parquet列存储本身自带压缩 配合snappy或者lzo等可以进行二次压缩
上传txt文件到hdfs,txt文件大小是74左右。
这里提醒一下,是不是说parquet加lzo可以把数据压缩到这个地步,因为我的测试数据存在大量重复。所以下面使用parquet和lzo的压缩效果特别好。

创建hive表,使用parquet格式存储数据
不可以将txt数据直接加载到parquet的表里面,需要创建临时的txt存储格式的表
CREATE TABLE emp_txt (
empno int,
ename string,
job string,
mgr int,
hiredate DATE,
sal int,
comm int,
deptno int
)
partitioned BY(dt string,hour string)
row format delimited fields terminated by ",";
然后在创建parquet的表
CREATE TABLE emp_parquet (
empno int,
ename string,
job string,
mgr int,
hiredate DATE,
sal int,
comm int,
deptno int
)
partitioned BY(dt string,hour string)
row format delimited fields terminated by ","
stored as PARQUET;
加载数据
# 先将数据加载到emp_txt
load data inpath '/test/data' overwrite into table emp_txt partition(dt='2020-01-01',hour='01');
#再从emp_txt将数据加载到emp_parquet里面
insert overwrite table emp_parquet
select empno,ename,job,mgr,hiredate,sal,comm,deptno
from emp_txt where dt='2020-01-01' AND hour='01';
可以看到这里生成了两个文件,加起来5.52M,可见大大的将原始的txt进行了压缩

下面我们使用parquet加lzo的方式,来看看数据的压缩情况
CREATE TABLE emp_parquet_lzo (
empno int,
ename string,
job string,
mgr int,
hiredate DATE,
sal int,
comm int,
deptno int
)
partitioned by (dt string,hour string)
row format delimited fields terminated by ","
stored as PARQUET
tblproperties('parquet.compression'='lzo');
加载数据到emp_parquet_lzo
insert overwrite table emp_parquet_lzo partition (dt='2020-01-01',hour='01')
