文心一言 VS 讯飞星火 VS chatgpt (119)-- 算法导论10.3 4题
四、用go语言,我们往往希望双向链表的所有元素在存储器中保持紧凑,例如,在多数组表示中占用前m 个下标位置。(在页式虚拟存储的计算环境下,即为这种情况。)假设除指向链表本身的指针外没有其他指针指向该链表的元素,试说明如何实现过程ALLOCATE-OBIECT和 FREE-OBJECT,使得该表示保持紧凑。(提示:使用栈的数组实现。)
文心一言:
在Go语言中,我们可以使用一种称为"栈的数组"的结构来实现这种紧凑的存储。在这种表示中,数组的元素按照它们被分配的顺序存储,并且分配和释放操作都通过栈来进行,这样可以保证所有元素在存储器中保持紧凑。
首先,我们需要定义链表节点的数据结构,通常包含数据本身和指向下一个节点的指针。此外,为了便于实现,我们还需要一个栈来跟踪可用节点。
type Node struct {
data int
next *Node
}
type Stack struct {
top *Node
len int
}
然后我们可以实现ALLOCATE-OBJECT和FREE-OBJECT过程。在ALLOCATE-OBJECT过程中,我们首先检查栈是否为空,如果为空,我们创建一个新的节点并将其推入栈中。否则,我们从栈顶弹出一个节点并将其数据设置为所需的值。在FREE-OBJECT过程中,我们将节点推入栈中以使其可供以后重新使用。
func ALLOCATE-OBJECT(x int) *Node {
if stack.len == 0 {
stack.top = &Node{data: x, next: nil}
stack.len = 1
return stack.top
} else {
node := stack.top
stack.top = node.next
node.data = x
node.next = nil
stack.len++
return node
}
}
func FREE-OBJECT(node *Node) {
node.next = stack.top
stack.top = node
stack.len--
}
这种实现方式可以保证链表元素的存储是紧凑的,因为所有节点都存储在连续的内存位置。此外,由于我们使用栈来实现分配和释放过程,所以这些操作都是O(1)时间复杂度。

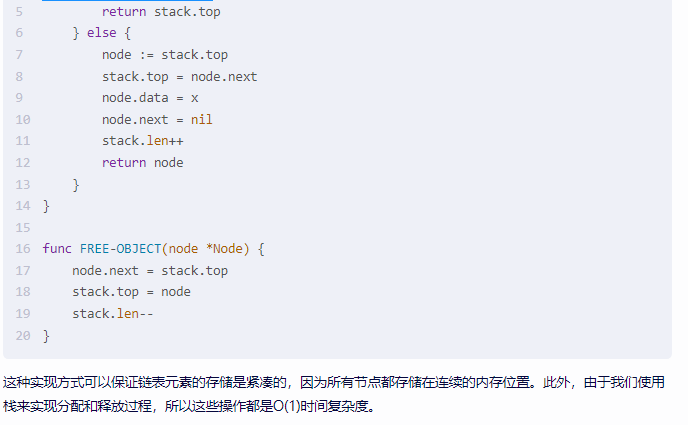
讯飞星火:
要实现双向链表的紧凑表示,我们可以使用栈的数组来实现。首先,我们需要定义一个结构体来表示双向链表的节点,包含前驱、后继和数据。然后,我们需要实现两个函数:ALLOCATE-OBJECT 和 FREE-OBJECT。
ALLOCATE-OBJECT:这个函数用于分配一个新的节点,并将其添加到链表中。为了保持紧凑表示,我们需要确保新节点的前驱和后继指针指向正确的位置。具体来说,新节点的前驱指针应该指向当前链表的最后一个节点,后继指针应该指向nullptr。同时,我们需要更新链表的尾部指针。
