hive学习笔记之九:基础UDF
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
《hive学习笔记》系列导航
本篇概览
- 本文是《hive学习笔记》的第九篇,前面学习的内置函数尽管已经很丰富,但未必能满足各种场景下的个性化需求,此时可以开发用户自定义函数(User Defined Function,UDF),按照个性化需求自行扩展;
- 本篇内容就是开发一个UDF,名为udf_upper,功能是将字符串字段转为全大写,然后在hive中使用这个UDF,效果如下图红框所示:
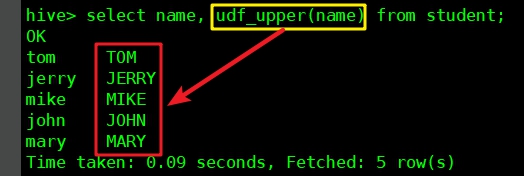
- 本篇有以下章节:
- 开发
- 部署和验证(临时函数)
- 部署和验证(永久函数)
源码下载
- 如果您不想编码,可以在GitHub下载所有源码,地址和链接信息如下表所示:
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
- 这个git项目中有多个文件夹,本章的应用在hiveudf文件夹下,如下图红框所示:
开发
- 新建名为hiveudf的maven工程,pom.xml内容如下,有两处需要关注的地方,接下来马上讲到:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.bolingcavalry</groupId>
<artifactId>hiveudf</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.2</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>pentaho-aggdesigner-algorithm</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.7</version>
<scope>provided</scope>
</dependency>
</dependencies>
</project>
- 上述pom.xml中,两个依赖的scope为provided,因为这个maven工程最终只需要将咱们写的java文件构建成jar,所以依赖的库都不需要;
- 上述pom.xml中排除了pentaho-aggdesigner-algorithm,是因为从maven仓库下载不到这个库,为了能快速编译我的java代码,这种排除的方式是最简单的,毕竟我用不上(另一种方法是手动下载此jar,再用maven install命令部署在本地);
- 创建Upper.java,代码如下非常简单,只需存在名为evaluate的public方法即可:
package com.bolingcavalry.hiveudf.udf;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hive.ql.exec.UDF;
public class Upper extends UDF {
/**
* 如果入参是合法字符串,就转为小写返回
* @param str
* @return
*/
public String evaluate(String str) {
return StringUtils.isBlank(str) ? str : str.toUpperCase();
}
}
- 编码已完成,执行mvn clean package -U编译构建,在target目录下得到hiveudf-1.0-SNAPSHOT.jar文件;
- 接下来将咱们做好的UDF部署在hive,验证功能是否正常;
部署和验证(临时函数)
- 如果希望UDF只在本次hive会话中生效,可以部署为临时函数,下面是具体的步骤;
- 将刚才创建的hiveudf-1.0-SNAPSHOT.jar文件下载到hive服务器,我这边路径是/home/hadoop/udf/hiveudf-1.0-SNAPSHOT.jar;
- 开启hive会话,执行以下命令添加jar:
add jar /home/hadoop/udf/hiveudf-1.0-SNAPSHOT.jar;
- 执行以下命令创建名为udf_upper的临时函数:
create temporary function udf_upper as 'com.bolingcavalry.hiveudf.udf.Upper';
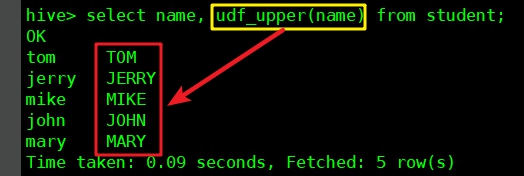
- 找一个有数据并且有string字段的表(我这是student表,其name字段是string类型),执行以下命令:
select name, udf_upper(name) from student;
- 执行结果如下,红框中可见udf_upper函数将name字段转为大写:
- 这个UDF只在当前会话窗口生效,当您关闭了窗口此函数就不存在了;
- 如果您想在当前窗口将这个UDF清理掉,请依次执行以下两个命令:
drop temporary function if exists udf_upper;
delete jar /home/hadoop/udf/hiveudf-1.0-SNAPSHOT.jar;
- 删除后再使用udf_upper会报错:
hive> select name, udf_upper(name) from student;
FAILED: SemanticException [Error 10011]: Line 1:13 Invalid function 'udf_upper'
部署和验证(永久函数)
- 前面体验了临时函数,接下来试试如何让这个UDF永久生效(并且对所有hive会话都生效);
- 在hdfs创建文件夹:
/home/hadoop/hadoop-2.7.7/bin/hadoop fs -mkdir /udflib
- 将jar文件上传到hdfs:
/home/hadoop/hadoop-2.7.7/bin/hadoop fs -put /home/hadoop/udf/hiveudf-1.0-SNAPSHOT.jar /udflib/
- 在hive会话窗口执行以下命令,使用hdfs中的jar文件创建函数,要注意的是jar文件地址是hdfs地址,一定不要漏掉hdfs:前缀:
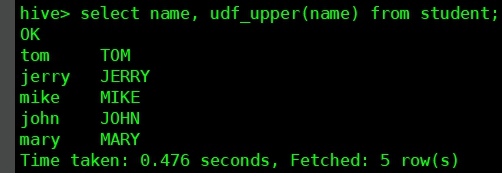
create function udf_upper as 'com.bolingcavalry.hiveudf.udf.Upper'
using jar 'hdfs:///udflib/hiveudf-1.0-SNAPSHOT.jar';
- 试一下这个UDF,如下图,没有问题:
6. 新开hive会话窗口尝试上述sql,依旧没有问题,证明UDF是永久生效的;
- 至此,咱们已经对hive的UDF的创建、部署、使用都有了基本了解,但是本篇的UDF太过简单,只能用在一进一出的场景,接下来的文章咱们继续学习多进一出和一进多出。
你不孤单,欣宸原创一路相伴
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
hive学习笔记之九:基础UDF的更多相关文章
- Hive学习笔记——HQL用法及UDF,Transform
Hive中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格.”\t”.”\x001″).行分隔符 (”\n”)以及读取文件数据的方法(Hive 中 ...
- hive学习笔记之六:HiveQL基础
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之一:基本数据类型
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之三:内部表和外部表
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之四:分区表
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之五:分桶
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之七:内置函数
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之十:用户自定义聚合函数(UDAF)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是<hive学习笔记>的第十 ...
- hive学习笔记之十一:UDTF
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
随机推荐
- curl: (35) SSL connect error
curl: (35) SSL connect error weixin_34212762 2018-02-23 20:16:23 230 收藏 文章标签: 运维 版权 阿里云的机器,昨晚githu ...
- 二进制部署K8S-1基本概念
二进制部署K8S-1基本概念 感谢老男孩教育王导的公开视频,文档整理自https://www.yuque.com/duduniao/k8s. 1.实验环境 1.1 虚拟机 因为在后期运行容器需要有大量 ...
- IT菜鸟之虚拟机VMware的安装
老师说过,如果想学好Linux,最好不要在实体机上安装Linux,因为学习需要经常折腾,在实体机上做实验,出现故障就要重新安装,这样绝大多数时间都会浪费在安装上. 这时我们需要一个工具,它就是虚拟机. ...
- 逗号字符的使用、字符数组与字符串数组、sizeof与strlen
(1)连接两个表达式为一个表达式 for(ux=0,uxt=1;uxt<444;ux++,uxt++) 允许通过编译:他可以给FOR循环更多的初始化值: (2)一般定义的话要区别只有 字符数组 ...
- Linux系统编程【5】——stty的学习
从文件的角度看设备 之前几篇文章介绍的编程是基于文件的.数据可以保存在文件中,也可以从文件中取出来做处理,再存回去.不仅如此,Linux操作系统还专门为这个东西建立了一套规则,就是前期介绍的" ...
- 返回给前端样式数据整合Swagger
对于前端样式整合swagger,只对接口做增强,不对接口逻辑做修改,当json样式拼接完成,我们把json转为对应的实体类即可. 前端json样式对象构造参考:https://workshops.ot ...
- Python3.6 的字典为什么会快
作者:青南链接:https://zhuanlan.zhihu.com/p/73426505来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 在Python 3.5(含)以 ...
- Jmeter- 笔记6 - 负载测试
普通场景介绍 1.线程数:并发用户数 2.Ramp-Up时间:启动时间(线程数的准备时间),在这个时间点结束时,所有用户都已运行起来 3.循环次数:每个线程数都要运行的次数.永远 和 调度器一起使用, ...
- Python+Selenium学习笔记12 - 窗口大小和滚动条
涉及到的三个方法 set_window_size() 用于设置浏览器窗口的大小 e.gset_window_size(600,600) window.scrollTo() 用于设置浏览器窗口滚动条的 ...
- win10家庭中文版CUDA+CUDNN+显卡GPU使用tensorflow-gpu训练模型安装过程(精华帖汇总+重新修改多次复现)
查看安装包 pip list 本帖提供操作过程,具体操作网上有好多了,不赘述.红色字体为后来复现出现的问题以及批注 题外话: (1)python 的环境尽量保持干净,尽量单一,否则容易把自己搞晕,不知 ...