select empno,ename,job,mgr,hiredate,sal,comm,deptno
from emp_txt where dt='2020-01-01' AND hour='01';
数据相比较于仅仅使用parquet,数据被进一步的压缩了。但是这里提醒一下,是不是说pzrquet加lzo可以把数据压缩到这个地步,因为我的测试数据存在大量重复。

综上总结
txt文本文件,在使用parquet加压缩格式,相比较于仅仅使用parquet,可以更进一步的将数据压缩。
拓展
1.parquet压缩格式
parquet格式支持有四种压缩,分别是lzo,gzip,snappy,uncompressed,在数据量不大的情况下,四种压缩的区别也不是太大。
2.hive的分区是支持层级分区
也就是分区下面还可以有分区的,如上面的 partitioned by (dt string,hour string) 在插入数据的时候使用逗号分隔,partition(dt='2020-01-01',hour='01')
3.本次测试中,一个74M的文件,使用在insert overwrite ... select 之后,为什么会产生两个文件
首先要声明一下,我的hive使用的执行引擎是tez,替换了默认的mapreduce执行引擎。
我们看一下执行页面,这里可以看到形成了两个map,这里是map-only,一般数据的加载操作都是map-only的,所以,有多少的map,就会产生几个文件。
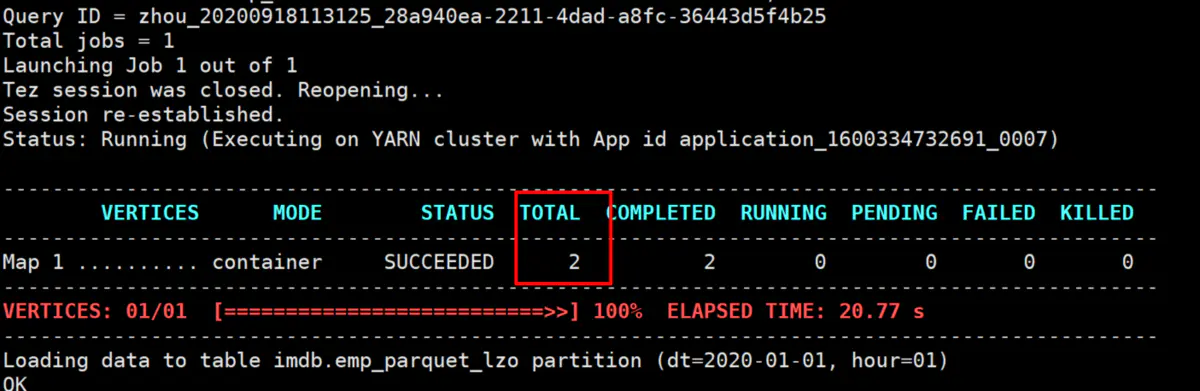
从图片可以看出,这里是tez把74M的文件分成了两个,这里的52428800是50M,也就是这里的splitsize不是hadoop的mr的默认的128M,而是这里的50M,所以,74M的文件会被分为两个,一个是50M,一个是24M,.然后我们看上面的emp_parquet的文件,一个式3.7M,也是1.8M,正好和50M和24M的比例是对应的。
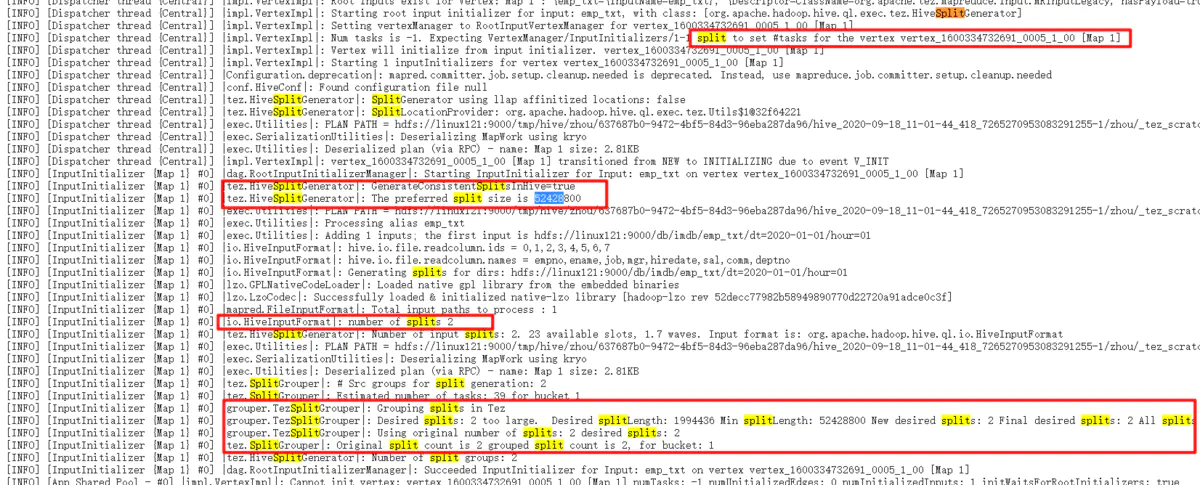
所以,一切事情都是有原因的,这里的splitsize是50M,才会导致形成两个文件的。但是我没有找到这哥tez的splitsize的具体配置是什么,以后找到的话,再进行补充。
parquet列存储本身自带压缩 配合snappy或者lzo等可以进行二次压缩的更多相关文章
- 万亿级日志与行为数据存储查询技术剖析——Hbase系预聚合方案、Dremel系parquet列存储、预聚合系、Lucene系
转自:http://www.infoq.com/cn/articles/trillion-log-and-data-storage-query-techniques?utm_source=infoq& ...
- 【转】深入分析 Parquet 列式存储格式
Parquet 是面向分析型业务的列式存储格式,由 Twitter 和 Cloudera 合作开发,2015 年 5 月从 Apache 的孵化器里毕业成为 Apache 顶级项目,最新的版本是 1. ...
