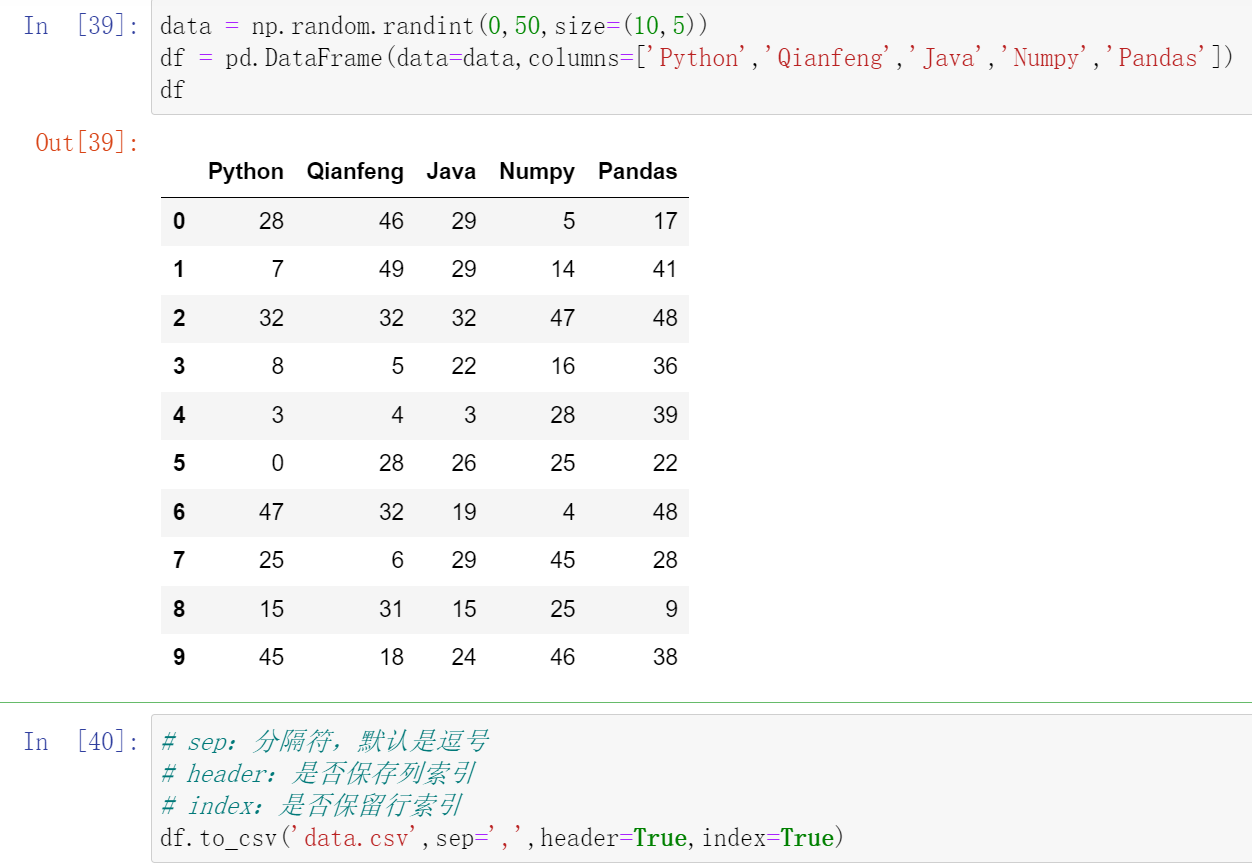
039,CSV数据加载
(39.1)df.to_csv:保存到csv
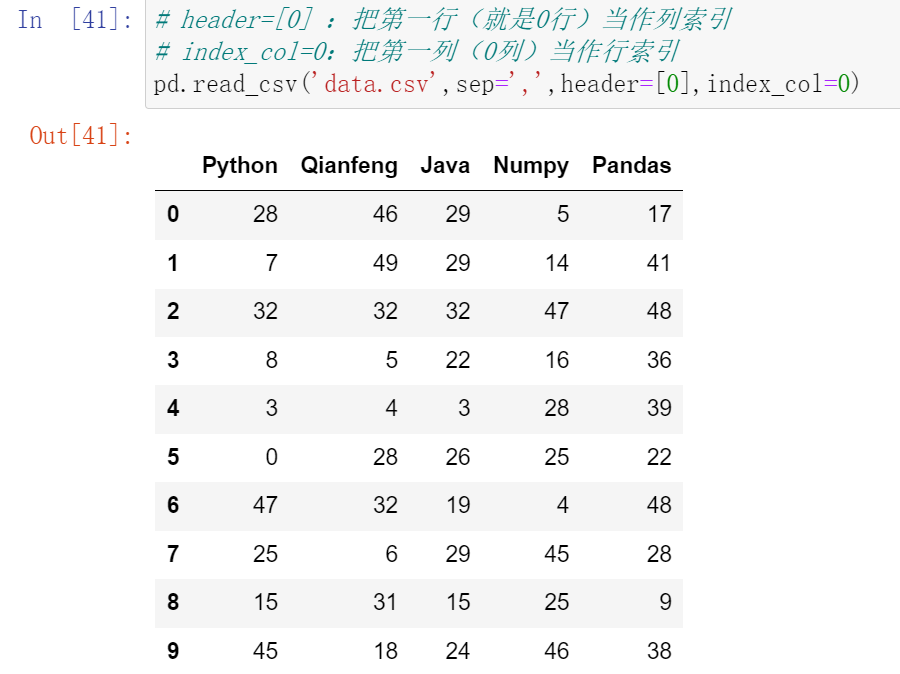
(39.2)df.read_csv:加载csv数据
Python数据分析 DataFrame 笔记的更多相关文章
- 《Python 数据分析》笔记——pandas
Pandas pandas是一个流行的开源Python项目,其名称取panel data(面板数据)与Python data analysis(Python 数据分析)之意. pandas有两个重要的 ...