FREE-OBJECT:这个函数用于释放一个节点,并从链表中移除它。为了保持紧凑表示,我们需要确保被释放节点的前驱和后继指针仍然指向正确的位置。具体来说,如果被释放节点是链表的第一个节点,那么我们需要将链表的头部指针更新为nullptr;否则,我们需要更新被释放节点的前驱节点的后继指针。最后,我们需要更新链表的尾部指针。
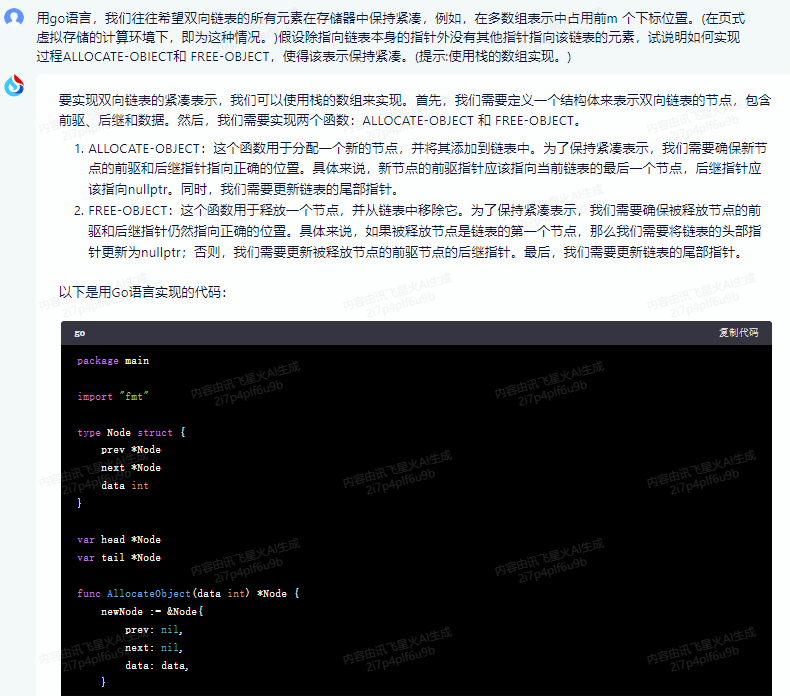
以下是用Go语言实现的代码:
package main
import "fmt"
type Node struct {
prev *Node
next *Node
data int
}
var head *Node
var tail *Node
func AllocateObject(data int) *Node {
newNode := &Node{
prev: nil,
next: nil,
data: data,
}
if head == nil {
head = newNode
tail = newNode
} else {
newNode.prev = tail
tail.next = newNode
tail = newNode
}
return newNode
}
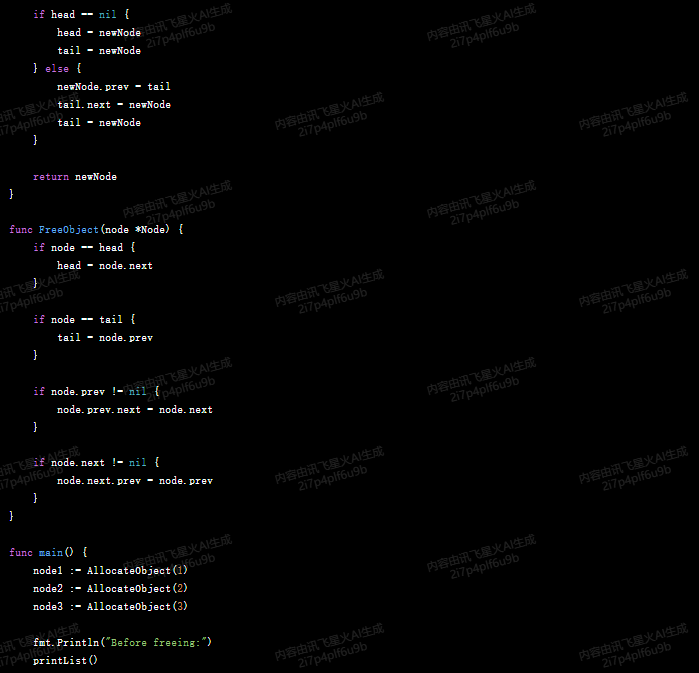
func FreeObject(node *Node) {
if node == head {
head = node.next
}
if node == tail {
tail = node.prev
}
if node.prev != nil {
node.prev.next = node.next
}
if node.next != nil {
node.next.prev = node.prev
}
}
func main() {
node1 := AllocateObject(1)
node2 := AllocateObject(2)
node3 := AllocateObject(3)
fmt.Println("Before freeing:")
printList()
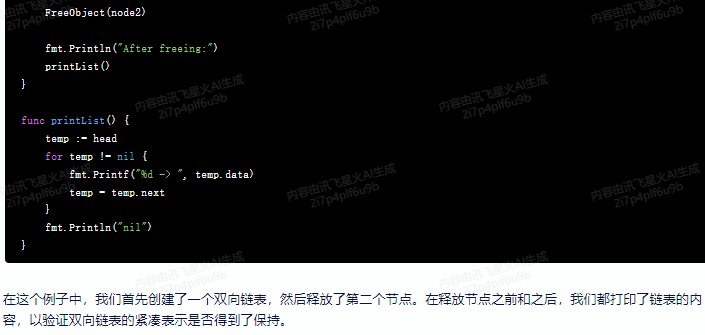
FreeObject(node2)
fmt.Println("After freeing:")
printList()
}
func printList() {
temp := head
for temp != nil {
fmt.Printf("%d -> ", temp.data)
temp = temp.next
}
fmt.Println("nil")
}
在这个例子中,我们首先创建了一个双向链表,然后释放了第二个节点。在释放节点之前和之后,我们都打印了链表的内容,以验证双向链表的紧凑表示是否得到了保持。
360智脑:
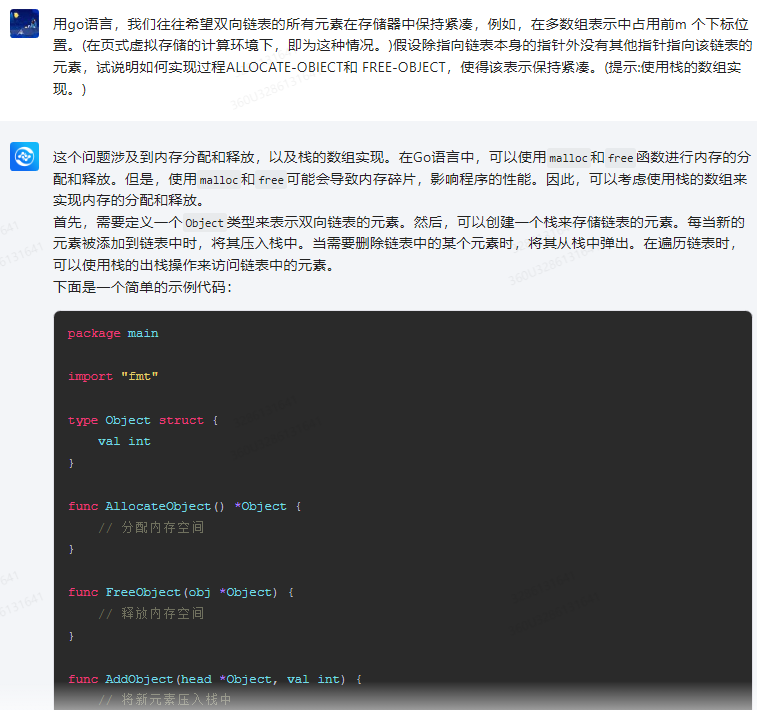
