[炼丹术]YOLOv5训练自定义数据集
YOLOv5训练自定义数据
一、开始之前的准备工作
克隆 repo 并在Python>=3.6.0环境中安装requirements.txt,包括PyTorch>=1.7。模型和数据集会从最新的 YOLOv5版本中自动下载。
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
二、训练自定义数据
2.1 创建my_dataset.yaml
COCO128是一个示例小教程数据集,由COCO train2017中的前 128 张图像组成。这些相同的 128 张图像用于训练和验证,以验证我们的训练管道是否能够过拟合。数据/ coco128.yaml,如下所示,是数据集的配置文件,它定义1)数据集根目录path和相对路径train/ val/test图像目录(或* .txt与图像文件的路径),2)的类的数量nc和3)类列表names:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir 数据集根目录
train: images/train2017 # train images (relative to 'path') 128 images #训练图像(相对于“path”)
val: images/train2017 # val images (relative to 'path') 128 images # val 图像(相对于“path”)
test: # test images (optional) #测试图像(可选)
# Classes
nc: 80 # number of classes
names: [ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush' ] # class names
这里设置数据集路径有三种方式:
- dir: path/to/imgs,
- file: path/to/imgs.txt, 或
- list: [path/to/imgs1, path/to/imgs2, .. ]
2.2 创建label标签
使用CVAT或makeense.ai等工具标记图像后,将标签导出为YOLO 格式,*.txt每个图像一个文件(如果图像中没有对象,则不需要*.txt文件)。该*.txt文件规格有:
- 每个对象一行
- 每一行都是
class x_center y_center width height格式。 - 框坐标必须采用标准化 xywh格式(从 0 - 1)。如果您的箱子以像素为单位,划分
x_center并width通过图像宽度,y_center并height通过图像高度。 - 类号是零索引的(从 0 开始)。

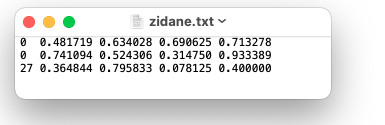
上图对应的标签文件包含2个人(class 0)和一条领带(class 27):
2.3 整理目录
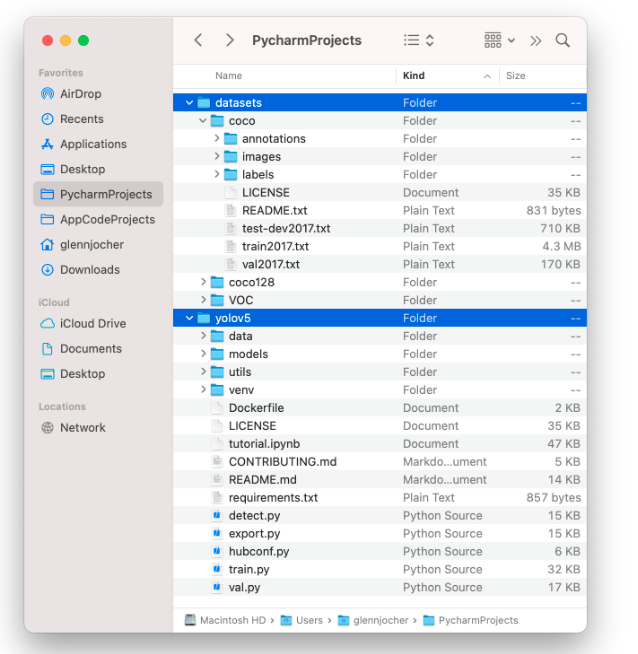
根据以下示例组织您的训练和验证图像和标签。YOLOv5 假设 /coco128在/datasets目录旁边的/yolov5目录中。YOLOv5通过将/images/每个图像路径中的最后一个实例替换为/labels/. 例如:
../datasets/coco128/images/im0.jpg #图像
