机器学习-无监督机器学习-密度聚类DBSCAN-19
1. DBSCAN
Density based clustering
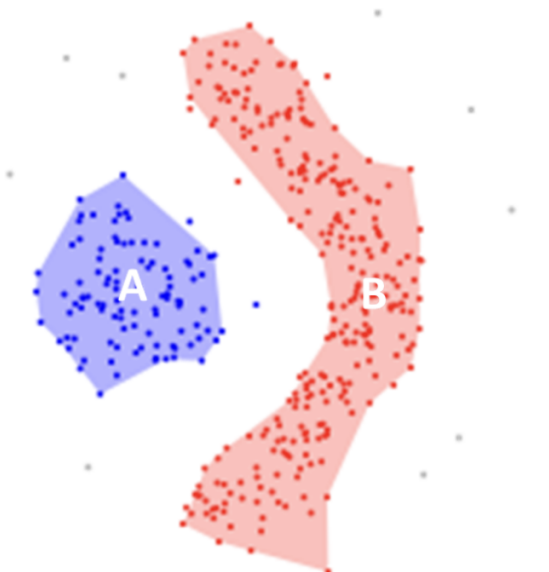
DBSCAN不要求我们指定cluster簇的数量,避免了异常值,并且在任意形状和大小的cluster簇中工作得非常好。它没有质心,聚类簇是通过将相邻的点连接在一起的过程形成的。
超参数:
Epsilon (ɛ):设置的最大半径。
最小点数目(minPts):在一个邻域的半径内minPts数的邻域被认为是一个簇。请记住,初始点包含在minPts中。
核心点:在其近邻距离内至少有minPts个数据点。
对核心点的邻域内的每个点进行评估,以确定它是否在epsilon距离内有minPts (minPts包括点本身)。如果该点满足minPts标准,它将成为另一个核心点,cluster簇将扩展。如果一个点不满足minPts标准,它成为边界点。
离群点:这些点不是近邻点,也不是边界点。这些点位于低密度地区。