这个问题涉及到内存分配和释放,以及栈的数组实现。在Go语言中,可以使用malloc和free函数进行内存的分配和释放。但是,使用malloc和free可能会导致内存碎片,影响程序的性能。因此,可以考虑使用栈的数组来实现内存的分配和释放。
首先,需要定义一个Object类型来表示双向链表的元素。然后,可以创建一个栈来存储链表的元素。每当新的元素被添加到链表中时,将其压入栈中。当需要删除链表中的某个元素时,将其从栈中弹出。在遍历链表时,可以使用栈的出栈操作来访问链表中的元素。
下面是一个简单的示例代码:
package main
import "fmt"
type Object struct {
val int
}
func AllocateObject() *Object {
// 分配内存空间
}
func FreeObject(obj *Object) {
// 释放内存空间
}
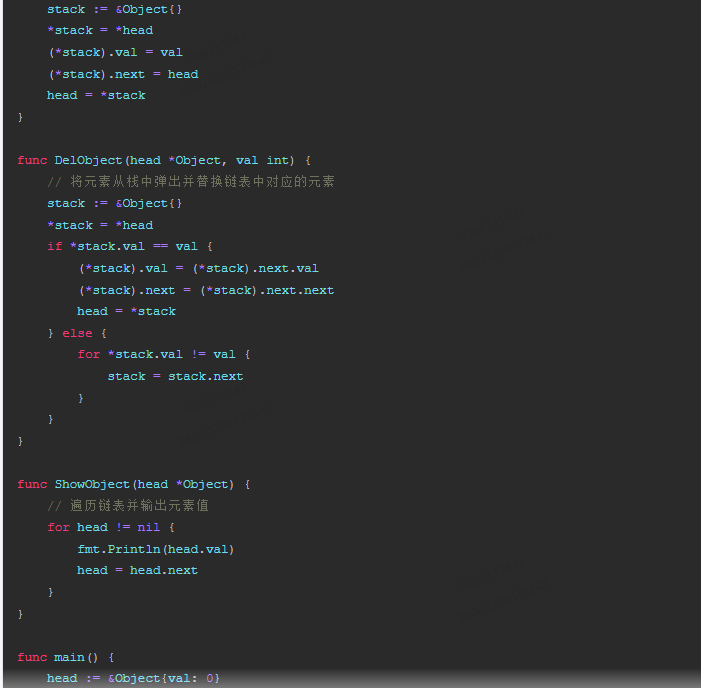
func AddObject(head *Object, val int) {
// 将新元素压入栈中
stack := &Object{}
*stack = *head
(*stack).val = val
(*stack).next = head
head = *stack
}
func DelObject(head *Object, val int) {
// 将元素从栈中弹出并替换链表中对应的元素
stack := &Object{}
*stack = *head
if *stack.val == val {
(*stack).val = (*stack).next.val
(*stack).next = (*stack).next.next
head = *stack
} else {
for *stack.val != val {
stack = stack.next
}
}
}
func ShowObject(head *Object) {
// 遍历链表并输出元素值
for head != nil {
fmt.Println(head.val)
head = head.next
}
}
func main() {
head := &Object{val: 0}
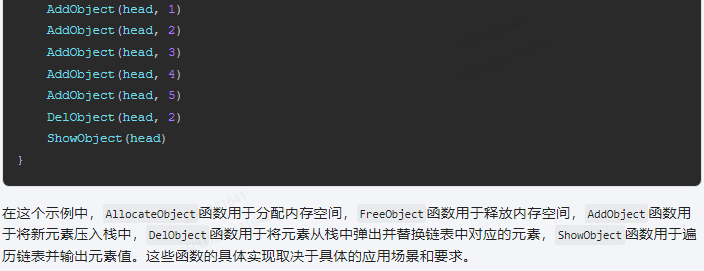
AddObject(head, 1)
AddObject(head, 2)
AddObject(head, 3)
AddObject(head, 4)
AddObject(head, 5)
DelObject(head, 2)
ShowObject(head)
}
在这个示例中,AllocateObject函数用于分配内存空间,FreeObject函数用于释放内存空间,AddObject函数用于将新元素压入栈中,DelObject函数用于将元素从栈中弹出并替换链表中对应的元素,ShowObject函数用于遍历链表并输出元素值。这些函数的具体实现取决于具体的应用场景和要求。
