火山引擎 DataLeap 下 Notebook 系列文章二:技术路线解析
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
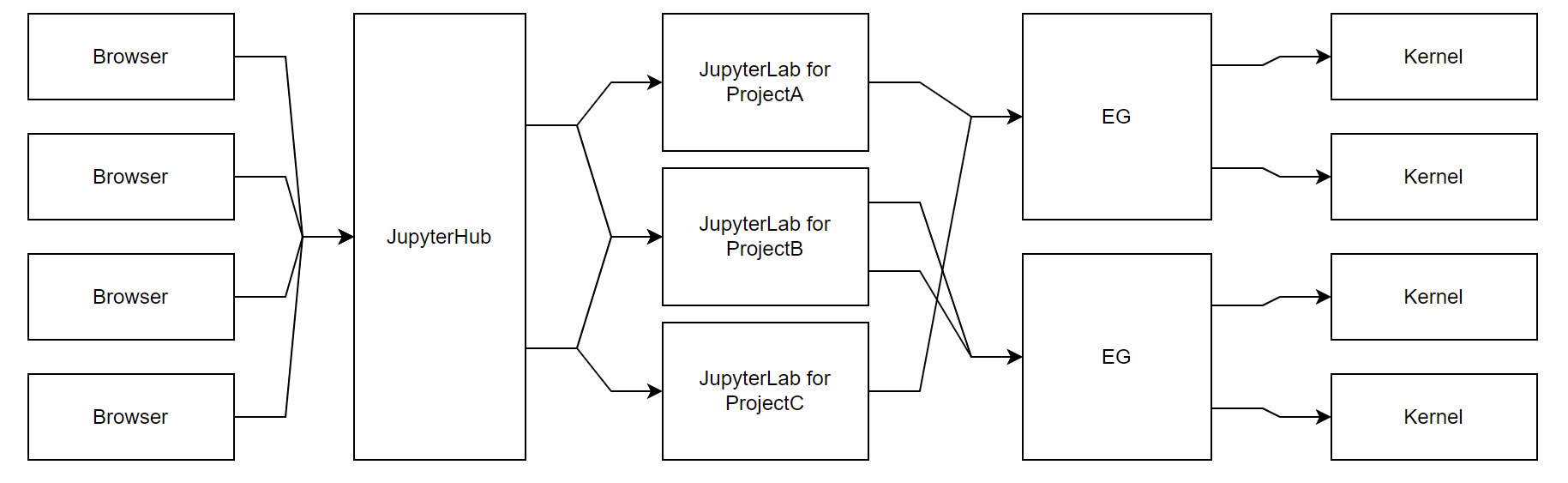
在 Jupyter 的生态下,除了 Notebook 本身,火山引擎 DataLeap 研发团队还注意到了很多其他组件。彼时,JupyterLab 正在逐渐取代传统的 Jupyter Notebook 界面,成为新的标准。JupyterHub 使用广泛,是多用户 Notebook 的版本答案。
脱胎于 Jupyter Kernel Gateway(JKG)的 Enterprise Gateway(EG),提供了火山引擎 DataLeap 研发团队需要的 Remote Kernel(上述的独立任务 Kernel 环境)能力。2020 上半年,火山引擎 DataLeap 研发团队基于上面的三大组件,进行二次开发,发布了 Notebook 任务类型。
JupyterLab 前端这一侧,火山引擎 DataLeap 研发团队选择了基于更现代化的 JupyterLab 进行改造,刨去了它的周边视图,只留下了中间的 Cell 编辑区,嵌入了火山引擎 DataLeap 数据研发的页面中。为了和火山引擎 DataLeap 的视觉风格更契合,从 2020 下半年到 2021 年初,团队还针对性地改进了 JupyterLab 的 UI。
另外火山引擎 DataLeap 研发团队还开发了定制的可视化 SDK,使得用户在 Notebook 上计算得到的 Pandas Dataframe 可以接入火山引擎 DataLeap 数据研发已经提供的数据结果分析模块,直接在 Notebook 内部做一些简单的数据探查。
JupyterHub提供了可扩展的认证鉴权能力和环境创建能力。首先,由于用户较多,因此为每个用户提供单独的 Notebook 实例不太现实。因此团队决定,按 火山引擎 DataLeap 项目来切分 Notebook 实例,同项目下的用户共享一个实例(即一个项目实际上在 JupyterHub 是一个用户)。这也与 火山引擎 DataLeap 的项目权限体系保持了一致。
Jupyter Enterprise Gateway提供了在分布式集群(包括 YARN、Kubernetes 等)内部启动 Kernel 的能力,并成为了 Notebook 到集群内 Kernel 的代理。
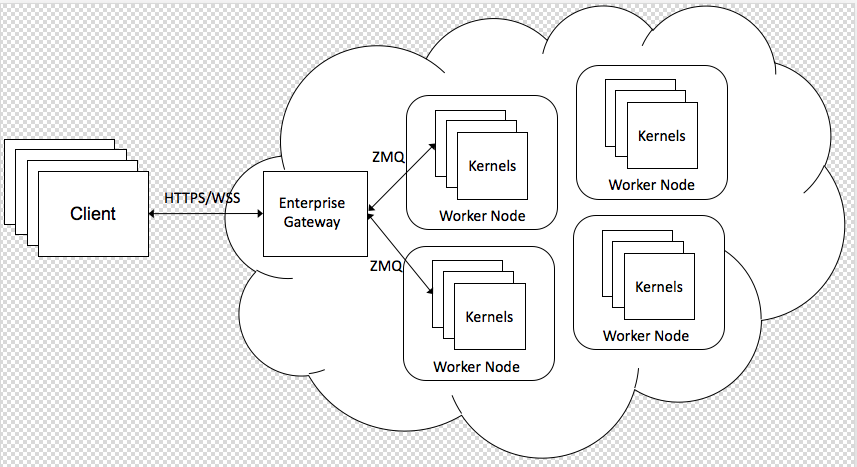
(图:Enterprise Gateway )