2. OPTICS
Ordering Points To Identify Cluster Structure
目标是识别聚类的内部结构
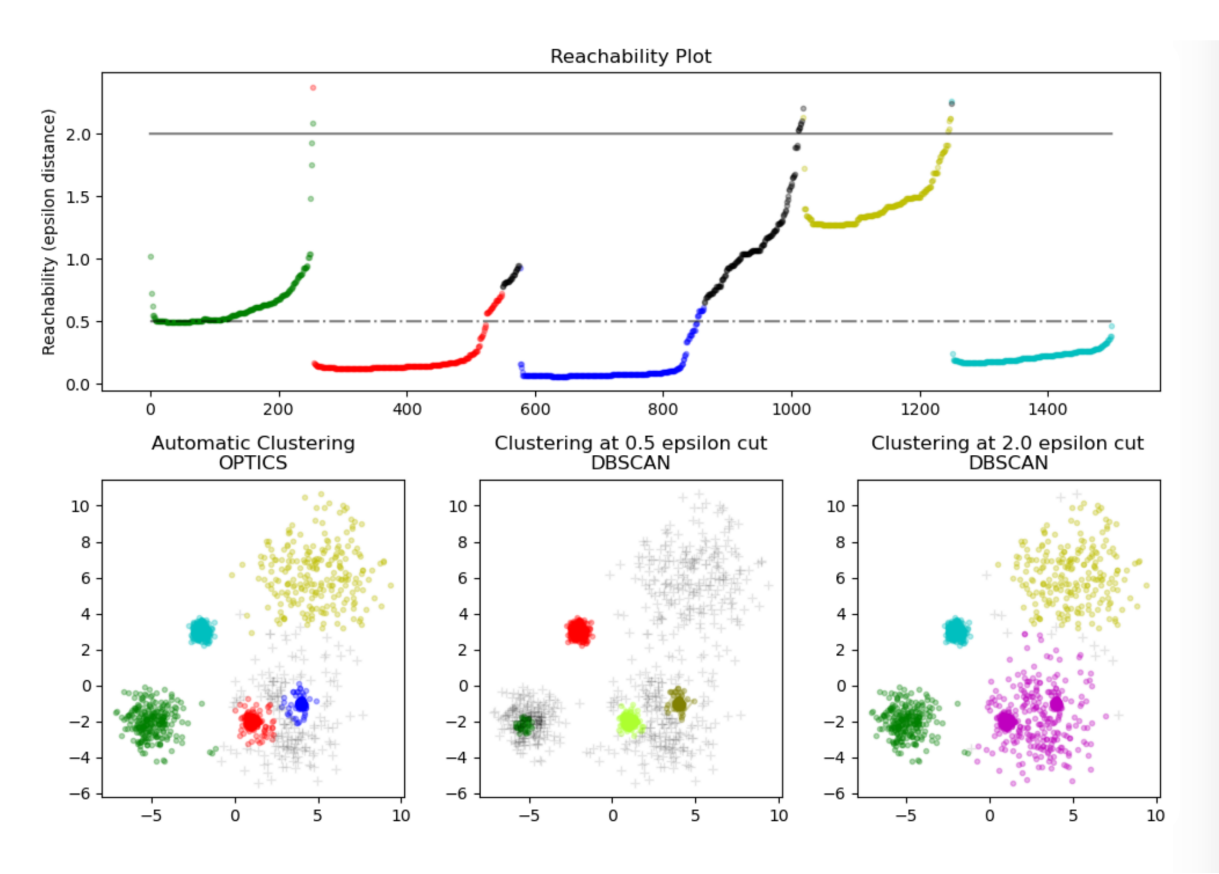
这个算法本身核心并不直接划分数据到不同的聚类簇。它仅生成一个关于可达距离(纵轴)图形,然后再去读取这个图形做进一步的 聚类。这个图形本质上记录了数据点被处理的顺序(横轴),而
不是数据点的具体划分。这是与DBSCAN最大的不同。
可达距离图:
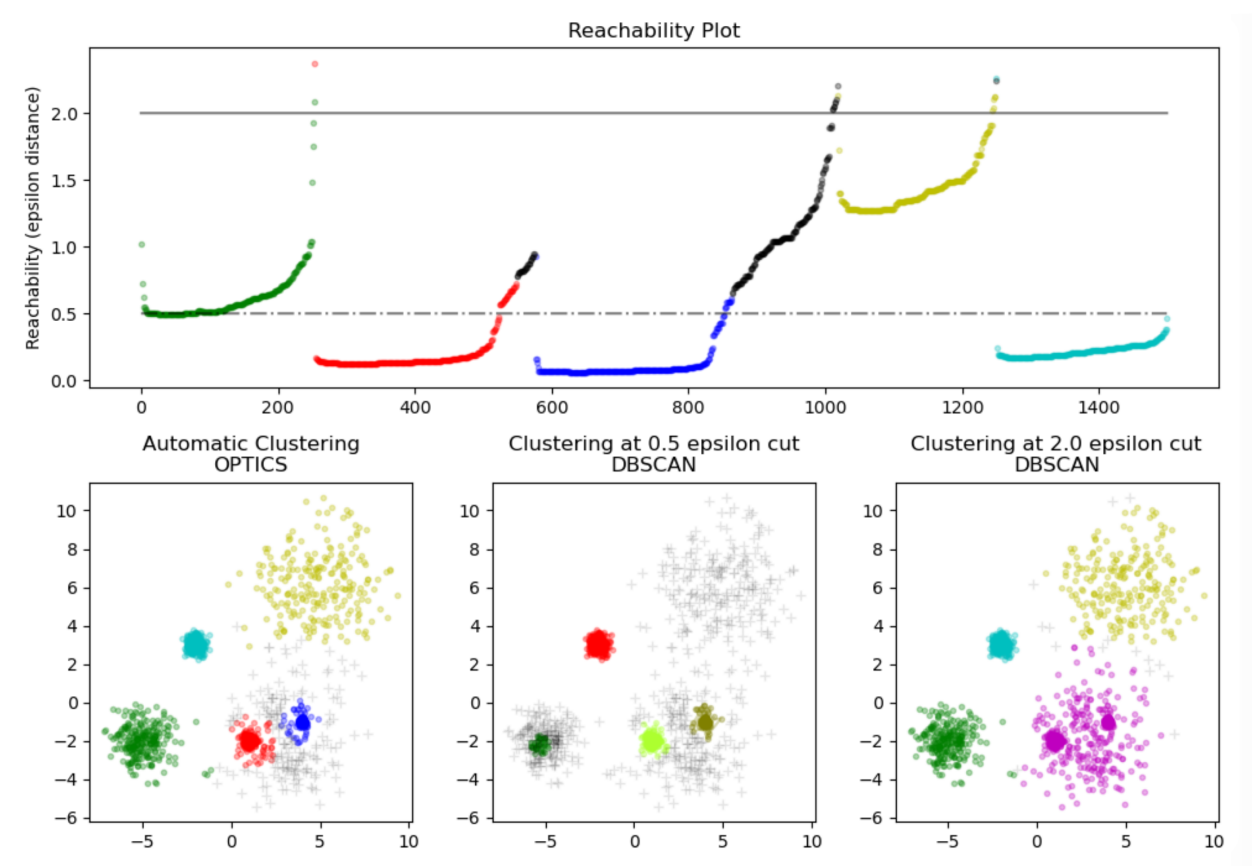
在DBCSAN算法中需要输入两个参数:epsilon和minPts ,选择不同的参数会导致最终聚类的结果千差万别,因此DBCSAN对于输入参数过于敏感。OPTICS算法的提出就是为了帮助DBSCAN算法选择合适的参数,降低输入参数的敏感度。
两个重要的概念:
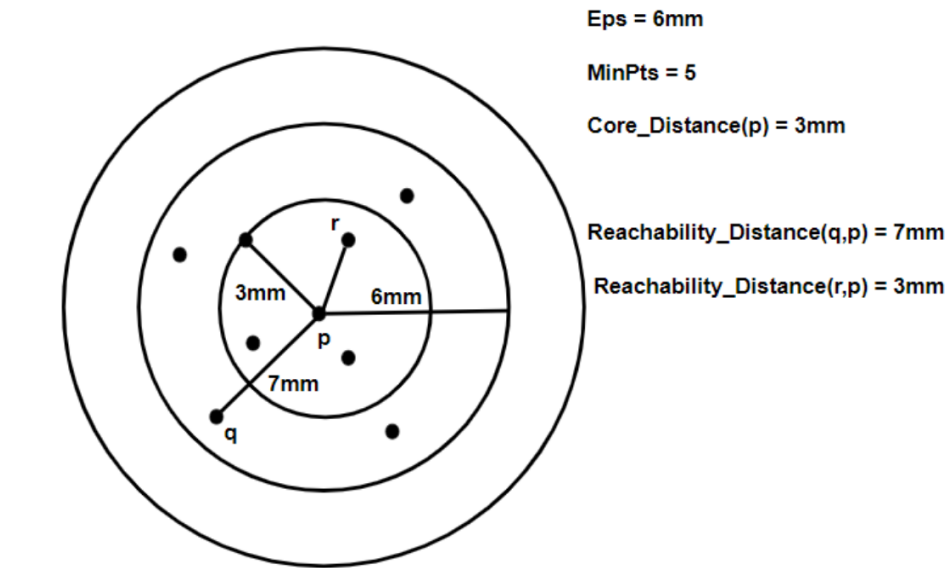