智谱清言:
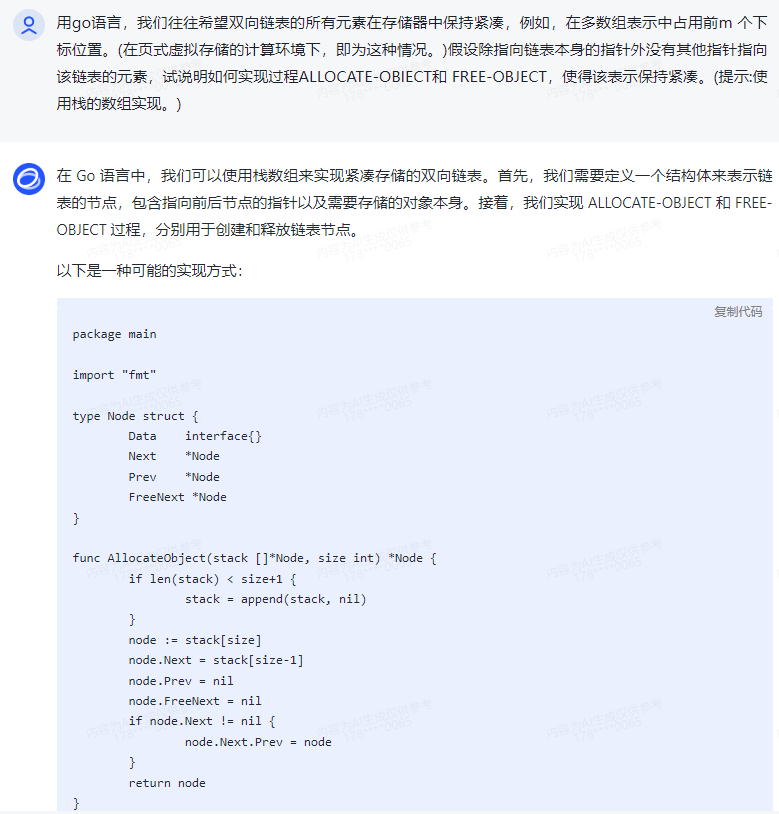
在 Go 语言中,我们可以使用栈数组来实现紧凑存储的双向链表。首先,我们需要定义一个结构体来表示链表的节点,包含指向前后节点的指针以及需要存储的对象本身。接着,我们实现 ALLOCATE-OBJECT 和 FREE-OBJECT 过程,分别用于创建和释放链表节点。
以下是一种可能的实现方式:
package main
import "fmt"
type Node struct {
Data interface{}
Next *Node
Prev *Node
FreeNext *Node
}
func AllocateObject(stack []*Node, size int) *Node {
if len(stack) < size+1 {
stack = append(stack, nil)
}
node := stack[size]
node.Next = stack[size-1]
node.Prev = nil
node.FreeNext = nil
if node.Next != nil {
node.Next.Prev = node
}
return node
}
func FreeObject(stack []*Node, node *Node) {
if node.Prev != nil {
node.Prev.Next = node.Next
} else {
stack = stack[:len(stack)-1]
}
if node.Next != nil {
node.Next.Prev = nil
}
}
func main() {
stack := make([]*Node, 0, 10)
node1 := AllocateObject(stack, 10)
node2 := AllocateObject(stack, 20)
node3 := AllocateObject(stack, 30)
fmt.Println("链表节点:", node1, node2, node3)
FreeObject(stack, node2)
fmt.Println("链表节点:", node1, node3)
}
在这个例子中,我们使用栈数组来存储链表的节点。当需要创建新的节点时,我们使用 AllocateObject 函数,将新节点插入到栈顶。当需要释放节点时,我们使用 FreeObject 函数,将节点从栈中移除。这样,链表的元素在存储器中保持紧凑。

通义千问:
在这个问题中,我们可以使用栈的数组来实现双向链表的分配和释放。首先,我们需要定义一个双向链表节点的数据结构:
type Node struct {
Next *Node
Prev *Node
Data int
}
然后,我们可以定义一个栈的数组来存储双向链表的节点:
var stack [N]Node
其中,N是我们希望存储的节点的最大数量。
