基于keras的双层LSTM网络和双向LSTM网络
1 前言
基于keras的双层LSTM网络和双向LSTM网络中,都会用到 LSTM层,主要参数如下:
LSTM(units,input_shape,return_sequences=False)
- units:隐藏层神经元个数
- input_shape=(time_step, input_feature):time_step是序列递归的步数,input_feature是输入特征维数
- return_sequences: 取值为True,表示每个时间步的值都返回;取值为False,表示只返回最后一个时间步的取值
本文以MNIST手写数字分类为例,讲解双层LSTM网络和双向LSTM网络的实现。关于MNIST数据集的说明,见使用TensorFlow实现MNIST数据集分类。
笔者工作空间如下:

代码资源见--> 双隐层LSTM和双向LSTM
2 双层LSTM网络
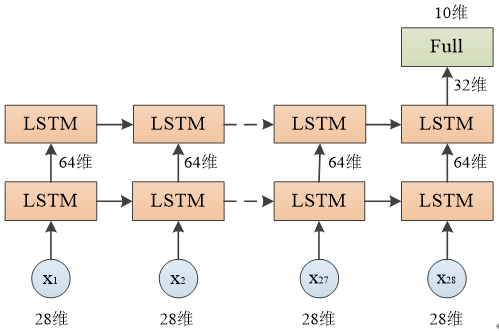 双层LSTM网络结构
双层LSTM网络结构
DoubleLSTM.py
from tensorflow.examples.tutorials.mnist import input_data
from keras.models import Sequential
from keras.layers import Dense,LSTM
#载入数据
def read_data(path):
mnist=input_data.read_data_sets(path,one_hot=True)
train_x,train_y=mnist.train.images.reshape(-1,28,28),mnist.train.labels,
valid_x,valid_y=mnist.validation.images.reshape(-1,28,28),mnist.validation.labels,
test_x,test_y=mnist.test.images.reshape(-1,28,28),mnist.test.labels
return train_x,train_y,valid_x,valid_y,test_x,test_y
#双层LSTM模型
def DoubleLSTM(train_x,train_y,valid_x,valid_y,test_x,test_y):
#创建模型
model=Sequential()
model.add(LSTM(64,input_shape=(28,28),return_sequences=True)) #返回所有节点的输出
model.add(LSTM(32,return_sequences=False)) #返回最后一个节点的输出
model.add(Dense(10,activation='softmax'))
#查看网络结构
model.summary()
#编译模型
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
#训练模型
model.fit(train_x,train_y,batch_size=500,nb_epoch=15,verbose=2,validation_data=(valid_x,valid_y))
#评估模型
pre=model.evaluate(test_x,test_y,batch_size=500,verbose=2)
print('test_loss:',pre[0],'- test_acc:',pre[1])
train_x,train_y,valid_x,valid_y,test_x,test_y=read_data('MNIST_data')
DoubleLSTM(train_x,train_y,valid_x,valid_y,test_x,test_y)
每层网络输出尺寸:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_5 (LSTM) (None, 28, 64) 23808
_________________________________________________________________
lstm_6 (LSTM) (None, 32) 12416
_________________________________________________________________
dense_5 (Dense) (None, 10) 330
=================================================================
Total params: 36,554
Trainable params: 36,554
Non-trainable params: 0
由于第一个LSTM层设置了 return_sequences=True,每个节点的输出值都会返回,因此输出尺寸为 (None, 28, 64)
由于第二个LSTM层设置了 return_sequences=False,只有最后一个节点的输出值会返回,因此输出尺寸为 (None, 32)
训练结果:
Epoch 13/15
- 17s - loss: 0.0684 - acc: 0.9796 - val_loss: 0.0723 - val_acc: 0.9792
Epoch 14/15
- 18s - loss: 0.0633 - acc: 0.9811 - val_loss: 0.0659 - val_acc: 0.9822
Epoch 15/15
- 17s - loss: 0.0597 - acc: 0.9821 - val_loss: 0.0670 - val_acc: 0.9812
test_loss: 0.0714278114028275 - test_acc: 0.9789000034332276
3 双向LSTM网络