- python数据分析入门笔记[1]
1.Numpy: Numpy是python科学计算的基础包,它提供以下功能(不限于此): (1)快速高效的多维数组对象naarray (2)用于对数组执行元素级计算以及直接对数组执行数学运算的函数 ( ...
- 《Python 数据分析》笔记——数据的检索、加工与存储
数据的检索.加工与存储 1.利用Numpy和pandas对CSV文件进行写操作 对CSV文件进行写操作,numpy的savetxt()函数是与loadtxt()相对应的一个函数,他能以诸如CSV之类的 ...
- 《Python数据分析》笔记——数据可视化
数据可视化 matplotlib绘图入门 为了使用matplotlib来绘制基本图像,需要调用matplotlib.pyplot子库中的plot()函数 import matplotlib.pyplo ...
- 《Python数据分析》笔记1 ——Numpy
Numpy数组 1.Numpy数组对象 Numpy中的多维数组称为ndarray,他有两个组成部分. 1.数据本身 2.描述数据的元数据 2.Numpy的数值类型 bool: 布尔型 inti:其长度 ...
- 《Python数据分析》笔记2——统计学与线性代数
统计学与线性代数 用Numpy进行简单的描述性统计计算 import numpy as np from scipy.stats import scoreatpercentile data=np.loa ...
- python数据分析入门学习笔记儿
学习利用python进行数据分析的笔记儿&下星期二内部交流会要讲的内容,一并分享给大家.博主粗心大意,有什么不对的地方欢迎指正~还有许多尚待完善的地方,待我一边学习一边完善~ 前言:各种和数据 ...
- 【读书笔记与思考】《python数据分析与挖掘实战》-张良均
[读书笔记与思考]<python数据分析与挖掘实战>-张良均 最近看一些机器学习相关书籍,主要是为了拓宽视野.在阅读这本书前最吸引我的地方是实战篇,我通读全书后给我印象最深的还是实战篇.基 ...
- Python数据分析笔记
最近在看Python数据分析这本书,随手记录一下读书笔记. 工作环境 本书中推荐了edm和ipython作为数据分析的环境,我还是刚开始使用这种集成的环境,觉得交互方面,比传统的命令行方式提高了不少. ...
- python数据分析笔记——数据加载与整理]
[ python数据分析笔记——数据加载与整理] https://mp.weixin.qq.com/s?__biz=MjM5MDM3Nzg0NA==&mid=2651588899&id ...
随机推荐
- echarts中实现多个label
先来个效果图 如果你刚好需要实现这种效果,那么可以瞅一瞅了 我要开始水文了 如图所示,图中顶部部分文字乍一看好像是独立于柱状图,显示在最顶上,其实它也是由柱状图模拟而成. 只是吧图形相关属性做了隐藏, ...
- Bad magic number for central directory
Bad magic number for central directory 运行代码输出如下bug: File "/home/a/Prediction/Predict_Models.py& ...
- 【Nginx】如何使用自签CA配置HTTPS加密反向代理访问?看了这篇我会了!!
写在前面 随着互联网的发展,很多公司和个人越来越重视网络的安全性,越来越多的公司采用HTTPS协议来代替了HTTP协议.为何说HTTPS协议比HTTP协议安全呢?小伙伴们自行百度吧!我就不说了.今天, ...
- Python爬虫爬取ECVA论文标题、作者、链接
1 import re 2 import requests 3 from bs4 import BeautifulSoup 4 import lxml 5 import traceback 6 imp ...
- #费马小定理#JZOJ 4015 数列
题目 给出\(x_n=(ax_{n-1}^2+bx_{n-1}+c)\bmod m\) 给出\(x_0.a,b,c,n,m\),求\(x_n\) \(\text{Subtask 1:}n\leq 10 ...
- std::format 如何实现编译期格式检查
C++ 20 的 std::format 是一个很神奇.很实用的工具,最神奇的地方在于它能在编译期检查字符串的格式是否正确,而且不需要什么特殊的使用方法,只需要像使用普通函数那样传参即可. #incl ...
- 域名之A记录,CNAME,NS联系和区别
域名解析中常常涉及:A记录,CNAME,NS 1. A记录 又称IP指向,用户可以在此设置子域名并指向到自己的目标主机地址上,从而实现通过域名找到服务器.说明:指向的目标主机地址类型只能使用IP地址; ...
- 超强阵容!HarmonyOS极客马拉松2023专家评审团来袭!
数十位重量级专家现身决赛现场,为参赛者提供多角度专业点评.12支队伍,46位选手,齐聚东莞·松山湖,围绕HarmonyOS技术特性,共同挑战36小时极限编程,谁将问鼎决赛之巅,8.3日-5日,我们拭 ...
- flutter3-macOS桌面端os系统|flutter3.x+window_manager仿mac桌面管理
原创力作flutter3+getX+window_manager仿Mac桌面系统平台Flutter-MacOS. flutter3_macui基于最新跨端技术flutter3.19+dart3.3+w ...
- llm构建数据标注助手
为什么要用LLM构建数据标注工具 在LLM出现之前,传统的深度学习模型(包括CV和NLP)就已经需要大量的数据进行训练和微调.没有足够的数据,或者数据需要进行二次加工(比如标签标注),这些问题都成为限 ...