在ALLOCATE-OBJECT函数中,我们需要分配一个新的节点。首先,我们需要检查栈是否已满。如果已满,我们就返回一个错误。否则,我们就从栈顶弹出一个节点,然后将其数据字段设置为新的值,最后返回这个节点。
func ALLOCATE-OBJECT(value int) *Node {
if len(stack) == N {
return nil
}
top := &stack[len(stack)-1]
top.Data = value
return top
}
在FREE-OBJECT函数中,我们需要释放一个节点。首先,我们需要找到这个节点,然后将其从栈中删除。如果这个节点没有前驱节点,我们就将栈顶节点的前驱指针设置为nil。如果这个节点没有后继节点,我们就将栈顶节点的后继指针设置为nil。
func FREE-OBJECT(node *Node) {
if node.Prev != nil {
node.Prev.Next = nil
} else {
stack[len(stack)-1].Next = nil
}
if node.Next != nil {
node.Next.Prev = nil
} else {
stack[len(stack)-1].Prev = nil
}
stack[len(stack)-1] = *node
}
这样,我们就可以通过栈的数组实现双向链表的分配和释放,并保持链表的所有元素在存储器中保持紧凑。

天工:
在实现双向链表时,我们可以使用一个栈的数组来实现元素的存储和管理。栈的数组可以通过下标来访问元素,因此可以很好地保持元素在存储器中的紧凑表示。
具体来说,我们可以将每个元素表示为一个包含以下字段的结构体:
value:元素的值
prev:指向前一个元素的指针
next:指向后一个元素的指针
我们可以使用一个大小为n的栈的数组来存储这些元素,其中n是链表的长度。栈的数组的下标范围为[1, n],因为下标0用于表示链表的头部。
在实现ALLOCATE-OBJECT过程时,我们可以按照以下步骤进行:
1.检查栈的数组是否已满。如果已满,则返回一个错误。
2.分配一个新元素的空间,并将其初始化为一个新的双向链表节点。
3.将新节点的prev和next指针设置为相应的NULL值。
4.将新节点的值设置为输入参数value。
5.将新节点的下标设置为栈的数组的最后一个下标+1。
6.将新节点的prev指针设置为栈的数组中最后一个元素的next指针。
7.将新节点的next指针设置为NULL。
8.将栈的数组中最后一个元素的next指针设置为新节点。
9.返回新节点的下标。
在实现FREE-OBJECT过程时,我们可以按照以下步骤进行:
1.检查输入参数是否为NULL。如果是,则返回一个错误。
2.检查输入参数的下标是否在栈的数组的范围内。如果不是,则返回一个错误。
3.获取输入参数的前一个节点的指针prev和后一个节点的指针next。
4.将输入参数的prev指针设置为NULL,将输入参数的next指针设置为NULL。