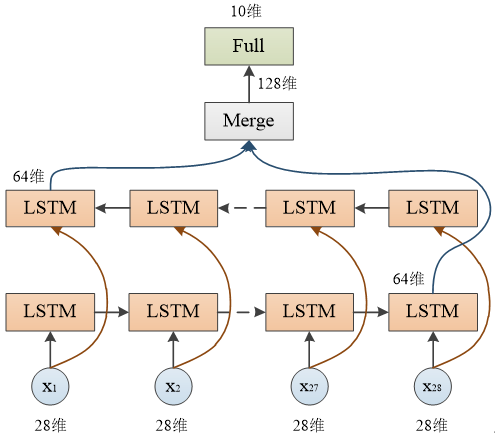 双向LSTM网络结构
双向LSTM网络结构
from tensorflow.examples.tutorials.mnist import input_data
from keras.models import Sequential
from keras.layers import Dense,LSTM,Bidirectional
#载入数据
def read_data(path):
mnist=input_data.read_data_sets(path,one_hot=True)
train_x,train_y=mnist.train.images.reshape(-1,28,28),mnist.train.labels,
valid_x,valid_y=mnist.validation.images.reshape(-1,28,28),mnist.validation.labels,
test_x,test_y=mnist.test.images.reshape(-1,28,28),mnist.test.labels
return train_x,train_y,valid_x,valid_y,test_x,test_y
#双向LSTM模型
def BiLSTM(train_x,train_y,valid_x,valid_y,test_x,test_y):
#创建模型
model=Sequential()
lstm=LSTM(64,input_shape=(28,28),return_sequences=False) #返回最后一个节点的输出
model.add(Bidirectional(lstm)) #双向LSTM
model.add(Dense(10,activation='softmax'))
#编译模型
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
#训练模型
model.fit(train_x,train_y,batch_size=500,nb_epoch=15,verbose=2,validation_data=(valid_x,valid_y))
#查看网络结构
model.summary()
#评估模型
pre=model.evaluate(test_x,test_y,batch_size=500,verbose=2)
print('test_loss:',pre[0],'- test_acc:',pre[1])
train_x,train_y,valid_x,valid_y,test_x,test_y=read_data('MNIST_data')
BiLSTM(train_x,train_y,valid_x,valid_y,test_x,test_y)
每层网络输出尺寸:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bidirectional_5 (Bidirection (None, 128) 47616
_________________________________________________________________
dense_6 (Dense) (None, 10) 1290
=================================================================
Total params: 48,906
Trainable params: 48,906
Non-trainable params: 0
由于LSTM层设置了 return_sequences=False,只有最后一个节点的输出值会返回,每层LSTM返回64维向量,两层合并共128维,因此输出尺寸为 (None, 128)
训练结果:
Epoch 13/15
- 22s - loss: 0.0512 - acc: 0.9839 - val_loss: 0.0632 - val_acc: 0.9790
Epoch 14/15
- 22s - loss: 0.0453 - acc: 0.9865 - val_loss: 0.0534 - val_acc: 0.9832
Epoch 15/15
- 22s - loss: 0.0418 - acc: 0.9869 - val_loss: 0.0527 - val_acc: 0.9830
test_loss: 0.06457789749838412 - test_acc: 0.9795000076293945
声明:本文转自基于keras的双层LSTM网络和双向LSTM网络
基于keras的双层LSTM网络和双向LSTM网络的更多相关文章
- 使用Keras进行深度学习:(六)LSTM和双向LSTM讲解及实践
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 介绍 长短期记忆(Long Short Term Memory, ...
- TensorFlow之RNN:堆叠RNN、LSTM、GRU及双向LSTM
RNN(Recurrent Neural Networks,循环神经网络)是一种具有短期记忆能力的神经网络模型,可以处理任意长度的序列,在自然语言处理中的应用非常广泛,比如机器翻译.文本生成.问答系统 ...
- LSTM和双向LSTM讲解及实践
LSTM和双向LSTM讲解及实践 目录 RNN的长期依赖问题LSTM原理讲解双向LSTM原理讲解Keras实现LSTM和双向LSTM 一.RNN的长期依赖问题 在上篇文章中介绍的循环神经网络RNN在训 ...
- 基于 Keras 用 LSTM 网络做时间序列预测
目录 基于 Keras 用 LSTM 网络做时间序列预测 问题描述 长短记忆网络 LSTM 网络回归 LSTM 网络回归结合窗口法 基于时间步的 LSTM 网络回归 在批量训练之间保持 LSTM 的记 ...