../datasets/coco128/labels/im0.txt #标签
文件结构,如下图所示:
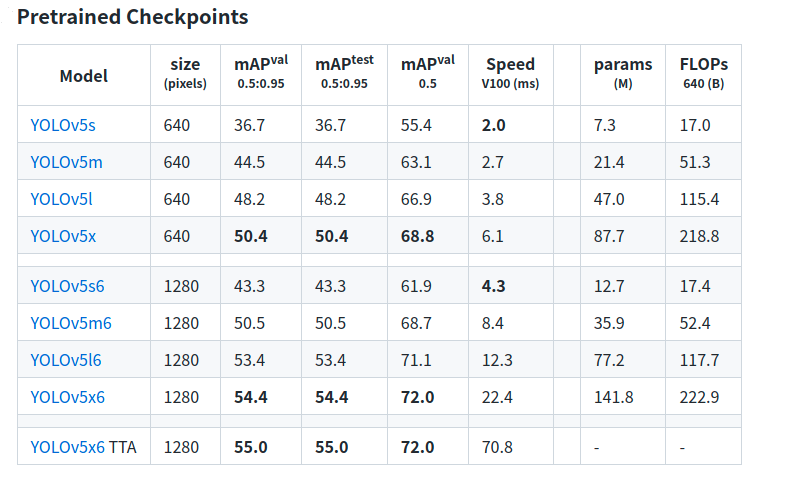
2.4 选择模型型号
选择一个预训练模型开始训练。这里我们选择YOLOv5s,这是可用的最小和最快的模型。有关所有模型的完整比较,请参阅 README表。
2.5 train训练
通过指定数据集、批量大小、图像大小以及预训练--weights yolov5s.pt(推荐)或随机初始化--weights '' --cfg yolov5s.yaml(不推荐),在 COCO128 上训练 YOLOv5s 模型。预训练权重是从最新的 YOLOv5 版本自动下载的。
# 在COCO128 上训练
YOLOv5s 3 epochs $ python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt
所有训练结果都保存在runs/train/递增的运行目录中,即runs/train/exp2,runs/train/exp3等。有关更多详细信息,请参阅我们的 Google Colab Notebook 的训练部分。
三、可视化
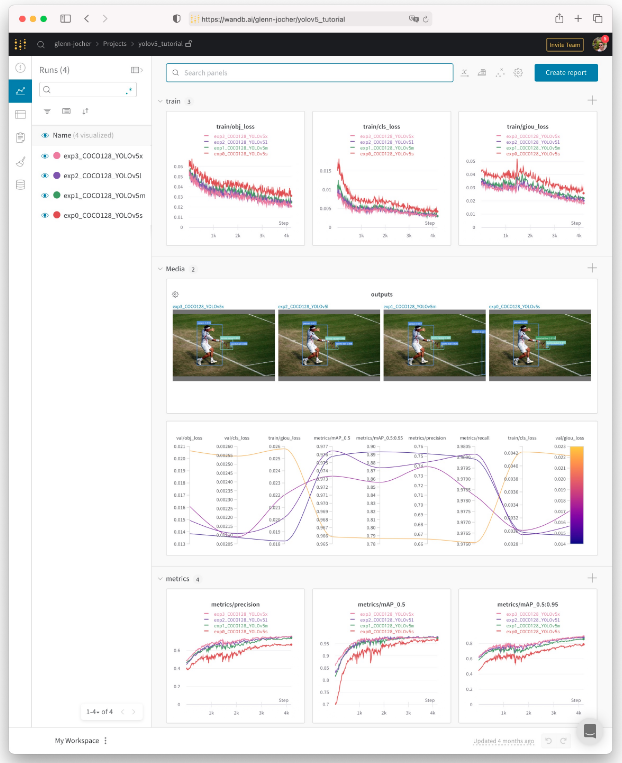
权重和偏差记录( 新)
权重和偏差(W&B) 现在与 YOLOv5 集成,用于训练运行的实时可视化和云记录。这允许更好地运行比较和内省,以及提高团队成员之间的可见性和协作。要启用 W&B 日志记录,请安装wandb,然后正常训练(首次使用时将指导您进行设置)。
pip install wandb
在训练过程期间,你将在https://wandb.ai看到实时更新,并且您可以使用 W&B 报告工具创建结果的详细报告。
四、本地日志
所有的结果都在默认情况下记录runs/train,为每个新的培训作为创建一个新的实验目录runs/train/exp2,runs/train/exp3等查看火车和Val JPG文件看马赛克,标签,预测和增强效果。请注意,使用 Ultralytics Mosaic Dataloader进行训练(如下所示),它在训练期间将 4 个图像组合成 1 个马赛克。
train_batch0.jpg 显示训练批次 0 马赛克和标签:

val_batch0_labels.jpg 显示 val 批次 0 标签:

val_batch0_pred.jpg显示 val 批次 0预测:

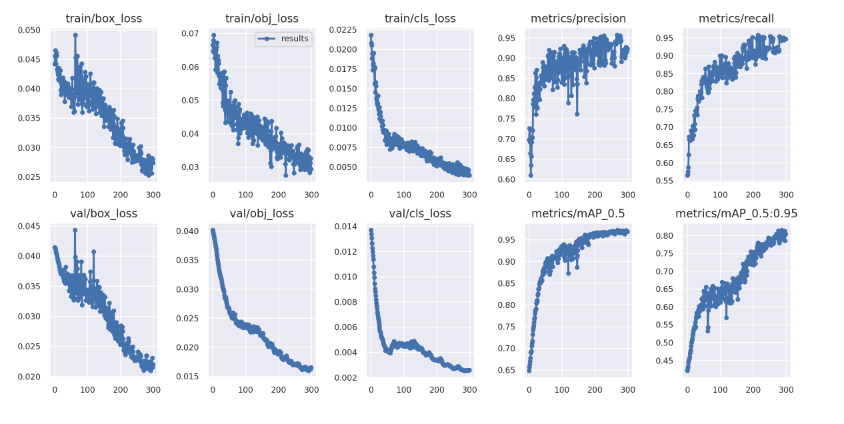
训练结果自动记录到Tensorboard和CSV中results.csv,results.png训练完成后绘制为(下图)。您还可以results.csv手动绘制任何文件:
from utils.plots import plot_results
plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'
[炼丹术]YOLOv5训练自定义数据集的更多相关文章
- yolov5训练自定义数据集
yolov5训练自定义数据 step1:参考文献及代码 博客 https://blog.csdn.net/weixin_41868104/article/details/107339535 githu ...