核心距离:是确定一个给定点是核心点的半径最小值。如果给定点不是一个核心点,那么它的核心距离是 无穷大。
可达距离:
定义相对其它数据点q。点p和q之间的可达距离是p点的核心距离与p和q之间的欧氏距离的最大值 max(core_dist(p), eula(p, q))
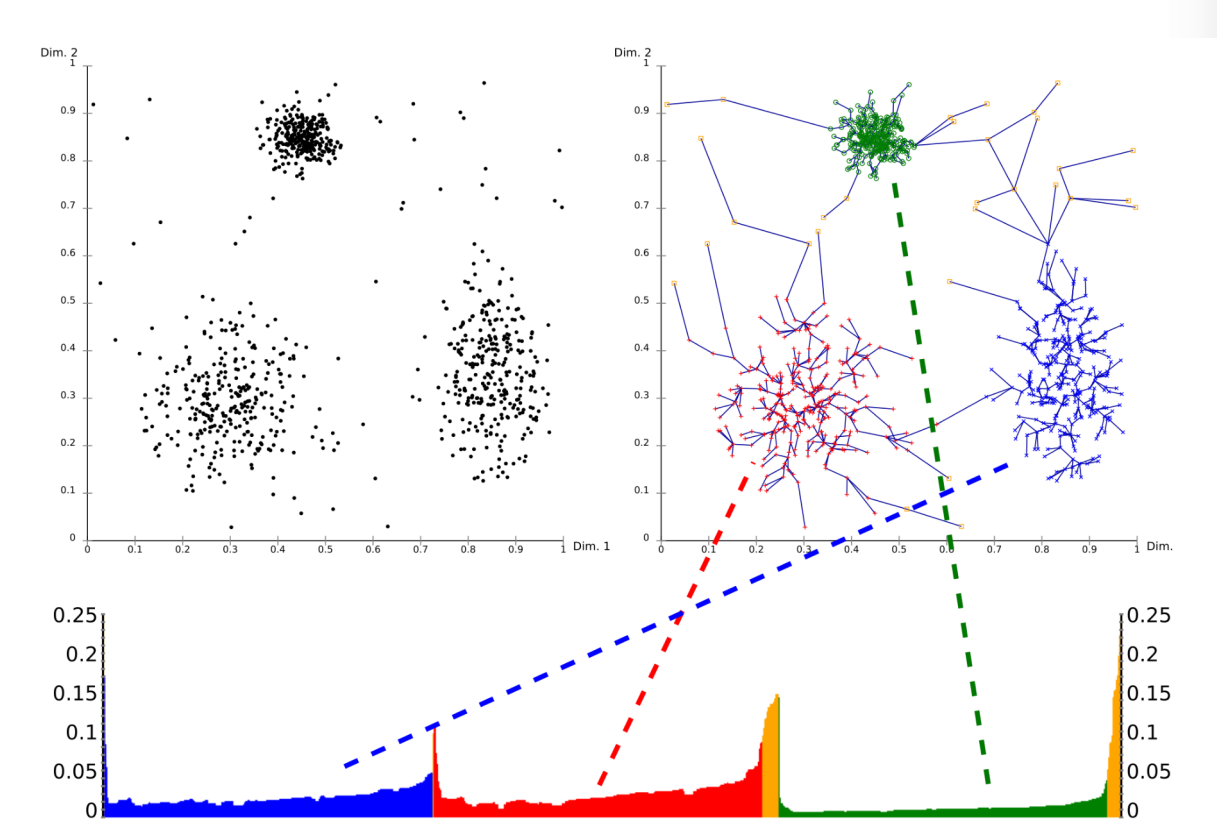
仔细品味这两张 可达距离 云图
2. MeanShift
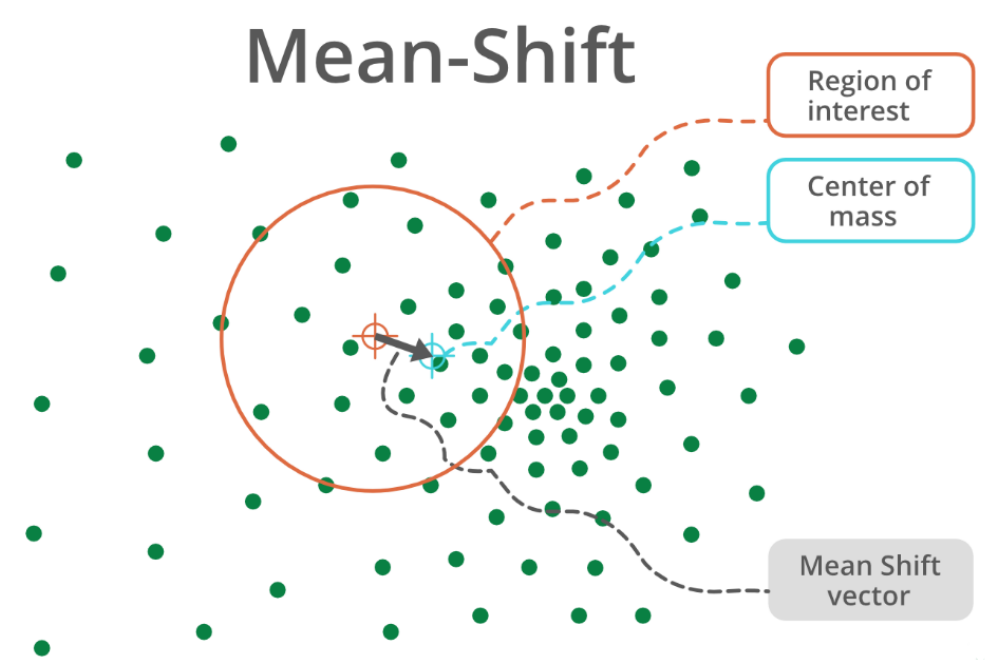
均值漂移, 在目标追踪中应用广泛。本身其实是一种基于密度的聚类算法。
计算某一点A与其周围半径R内的向量距离的平均值M,计算出该点下一步漂移(移动)的方向(A=M+A)
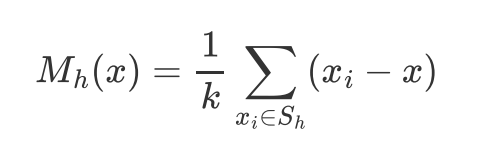
MeanShift向量表示区域中k个样本点相对于点x求偏移量再平均,求出来的向量指向概率密度梯度的方向(指向真实质心方向)。
MeanShift的扩展:
不同的簇包含的数据看成是正太分布采样得到的。

机器学习-无监督机器学习-密度聚类DBSCAN-19的更多相关文章
- 吴裕雄 python 机器学习——密度聚类DBSCAN模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 密度聚类 - DBSCAN算法
参考资料:python机器学习库sklearn——DBSCAN密度聚类, Python实现DBScan import numpy as np from sklearn.cluster impo ...
- 聚类——密度聚类DBSCAN
Clustering 聚类 密度聚类——DBSCAN 前面我们已经介绍了两种聚类算法:k-means和谱聚类.今天,我们来介绍一种基于密度的聚类算法——DBSCAN,它是最经典的密度聚类算法,是很多算 ...
- 31(1).密度聚类---DBSCAN算法
密度聚类density-based clustering假设聚类结构能够通过样本分布的紧密程度确定. 密度聚类算法从样本的密度的角度来考察样本之间的可连接性,并基于可连接样本的不断扩张聚类簇,从而获得 ...
- 密度聚类 DBSCAN
刘建平:DBSCAN密度聚类算法 https://www.cnblogs.com/pinard/p/6208966.html API 的说明: https://www.jianshu.com/p/b0 ...
- 机器学习(十)—聚类算法(KNN、Kmeans、密度聚类、层次聚类)
聚类算法 任务:将数据集中的样本划分成若干个通常不相交的子集,对特征空间的一种划分. 性能度量:类内相似度高,类间相似度低.两大类:1.有参考标签,外部指标:2.无参照,内部指标. 距离计算:非负性, ...
- <机器学习>无监督学习算法总结
本文仅对常见的无监督学习算法进行了简单讲述,其他的如自动编码器,受限玻尔兹曼机用于无监督学习,神经网络用于无监督学习等未包括.同时虽然整体上分为了聚类和降维两大类,但实际上这两类并非完全正交,很多地方 ...