- 基于双向LSTM和迁移学习的seq2seq核心实体识别
http://spaces.ac.cn/archives/3942/ 暑假期间做了一下百度和西安交大联合举办的核心实体识别竞赛,最终的结果还不错,遂记录一下.模型的效果不是最好的,但是胜在“端到端”, ...
- 【中文分词系列】 4. 基于双向LSTM的seq2seq字标注
http://spaces.ac.cn/archives/3924/ 关于字标注法 上一篇文章谈到了分词的字标注法.要注意字标注法是很有潜力的,要不然它也不会在公开测试中取得最优的成绩了.在我看来,字 ...
- PaddlePaddle︱开发文档中学习情感分类(CNN、LSTM、双向LSTM)、语义角色标注
PaddlePaddle出教程啦,教程一部分写的很详细,值得学习. 一期涉及新手入门.识别数字.图像分类.词向量.情感分析.语义角色标注.机器翻译.个性化推荐. 二期会有更多的图像内容. 随便,帮国产 ...
- NLP(十九) 双向LSTM情感分类模型
使用IMDB情绪数据来比较CNN和RNN两种方法,预处理与上节相同 from __future__ import print_function import numpy as np import pa ...
- 基于keras实现的中文实体识别
1.简介 NER(Named Entity Recognition,命名实体识别)又称作专名识别,是自然语言处理中常见的一项任务,使用的范围非常广.命名实体通常指的是文本中具有特别意义或者指代性非常强 ...
- [深度应用]·首届中国心电智能大赛初赛开源Baseline(基于Keras val_acc: 0.88)
[深度应用]·首届中国心电智能大赛初赛开源Baseline(基于Keras val_acc: 0.88) 个人主页--> https://xiaosongshine.github.io/ 项目g ...
随机推荐
- SpringMVC02——第一个MVC程序-配置版(low版)
配置版 新建一个子项目,添加Web支持![在MVC01中有详细方法] 确定导入了SpringMVC的依赖 配置web.xml,注册DispatcherServlet <?xml version= ...
- [转帖]nginx优化配置及方法论
https://www.jianshu.com/p/87f8c03e91bd 1.优化方法论 从软件层面提升硬件使用效率 增大CPU的利用率 增大内存的利用率 增大磁盘IO的利用率 增大网络带宽的利用 ...
- [转帖]Shell三剑客之awk
目录 awk简述 awk的工作过程 awk的工作原理 awk的基本格式及其内置变量 getline 文本内容匹配过滤打印 对字段进行处理打印 条件判断打印 awk的三元表达式与精准筛选用法 awk的精 ...
- [转帖]Tomcat部署及优化
目录 一.Tomcat简介 1 Tomcat的三大核心组件 2 Java Servlet 3 JSP全称Java Server Pages 4 Tomcat 功能组件结构 5 Tomcat 请求过程 ...
- [转帖]k8s对接ceph,ceph-csi方式
1.上传ceph-csi-yaml和ceph-csi-image 两个文件夹到服务器 2.加载 ceph-csi-image里面的镜像 3.将加载好的镜像上传到本地harbor上. 4.修改ceph- ...
- [转帖]手摸手搭建简单的jmeter+influxdb+grafana性能监控平台
我安装的机器是阿里云的centos8机器,其他的系统暂未验证 1.安装influxdb influxdb 下载地址https://portal.influxdata.com/downloads/,也可 ...
- SQLServer Core 序列号使用CPU限制的处理
SQLServer Core 序列号使用CPU限制的处理 背景 有客户是SQLSERVER的数据库. 说要进行一下压测. 这边趁着最后进行一下环境的基础搭建工作. 然后在全闪的环境上面搭建了一个Win ...
- 【转帖】数据库篇-MySql架构介绍
https://zhuanlan.zhihu.com/p/147161770 公众号-坚持原创,码字不易.加微信 : touzinv 关注分享,手有余香~ 本篇咱们也来聊聊mysql物理和逻辑架构,还 ...
- [转帖]ESXi下查看CPU 频率
https://www.jianshu.com/p/8943a4223ed7 查看CPU的固定频率 [root@localhost:/bin] esxcli hardware cpu list|gr ...
- [转帖] 使用socat反向Shell多台机器
https://www.cnblogs.com/codelogs/p/16012319.html 场景# 很多时候,我们需要批量操作多台机器,业界一般使用Ansible来实现,但使用Ansible来操 ...