EG 本身提供的 Kernel 类型,和火山引擎内部系统并不完全兼容,火山引擎 DataLeap 研发团队首先以 Spark Kernel 的形式对接了字节跳动内部的 YARN 集群。Kernel 以 PySpark 的形式在 Cluster 模式的 Spark Driver 运行,并提供一个默认的 Spark Session。
用户可以通过在 Driver 上的 Kernel,直接发起运行 Spark 相关代码。同时,为了满足 Spark 用户的使用习惯,火山引擎 DataLeap 额外提供了在同一个 Kernel 内交叉运行 SQL 和 Scala 代码的能力。
2020 下半年,伴随着云原生的浪潮,火山引擎 DataLeap 研发团队还接入了字节跳动云原生 K8s 集群,为用户提供了 Python on K8s 的 Kernel,还扩展了很多自定义的能力,例如支持自定义镜像,以及针对于 Spark Kernel 的自定义 Spark 参数。
目前 Notebook 任务已成为字节跳动内部使用较为高频的任务类型,用户可以在火山引擎 DataLeap 官网开通交互式分析的版本,使用到 DataLeap 的 Notebook 任务。
点击跳转 火山引擎大数据研发治理DataLeap 了解更多
火山引擎 DataLeap 下 Notebook 系列文章二:技术路线解析的更多相关文章
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- 如何又快又好实现 Catalog 系统搜索能力?火山引擎 DataLeap 这样做
摘要 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理.资产.安全等全套数据中台建设,降低工作成本和数据维护成本.挖掘数据价 ...
- 火山引擎 DataLeap:揭秘字节跳动数据血缘架构演进之路
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维 ...
- 火山引擎 DataLeap:一家企业,数据体系要怎么搭建?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 导读:经过十多年的发展,数据治理在传统行业以及新兴互联网公司都已经产生落地实践.字节跳动也在探索一种分布式的数据治 ...
- 火山引擎 DataLeap 的 Data Catalog 系统公有云实践
Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景.本篇内容源自于火山引擎大数据研发治理套件 DataLeap 中的 Data Ca ...