- Scaled-YOLOv4 快速开始,训练自定义数据集
代码: https://github.com/ikuokuo/start-scaled-yolov4 Scaled-YOLOv4 代码: https://github.com/WongKinYiu/S ...
- MMDetection 快速开始,训练自定义数据集
本文将快速引导使用 MMDetection ,记录了实践中需注意的一些问题. 环境准备 基础环境 Nvidia 显卡的主机 Ubuntu 18.04 系统安装,可见 制作 USB 启动盘,及系统安装 ...
- PyTorch 自定义数据集
准备数据 准备 COCO128 数据集,其是 COCO train2017 前 128 个数据.按 YOLOv5 组织的目录: $ tree ~/datasets/coco128 -L 2 /home ...
- torch_13_自定义数据集实战
1.将图片的路径和标签写入csv文件并实现读取 # 创建一个文件,包含image,存放方式:label pokemeon\\mew\\0001.jpg,0 def load_csv(self,file ...
- tensorflow从训练自定义CNN网络模型到Android端部署tflite
网上有很多关于tensorflow lite在安卓端部署的教程,但是大多只讲如何把训练好的模型部署到安卓端,不讲如何训练,而实际上在部署的时候,需要知道训练模型时预处理的细节,这就导致了自己训练的模型 ...
- Tensorflow2 自定义数据集图片完成图片分类任务
对于自定义数据集的图片任务,通用流程一般分为以下几个步骤: Load data Train-Val-Test Build model Transfer Learning 其中大部分精力会花在数据的准备 ...
- Yolo训练自定义目标检测
Yolo训练自定义目标检测 参考darknet:https://pjreddie.com/darknet/yolo/ 1. 下载darknet 在 https://github.com/pjreddi ...
- pytorch加载语音类自定义数据集
pytorch对一下常用的公开数据集有很方便的API接口,但是当我们需要使用自己的数据集训练神经网络时,就需要自定义数据集,在pytorch中,提供了一些类,方便我们定义自己的数据集合 torch.u ...
随机推荐
- 转 Android 多线程:手把手教你使用AsyncTask
转自:https://www.jianshu.com/p/ee1342fcf5e7 前言 多线程的应用在Android开发中是非常常见的,常用方法主要有: 继承Thread类 实现Runnable接口 ...
- vue 项目如何使用animate.css
Animate.css是一款酷炫丰富的跨浏览器动画库,它在GitHub上的star数至今已有5.3万+. 在vue项目中我们可以借助于animate.css,用十分简单的代码来实现一个个炫酷的效果!( ...
- Webpack学习篇
<深入浅出Webpack>优化篇 01 Webpack 优化可以分为开发优化和输出质量优化两部分,主要要点如下: 优化开发体验,提升开发效率 优化构建速度 优化使用体验 优化输出质量 减少 ...
- Linux提取命令grep 有这一篇就够了
grep作为linux中使用频率非常高的一个命令,和cut命令一样都是管道命令中的一员.并且其功能也是对一行数据进行分析,从分析的数据中取出我们想要的数据.也就是相当于一个检索的功能.当然了,grep ...
- C语言实现鼠标绘图
使用C语言+EGE图形库(Easy Graphics Engine).思路是通过不断绘制直线来实现鼠标绘图的功能,前一个时刻鼠标的坐标作为直线的起点,现在时刻的坐标作为终点(严格意义是线段而不是直线) ...
- Linux 文件权限、系统优化
目录 Linux 文件权限.系统优化 1.文件权限的详细操作 1.简介: 2.命令及归属: 3.权限对于用户和目录的意义 权限对于用户的意义: 权限对于目录的意义: 4.创建文件/文件夹的默认权限来源 ...
- QT QApplication干了啥?
------------恢复内容开始------------ QCoreApplicationPrivate 会取得current thread; 在windows平台创建TLS变量,记录线程信息,并 ...
- Arcpy按属性(字段值)不同将shp分割为多个独立shp_适用点线面矢量
利用代码可以进行批量处理,安装有10.5及以上版本ArcGIS可以使用工具Split by attributes完成上述任务 # -*- coding: utf-8 -*- # Import syst ...
- Python第二周 str的方法
str.start #!/usr/bin/env python # Author:Zhangmingda while True: cmd = input('输入字符:')#.strip() print ...
- 7.2 Tornado异步
7.2 Tornado异步 因为epoll主要是用来解决网络IO的并发问题,所以Tornado的异步编程也主要体现在网络IO的异步上,即异步Web请求. 1. tornado.httpclient.A ...