- 基于密度聚类的DBSCAN和kmeans算法比较
根据各行业特性,人们提出了多种聚类算法,简单分为:基于层次.划分.密度.图论.网格和模型的几大类. 其中,基于密度的聚类算法以DBSCAN最具有代表性. 场景 一 假设有如下图的一组数据, 生成数据 ...
- 学习笔记CB008:词义消歧、有监督、无监督、语义角色标注、信息检索、TF-IDF、隐含语义索引模型
词义消歧,句子.篇章语义理解基础,必须解决.语言都有大量多种含义词汇.词义消歧,可通过机器学习方法解决.词义消歧有监督机器学习分类算法,判断词义所属分类.词义消歧无监督机器学习聚类算法,把词义聚成多类 ...
- 1(1).有监督 VS 无监督
对比一 : 有标签 vs 无标签 有监督机器学习又被称为“有老师的学习”,所谓的老师就是标签.有监督的过程为先通过已知的训练样本(如已知输入和对应的输出)来训练,从而得到一个最优模型,再将这个模型应用 ...
随机推荐
- Spring Cache + Caffeine的整合与使用
前言 对于一些项目里需要对数据库里的某些数据一直重复请求的,且这些数据基本是固定的,在这种情况下,可以借助简单使用本地缓存来缓存这些数据.这些介绍一下Spring Cache和Caffeine的使用. ...
- U盘加密技术有哪些先进的保护措施?
华企盾DSC数据防泄密系统的U盘加密技术采用了一系列先进的保护措施,以确保高水平的数据安全.系统采用强大的加密算法,如AES256(高级加密标准),确保对U盘中的数据进行不可逆的强加密,防范了未经授权 ...
- 2023.3 Idea配置Tomcat环境
tomcat配置 下载tomcat 先到官网(按住Ctrl再左键点击直接打开官网)下载64位的tomcat,网速慢就用魔法下 创建项目.模块 打开idea(我用的是最新的idea的专业版,ui有点变化 ...
- Kafka干货之「零拷贝」
一.背景 周所周知,Kafka是一个非常成熟的消息产品,开源社区也已经经历了多年的不断迭代,特性列表更是能装下好几马车,比如:幂等消息.事务支持.多副本高可用.ACL.Auto Rebalance.H ...
- 【WALT】调度与负载计算(未更新完)
[WALT]调度与负载计算 代码版本:Linux4.9 android-msm-crosshatch-4.9-android12 注:本文中的任务主要指进程. @ 目录 [WALT]调度与负载计算 一 ...
- 手写spring的ioc的流程截图(笔记-1)
spring ioc是什么? IoC 容器是 Spring 的核心,也可以称为 Spring 容器.Spring 通过 IoC 容器来管理对象的实例化和初始化,以及对象从创建到销毁的整个生命周期. S ...
- HDU 4641 K string 后缀自动机
原题链接 题意 每个测试点,一开始给我们n,m,k然后是一个长度为n的字符串. 之后m次操作,1 c是往字符串后面添加一个字符c,2是查询字符串中出现k次以及以上的子串个数,m为2e5 思路 首先可以 ...
- Llama2-Chinese项目:6-模型评测
测试问题筛选自AtomBulb[1],共95个测试问题,包含:通用知识.语言理解.创作能力.逻辑推理.代码编程.工作技能.使用工具.人格特征八个大的类别. 1.测试中的Prompt 例如对于问 ...
- 共筑数字化未来,金山办公携手华为云完成文档中心和GaussDB适配
摘要:金山办公携手华为云完成金山办公自主研发的"WPS文档中心系统"与华为云GaussDB相互兼容性测试认证,并获得华为云授予的<技术认证书>. 本文分享自华为云社区& ...
- 实践丨GaussDB(DWS)资源管理排队原理与问题定位
摘要:GaussDB(DWS)提供了资源管理功能,用户可以根据自身业务情况对资源进行划分,将资源按需划分成不同的资源池,不同资源池之间资源互相隔离. 本文分享自华为云社区<GaussDB(DWS ...