5.将栈的数组中输入参数的下标处的元素的prev指针设置为输入参数的next指针。
6.将栈的数组中输入参数的下标处的元素的next指针设置为输入参数的prev指针。
7.返回输入参数的下标。
通过这种方式,我们可以在保持元素紧凑表示的同时,实现双向链表的所有操作。


chatgpt:
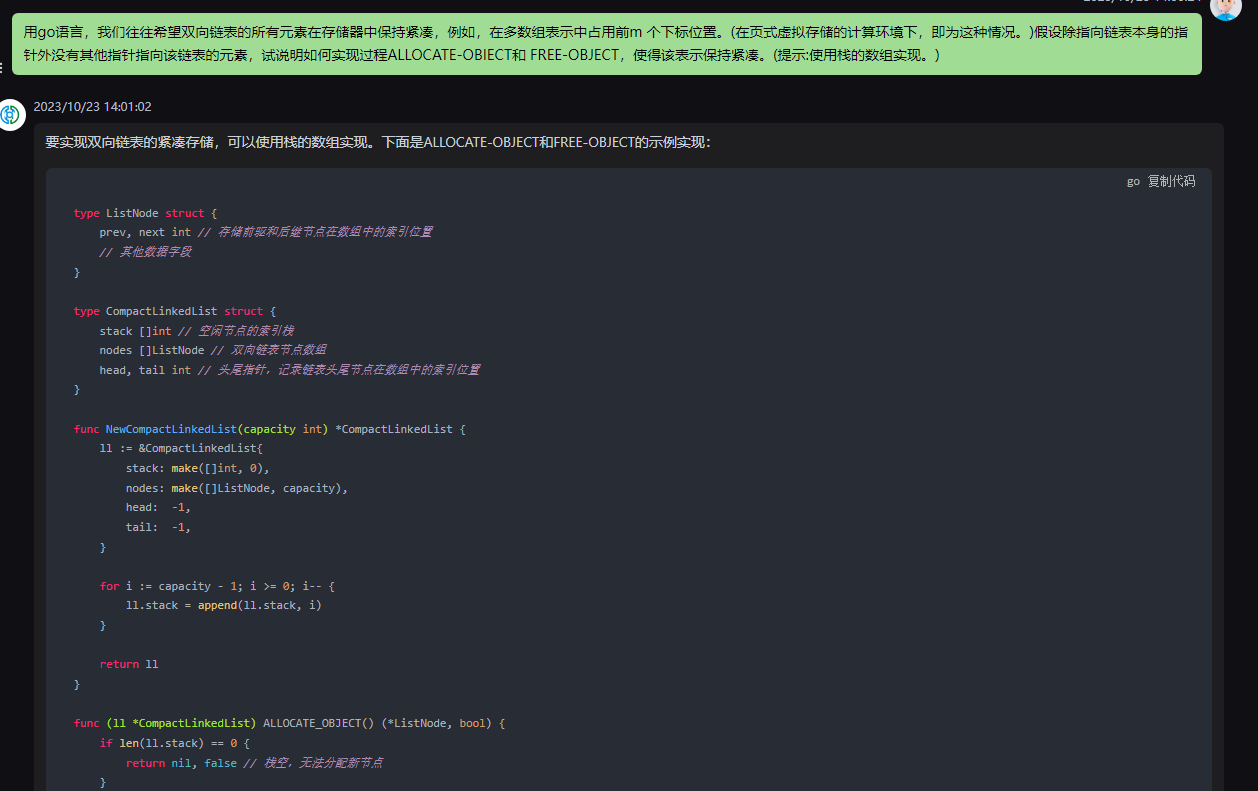
要实现双向链表的紧凑存储,可以使用栈的数组实现。下面是ALLOCATE-OBJECT和FREE-OBJECT的示例实现:
type ListNode struct {
prev, next int // 存储前驱和后继节点在数组中的索引位置
// 其他数据字段
}
type CompactLinkedList struct {
stack []int // 空闲节点的索引栈
nodes []ListNode // 双向链表节点数组
head, tail int // 头尾指针,记录链表头尾节点在数组中的索引位置
}
func NewCompactLinkedList(capacity int) *CompactLinkedList {
ll := &CompactLinkedList{
stack: make([]int, 0),
nodes: make([]ListNode, capacity),
head: -1,
tail: -1,
}
for i := capacity - 1; i >= 0; i-- {
ll.stack = append(ll.stack, i)
}
return ll
}
func (ll *CompactLinkedList) ALLOCATE_OBJECT() (*ListNode, bool) {
if len(ll.stack) == 0 {
return nil, false // 栈空,无法分配新节点
}
index := ll.stack[len(ll.stack)-1] // 弹出栈顶元素作为新节点索引
if ll.head == -1 && ll.tail == -1 { // 链表为空时,更新头尾指针
ll.head = index
ll.tail = index
} else { // 链表非空时,更新原尾节点和新节点之间的链接关系
ll.nodes[ll.tail].next = index
ll.nodes[index].prev = ll.tail
ll.tail = index
}
ll.stack = ll.stack[:len(ll.stack)-1] // 弹出栈顶元素
return &ll.nodes[index], true
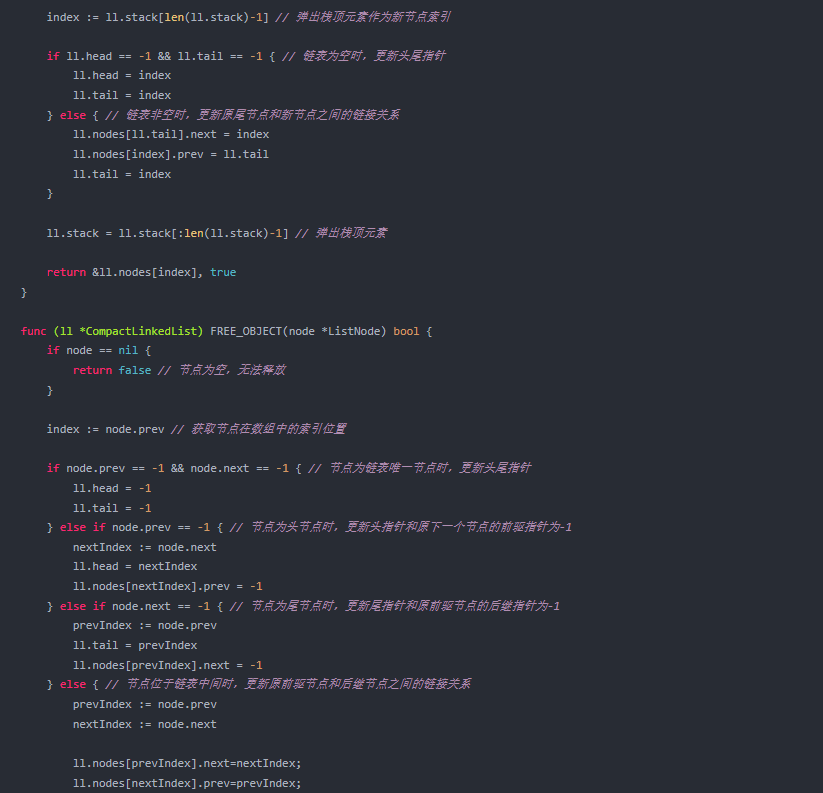
}
func (ll *CompactLinkedList) FREE_OBJECT(node *ListNode) bool {
if node == nil {
return false // 节点为空,无法释放
}