- 火山引擎DataLeap数据调度实例的 DAG 优化方案
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 实例 DAG 介绍 DataLeap 是火山引擎自研的一站式大数据中台解决方案,集数据集成.开发.运维.治理.资产管理能力 ...
- Redis变慢?深入浅出Redis性能诊断系列文章(二)
(本文首发于"数据库架构师"公号,订阅"数据库架构师"公号,一起学习数据库技术) 本篇为Redis性能问题诊断系列的第二篇,本文主要从应用发起的典型命令使用上进 ...
- .NET性能系列文章二:Newtonsoft.Json vs. System.Text.Json
微软终于追上了? 图片来自 Glenn Carstens-Peters Unsplash 欢迎来到.NET性能系列的另一章.这个系列的特点是对.NET世界中许多不同的主题进行研究.基准和比较.正如标题 ...
- NHibernate系列文章二十八:NHibernate Mapping之Auto Mapping(附程序下载)
摘要 上一篇文章介绍了Fluent NHibernate基础知识.但是,Fluent NHibernate提供了一种更方便的Mapping方法称为Auto Mapping.只需在代码中定义一些Conv ...
- NHibernate系列文章二十七:NHibernate Mapping之Fluent Mapping基础(附程序下载)
摘要 从这一节起,介绍NHibernate Mapping的内容.前面文章都是使用的NHibernate XML Mapping.NHibernate XML Mapping是NHibernate最早 ...
随机推荐
- angular:响应式表单(Reactive Forms)和模板驱动表单(Template-Driven Forms)分别进行验证
2022-01-18 响应式表单 响应式表单是围绕Observable的流构建的. 使用响应式表单时,FormControl类是最基本的构造类. 在使用响应式表单前,需要先导入 ReactiveFor ...
- JVM-JVM如何加载类
一.Java 语言的类型可以分为两大类: 基本类型(primitive types) 引用类型(reference types):类.接口.数组类和泛型参数(泛型参数会在编译中被擦除),因此Java虚 ...
- 基于AStyle的代码格式化脚本 [已开源]
这是一个简单的windows端脚本 主要用于C/C++代码的格式化 可以添加到鼠标右键,直接在.C/.H文件上右键格式化代码 具体开源地址 https://gitee.com/svchao/code_ ...
- Welcome to YARP - 5.压缩、缓存
目录 Welcome to YARP - 1.认识YARP并搭建反向代理服务 Welcome to YARP - 2.配置功能 2.1 - 配置文件(Configuration Files) 2.2 ...
- 快速排序(quick_sort)
快速排序大体分为三个步骤: 1.确定分界点 q[(l+r) >> 1] 或者 q[(l+r+1) >> 1] ,两者得看情况而定,不能用 q[l] 或者 q[r] 了 因为会超 ...
- MySQL概述安装
一,数据库概述 1.为什么要使用数据库 将数据持久化. 持久化主要作用:是将内存中的数据库存储在关系型数据库中,本质也就是存储在磁盘文件中. 数据库在横向上的存储数据的条数,以及在纵向上存储数据的丰富 ...
- CD74HC4067高速CMOS16通道模拟多路复用器实践
咱们在玩arduino或stm32.esp8266时,有时会遇到板子模拟口不够用的情况,这个时候CD74HC4067就派上用场了,它可以将16路数字/模拟信号通过4数字+1模拟=5口来读取. 这货长这 ...
- Windows10+Python+Yolov8+ONNX图片缺陷识别,并在原图中标记缺陷,有onnx模型则无需配置,无需训练。
目录 一.训练自己数据集的YOLOv8模型 1.博主电脑配置 2.深度学习GPU环境配置 3.yolov8深度学习环境准备 4.准备数据集 二.Python+Onnx模型进行图像缺陷检测,并在原图中标 ...
- python循环之for循环
当我们想让列表中的元素一个一个打印出时,用多个print()就显得代码很繁琐了,这是我们就可以用到循环 list_1 = ['one', 'two', 'three', 'four', 'five'] ...
- springMvc_控制台中文乱码问题
Post方法解决控制台乱码 @Override protected Filter[] getServletFilters() { CharacterEncodingFilter filter = ne ...