[转帖]clickhouse存储机制以及底层数据目录分布
https://www.cnblogs.com/MrYang-11-GetKnow/p/15818141.html#:~:text=%E6%AF%8F%E4%B8%80%E4%B8%AA%E6%95%B0%E6%8D%AE%E5%BA%93%E9%83%BD%E4%BC%9A%E5%9C%A8clickhouse%E7%9A%84data%E7%9B%AE%E5%BD%95%E4%B8%AD%E5%88%9B%E5%BB%BA%E4%B8%80%E4%B8%AA%E5%AD%90%E7%9B%AE%E5%BD%95%EF%BC%8Cclickhouse%E9%BB%98%E8%AE%A4%E6%90%BA%E5%B8%A6default%E5%92%8Csystem%E4%B8%A4%E4%B8%AA%E6%95%B0%E6%8D%AE%E5%BA%93%E3%80%82,default%E9%A1%BE%E5%90%8D%E6%80%9D%E4%B9%89%E5%B0%B1%E6%98%AF%E9%BB%98%E8%AE%A4%E6%95%B0%E6%8D%AE%E5%BA%93%EF%BC%8Csystem%E6%98%AF%E5%AD%98%E5%82%A8clickhouse%E6%9C%8D%E5%8A%A1%E5%99%A8%E7%9B%B8%E5%85%B3%E4%BF%A1%E6%81%AF%E7%9A%84%E6%95%B0%E6%8D%AE%E5%BA%93%EF%BC%8C%E4%BE%8B%E5%A6%82%E8%BF%9E%E6%8E%A5%E6%95%B0%E3%80%81%E8%B5%84%E6%BA%90%E5%8D%A0%E7%94%A8%E7%AD%89%E3%80%82
在大部分的DBMS中,数据库本质上就是一个由各种子目录和文件组成的文件目录,clickhouse当然也不例外。clickhouse默认数据目录在/var/lib/clickhouse/data目录中。所有的数据库都会在该目录中创建一个子文件夹。下图展示了clickhouse对数据文件的组织。
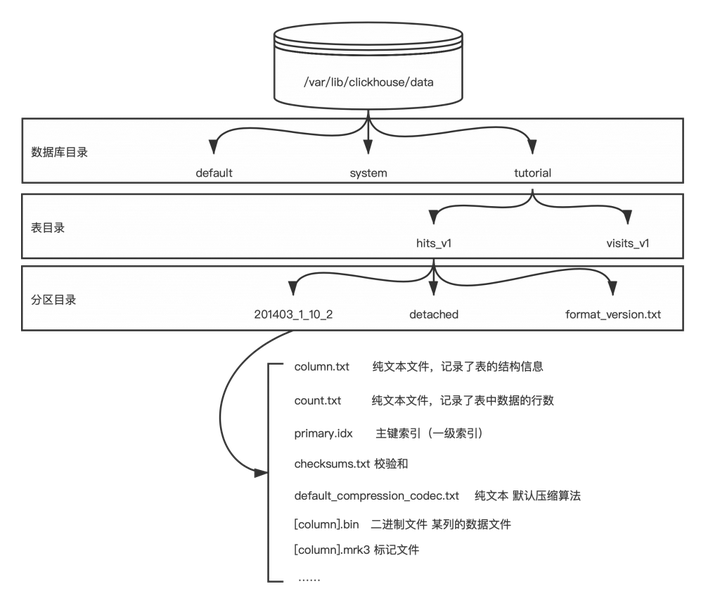
每一个数据库都会在clickhouse的data目录中创建一个子目录,clickhouse默认携带default和system两个数据库。default顾名思义就是默认数据库,system是存储clickhouse服务器相关信息的数据库,例如连接数、资源占用等。
分区目录
分区目录下的子目录和文件的含义如下:
| 目录名 | 类型 | 说明 |
| 202103_1_10_2 | 目录 | 分区目录一个或多个,由于分区+LSM生成的 |
| detached | 目录 | 通过DETACH语句卸载后的表分区存放位置 |
| format_version.txt | 文本文件 | 纯文本,记录存储的格式 |
分区目录构成
分区目录的构成,按照 分区ID_最小数据块编号_最大数据块编号_层级构成。在本例中,分区ID是202103,最小数据块编号是1,最大数据库编号是10,层级是2。数据块编号从1开始自增,新创建的数据库最大和最小编号相同,当发生合并时会将其修改为合并的数据块编号。同时每次合并都会将层级增加1。
分区ID由用户在创建表时制定,允许用户创建多个分区键,每个分区键之间用‘-’相连。在本例中只使用了一个分区键,即时间字段,按照年月分区。分区的好处在于提高并发度和加速部分查询。
数据目录
进入分区目录后,就能看到数据真实存储的数据目录的结构了。
columns.txt
该文件是一个文本文件,存储了表结构信息,可以用文本编辑打开。
count.txt
该文件也是一个文本文件,存储了该分区下的行数。可以用文本文件打开。在用户执行select count(*) from xxx时本质上就是直接返回了该文件的内容,而不需要遍历数据。因此clickhouse的count(*)的速度非常快。
同时,这边也对比一下MySQL和PostgreSQL的实现,在上述两个关系型数据库中,其常用的存储引擎,都没有使用clickhouse的这种方案。读者们能否回答出为了MySQL或pg要舍弃简单的方案而使用遍历么?