index := node.prev // 获取节点在数组中的索引位置
if node.prev == -1 && node.next == -1 { // 节点为链表唯一节点时,更新头尾指针
ll.head = -1
ll.tail = -1
} else if node.prev == -1 { // 节点为头节点时,更新头指针和原下一个节点的前驱指针为-1
nextIndex := node.next
ll.head = nextIndex
ll.nodes[nextIndex].prev = -1
} else if node.next == -1 { // 节点为尾节点时,更新尾指针和原前驱节点的后继指针为-1
prevIndex := node.prev
ll.tail = prevIndex
ll.nodes[prevIndex].next = -1
} else { // 节点位于链表中间时,更新原前驱节点和后继节点之间的链接关系
prevIndex := node.prev
nextIndex := node.next
ll.nodes[prevIndex].next=nextIndex;
ll.nodes[nextIndex].prev=prevIndex;
}
ll.stack = append(ll.stack, index) // 将释放的节点索引入栈
return true
}
以上是一个基于栈的数组实现的紧凑双向链表。通过ALLOCATE_OBJECT方法可以分配新节点,FREE_OBJECT方法可以释放节点。该实现将所有元素存储在紧凑的连续内存中,并使用栈来管理空闲节点。

文心一言 VS 讯飞星火 VS chatgpt (119)-- 算法导论10.3 4题的更多相关文章
- 【对比】文心一言对飚ChatGPT实操对比体验
前言 缘由 百度[文心一言]体验申请通过 本狗中午干饭时,天降短信,告知可以体验文心一言,苦等一个月的实操终于到来.心中这好奇的对比心理油然而生,到底是老美的[ChatGPT]厉害,还是咱度娘的[文心 ...
- 【个人首测】百度文心一言 VS ChatGPT GPT-4
昨天我写了一篇文章GPT-4牛是牛,但这几天先别急,文中我测试了用GPT-4回答ChatGPT 3.5 和 Notion AI的问题,大家期待的图片输入也没有出现. 昨天下午百度发布了文心一言,对标C ...
- 文心一言,通营销之学,成一家之言,百度人工智能AI大数据模型文心一言Python3.10接入
"文心"取自<文心雕龙>一书的开篇,作者刘勰在书中引述了一个古代典故:春秋时期,鲁国有一位名叫孔文子的大夫,他在学问上非常有造诣,但是他的儿子却不学无术,孔文子非常痛心 ...
- 获取了文心一言的内测及与其ChatGPT、GPT-4 对比结果
百度在3月16日召开了关于文心一言(知识增强大语言模型)的发布会,但是会上并没现场展示demo.如果要测试的文心一言 也要获取邀请码,才能进行测试的. 我这边通过预约得到了邀请码,大概是在3月17日晚 ...