- 深入分析Parquet列式存储格式【转】
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,最新的版本是1.8.0. 列式存储 列式存 ...
- Parquet列式存储格式
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,最新的版本是1.8.0. 列式存储 列式存 ...
- 深入分析Parquet列式存储格式
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,最新的版本是1.8.0. 列式存储 列式存 ...
- 从NSM到Parquet:存储结构的衍化
http://blog.csdn.net/dc_726/article/details/41777661 为了优化MapReduce及MR之前的各种工具的性能,在Hadoop内建的数据存储格式外,又涌 ...
- Vertica: 基于DBMS架构的列存储数据仓库
介绍 Vertica(属于HP公司),是一个基于DBMS架构的数据库系统,适合读密集的分析型数据库应用,比方数据仓库,白皮书中全名称为VerticaAnalytic Database.从命名中也可以看 ...
- SQL Server 2014新特性探秘(3)-可更新列存储聚集索引
简介 列存储索引其实在在SQL Server 2012中就已经存在,但SQL Server 2012中只允许建立非聚集列索引,这意味着列索引是在原有的行存储索引之上的引用了底层的数据,因此会 ...
- Druid(准)实时分析统计数据库——列存储+高效压缩
Druid是一个开源的.分布式的.列存储系统,特别适用于大数据上的(准)实时分析统计.且具有较好的稳定性(Highly Available). 其相对比较轻量级,文档非常完善,也比较容易上手. Dru ...
随机推荐
- 集合框架-LinkedList集合(有序不唯一)
1 package cn.itcast.p2.linkedlist.demo; 2 3 import java.util.Iterator; 4 import java.util.LinkedList ...
- Allure测试报告完整学习笔记
目录 简介 安装Allure Allure测试报告的结构 Java TestNG集成Allure Report Python Pytest集成Allure Report 简介 假如你想让测试报告变得漂 ...
- TensorFlow 入门 | iBooker·ApacheCN
原文:Getting Started with TensorFlow 协议:CC BY-NC-SA 4.0 自豪地采用谷歌翻译 不要担心自己的形象,只关心如何实现目标.--<原则>,生活原 ...
- 最近公共祖先-LCA
题目描述 时间限制:1.2s 内存限制:256.0MB 问题描述 如题,给定一棵有根多叉树,请求出指定两个点直接最近的公共祖先. 输入格式 第一行包含三个正整数\(N\),\(M\),\(S\),分别 ...
- AT2645 [ARC076D] Exhausted?
解法一 引理:令一个二分图两部分别为 \(X, Y(|X| \le |Y|)\),若其存在完美匹配当且仅当 \(\forall S \subseteq X, f(S) \ge |S|\)(其中 \(f ...
- 一个label 混搭不同颜色,不同字体的文字.. by 徐
效果如图箭头所示,只需要一个label就可以做到不同颜色或不同字体的效果 1 UILabel *label = [[UILabel alloc]initWithFrame:CGRectMake(10, ...
- MySQL 数据库的tab 补全功能 (懒人必备)
MySQL 数据库的tab补全功能 跟着步骤走~~ 懒人养成第一步 不仅帮你补全 甚至预判你的预判,就问你可怕不可怕 1.安装相关依赖软件(需要配置yum官方 ...
- 配置docker的DNS
方式一:在宿主机的 /etc/docker/daemon.json 文件中增加以下内容来设置全部容器的 DNS: { "dns" : [ "114.114.114.114 ...
- notepad++颜色属性解释
Global Styles Indent guideline style 缩进参考线的颜色Brace highlight style 鼠标指针在框架左右时框架的颜色(如css中{} js中的() ...
- python语法_1基础语法概述
http://www.runoob.com/python3 章节:教程.基础语法.数据类型.解释器.注释.运算符. 大纲 查看python版本 实现第一个python3.x程序,hello world ...