这个问题的答案是由于事务的可见性,MySQL和pg都是用MVCC机制的事务控制技术,这意味着对于不同事务中执行select count(*)的结果是不同的,对于A事务中执行的insert或delete,对于本事务中是可见的,也就是说在本事务中执行的count是计算了insert和delete影响的。而对于B事务,在A事务提交前,是不能看到A事务中对数据的操作的。因此AB两个事务中执行的count后的结果可能是不同的。如果使用clickhouse的方案,就无法实现上述需求。而clickhouse则不需要支持事务,因此使用了相对简单的方案。
primary.idx
主键索引
checksums.txt
二进制文件
default_compression_codec.txt
新版本增加的一个文件,在旧版本时无。该文件是一个文本文件,存储了数据文件中使用的压缩编码器。clickhouse提供了多种压缩算法供用户选择,默认使用LZ4。
[column].mrk3
列的标记文件
[column].bin
真正存储数据的数据文件。每一列都会生成一个单独的bin文件。
skp_idx_[column].idx
跳数索引,在使用了二级索引时会生成,否则这不生成。
skp_idx_[column].mrk
跳数索引标记文件,在使用了二级索引时会生成。否则这不生成
数据组织
如何读取bin文件。由于bin文件是二进制文件,在读取时需要借助工具,无法使用文本文件进行读取。在windows操作系统下建议使用winhex,mac系统推荐hex friend。
数据文件结构

上图展示了一个bin文件的结构。bin文件使用小端字节序存储。bin文件中按block为单位排列数据,每个block文件有16字节校验和,1字节压缩方式,4字节压缩后大小和4字节的压缩前大小组成。每个block起始地址由如下公式确定:
- offset(n)=offset(n-1)+25+压缩后大小 (n>=2)
- offset(1)=0
校验和
前16为检验和区域用于快速验证数据是否完整。
压缩方式
默认为0x82。clickhouse共支持4种压缩方式,分别为LZ4(0x82)、ZSTD(0x90)、Multiple(0x91)、Delta(0x92)。
压缩后大小
存储在data区域的数据的大小。需要依据此大小计算下一个BLOCK的偏移量。
压缩前大小
data区域存储的数据在压缩前的大小。可以依据此计算压缩比。
data区
data区存储数据,大小为头信息第18~21字节表示的大小。拿到data区数据后,由于是压缩后的,因此无法直接识别,需要按照压缩方式进行解压缩后,才能识别。
[转帖]clickhouse存储机制以及底层数据目录分布的更多相关文章
- Java提高篇——通过分析 JDK 源代码研究 Hash 存储机制
HashMap 和 HashSet 是 Java Collection Framework 的两个重要成员,其中 HashMap 是 Map 接口的常用实现类,HashSet 是 Set 接口的常用实 ...
- 通过分析 JDK 源代码研究 Hash 存储机制
通过 HashMap.HashSet 的源代码分析其 Hash 存储机制 实际上,HashSet 和 HashMap 之间有很多相似之处,对于 HashSet 而言,系统采用 Hash 算法决定集合元 ...
- 通过分析 JDK 源代码研究 Hash 存储机制--转载
通过 HashMap.HashSet 的源代码分析其 Hash 存储机制 集合和引用 就像引用类型的数组一样,当我们把 Java 对象放入数组之时,并不是真正的把 Java 对象放入数组中,只是把对象 ...
- Kafka 存储机制和副本
1.概述 Kafka 快速稳定的发展,得到越来越多开发者和使用者的青睐.它的流行得益于它底层的设计和操作简单,存储系统高效,以及充分利用磁盘顺序读写等特性,和其实时在线的业务场景.对于Kafka来说, ...
- Hash存储机制 - HashMap原理 HashSet原理
HashMap 和 HashSet 是 Java Collection Framework 的两个重要成员,其中 HashMap 是 Map 接口的常用实现类,HashSet 是 Set 接口的常用实 ...