- 百度生成式AI产品文心一言邀你体验AI创作新奇迹:百度CEO李彦宏详细透露三大产业将会带来机遇(文末附文心一言个人用户体验测试邀请码获取方法,亲测有效)
目录 中国版ChatGPT上线发布 强大中文理解能力 智能文学创作.商业文案创作 图片.视频智能生成 中国生成式AI三大产业机会 新型云计算公司 行业模型精调公司 应用服务提供商 总结 获取文心一言邀 ...
- 阿里版ChatGPT:通义千问pk文心一言
随着 ChatGPT 热潮卷起来,百度发布了文心一言.Google 发布了 Bard,「阿里云」官方终于也宣布了,旗下的 AI 大模型"通义千问"正式开启测试! 申请地址:http ...
- 基于讯飞语音API应用开发之——离线词典构建
最近实习在做一个跟语音相关的项目,就在度娘上搜索了很多关于语音的API,顺藤摸瓜找到了科大讯飞,虽然度娘自家也有语音识别.语义理解这块,但感觉应该不是很好用,毕竟之前用过百度地图的API,有问题也找不 ...
- android用讯飞实现TTS语音合成 实现中文版
Android系统从1.6版本开始就支持TTS(Text-To-Speech),即语音合成.但是android系统默认的TTS引擎:Pic TTS不支持中文.所以我们得安装自己的TTS引擎和语音包. ...
- android讯飞语音开发常遇到的问题
场景:android项目中共使用了3个语音组件:在线语音听写.离线语音合成.离线语音识别 11208:遇到这个错误,授权应用失败,先检查装机量(3台测试权限),以及appid的申请时间(35天期限), ...
- 初探机器学习之使用讯飞TTS服务实现在线语音合成
最近在调研使用各个云平台提供的AI服务,有个语音合成的需求因此就使用了一下科大讯飞的TTS服务,也用.NET Core写了一个小示例,下面就是这个小示例及其相关背景知识的介绍. 一.什么是语音合成(T ...
随机推荐
- GGTalk 开源即时通讯系统源码剖析之:数据库设计
自从<开源即时通讯GGTalk 8.0发布,增加Linux客户端,支持在统信UOS.银河麒麟上运行!>一文在博客园发布后,有园友联系我QQ,说能不能整理个更系统更详细地介绍GGTalk源码 ...
- .NET表达式树
IQueryable/IQueryable 和表达式树 IQueryable有两个组件 Expression:当前查询的组件的与语言和数据源无关的表示形式,以表达式树的形式表示. Provider:L ...
- Chrome浏览器,有道云笔记的网页剪报需要多次登录且收藏失败报错
报错代码 {"canTryAgain":false,"scope":"SECURITY","error":"2 ...
- jdbc-plus是一款基于JdbcTemplate增强工具包,基于JdbcTemplate已实现分页、多租户、动态表名等插件,可与mybatis、mybatis-plus等混合使用
jdbc-plus简介 jdbc-plus是一款基于JdbcTemplate增强工具包,基于JdbcTemplate已实现分页.多租户.动态表名等插件,可与mybatis.mybatis-plus等混 ...
- 玩转 PI 系列-如何在 Rockchip Arm 开发板上安装 Docker Tailscale K3s Cilium?
概述 618 买了几个便宜的 Purple PI OH 开发板 (500 块多一点买了 3 个), 这个开发板类似树莓派,是基于 Rockchip(瑞芯微) 的 rx3566 arm64 芯片.如下: ...
- Anaconda 使用时,conda activate 失败
今天使用一台电脑上新安装的 anaconda 时,运行 conda activate, 出现如下报错: 错误提示中,说要把 . C:\ProgramData\Anaconda3\etc\profile ...
- KVM 虚拟机 热插拔硬盘
新建硬盘 lvm 命令 lvcreate -L 200G -n lv02 ssd01 qemu-img 命令 qemu-img create -f raw test1G.raw 1G dd 命令 dd ...
- Go中 net/http 使用
转载请注明出处: net/http是Go语言标准库中的一个包,提供了实现HTTP客户端和服务器的功能.它使得编写基于HTTP协议的Web应用程序变得简单和方便. net/http包的主要用途包括: 实 ...
- AcWing 第 92 场周赛 C题 4866. 最大数量 题解
原题链接 链表 + 并查集乱搞做法: 思路 首先可以发现,想要让度数尽量大,那我们应该构造成菊花图,即下图所示: 对于每个需求,我们可以知道,如果之前他们没有连在一起,那我们一定得把他们连在一起,该过 ...
- [kubernetes]二进制部署k8s集群
0. 前言 采用二进制部署三主三工作节点的k8s集群,工作节点和Master节点共用服务器,因此只用到了三台服务器.master采用haproxy + keepalive实现高可用.实际生产环境中,建 ...