- 《Java并发编程的艺术》Java并发机制的底层实现原理(二)
Java并发机制的底层实现原理 1.volatile volatile相当于轻量级的synchronized,在并发编程中保证数据的可见性,使用 valotile 修饰的变量,其内存模型会增加一个 L ...
- java-通过 HashMap、HashSet 的源码分析其 Hash 存储机制
通过 HashMap.HashSet 的源码分析其 Hash 存储机制 集合和引用 就像引用类型的数组一样,当我们把 Java 对象放入数组之时,并非真正的把 Java 对象放入数组中.仅仅是把对象的 ...
- 6.redis 的持久化有哪几种方式?不同的持久化机制都有什么优缺点?持久化机制具体底层是如何实现的?
作者:中华石杉 面试题 redis 的持久化有哪几种方式?不同的持久化机制都有什么优缺点?持久化机制具体底层是如何实现的? 面试官心理分析 redis 如果仅仅只是将数据缓存在内存里面,如果 redi ...
- Java 并发系列之二:java 并发机制的底层实现原理
1. 处理器实现原子操作 2. volatile /** 补充: 主要作用:内存可见性,是变量在多个线程中可见,修饰变量,解决一写多读的问题. 轻量级的synchronized,不会造成阻塞.性能比s ...
- RocketMQ存储机制与确认重传机制
引子 消息队列之前就听说过,但一直没有学习和接触,直到最近的工作流引擎项目用到,需要了解学习一下.本文主要从一个初学者的角度针对RocketMQ的存储机制和确认重传机制做一个浅显的总结. 存储机制 我 ...
随机推荐
- Java 8升级Java 11,升级必知要点!竟然有这些坑…
随着技术的不断进步,Java作为一种广泛使用的编程语言,其版本更新带来了许多新特性和性能提升.从Java 8升级到Java 11,是一个重要的转变,它不仅带来了新的编程范式,还引入了对现代软件开发的多 ...
- 一篇文章彻底搞懂TiDB集群各种容量计算方式
背景 TiDB 集群的监控面板里面有两个非常重要.且非常常用的指标,相信用了 TiDB 的都见过: Storage capacity:集群的总容量 Current storage size:集群当前已 ...
- 详解MRS HBase全局二级索引
本文分享自华为云社区<MRS HBase全局二级索引原理与使用场景>,作者:学习一下大数据 . 一.HBase二级索引背景介绍 HBase是基于Key-Value的分布式存储数据库,对表中 ...
- 【技术控请进】华为云DevCloud深色模式开发解读
引言 近期,华为云DevCloud推出了开发者友好的深色模式,深受开发者们的喜爱和关注.大家都知道,深色模式(Dark Mode)在iOS13 引入该特性后各大应用和网站都开始支持了深色模式.在这之前 ...
- 华为云FusionInsight助力宇宙行打造金融数据湖新标杆
摘要:工行采用了华为云FusionInsight MRS大数据存算分离方案,实现了大数据平台与OBS对象存储服务的对接,将原有的HDFS数据无缝迁移到OBS上.在保证性能的前提下,实现了计算与存储独立 ...
- 关于GaussDB(DWS)的正则表达式知多少?人人都能看得懂的详解来了!
摘要:GaussDB(DWS)除了支持标准的POSIX正则表达式句法,还拥有一些特殊句法和选项,这些你可了解?本文便为你讲解这些特殊句法和选项. 概述 正则表达式(Regular Expression ...
- CartoonGAN论文复现:如何将图像动漫化
摘要:本案例是 CartoonGAN: Generative Adversarial Networks for Photo Cartoonization的论文复现案例. 本文分享自华为云社区<c ...
- 快来一起玩转LiteOS组件:Curl
摘要:Curl是一个文件传输工具,常用于数据上传和下载,本demo基于Cloud_STM32F429IGTx_FIRE开发板演示了在curl demo中调用curl提供的API来下载一个文件,并将其保 ...
- 最新的iOS应用上架App Store详细流程解析
最新的iOS应用上架App Store详细流程解析 2023已经过了2/3的时间,由于现在苹果签名市场的价格不断的上升,现在很多的开发商一直在想着如何进行上架一些自己的产品,下面小编来给大家梳理一下上 ...
- 8个方法管理 GitHub 用户权限
如同世界正在经历的疫情,由于网络攻击的大幅增加,许多公司也遭受着"网络疫情",保障代码安全迫在眉睫.在之前的文章中我们了解了安全使用 GitHub 的21条最佳实践.阅读本文,将带 ...