[炼丹术]YOLOv5训练自定义数据集
YOLOv5训练自定义数据
一、开始之前的准备工作
克隆 repo 并在Python>=3.6.0环境中安装requirements.txt,包括PyTorch>=1.7。模型和数据集会从最新的 YOLOv5版本中自动下载。
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
二、训练自定义数据
2.1 创建my_dataset.yaml
COCO128是一个示例小教程数据集,由COCO train2017中的前 128 张图像组成。这些相同的 128 张图像用于训练和验证,以验证我们的训练管道是否能够过拟合。数据/ coco128.yaml,如下所示,是数据集的配置文件,它定义1)数据集根目录path和相对路径train/ val/test图像目录(或* .txt与图像文件的路径),2)的类的数量nc和3)类列表names:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir 数据集根目录
train: images/train2017 # train images (relative to 'path') 128 images #训练图像(相对于“path”)
val: images/train2017 # val images (relative to 'path') 128 images # val 图像(相对于“path”)
test: # test images (optional) #测试图像(可选)
# Classes
nc: 80 # number of classes
names: [ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush' ] # class names
这里设置数据集路径有三种方式:
- dir: path/to/imgs,
- file: path/to/imgs.txt, 或
- list: [path/to/imgs1, path/to/imgs2, .. ]
2.2 创建label标签
使用CVAT或makeense.ai等工具标记图像后,将标签导出为YOLO 格式,*.txt每个图像一个文件(如果图像中没有对象,则不需要*.txt文件)。该*.txt文件规格有:
- 每个对象一行
- 每一行都是
class x_center y_center width height格式。 - 框坐标必须采用标准化 xywh格式(从 0 - 1)。如果您的箱子以像素为单位,划分
x_center并width通过图像宽度,y_center并height通过图像高度。 - 类号是零索引的(从 0 开始)。

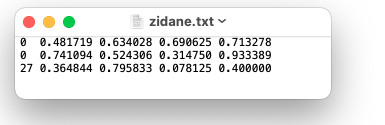
上图对应的标签文件包含2个人(class 0)和一条领带(class 27):
2.3 整理目录
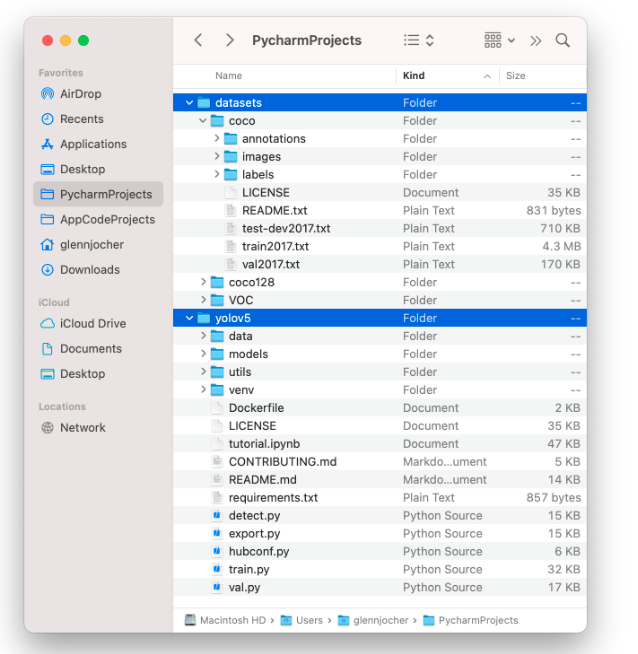
根据以下示例组织您的训练和验证图像和标签。YOLOv5 假设 /coco128在/datasets目录旁边的/yolov5目录中。YOLOv5通过将/images/每个图像路径中的最后一个实例替换为/labels/. 例如:
../datasets/coco128/images/im0.jpg #图像
../datasets/coco128/labels/im0.txt #标签
文件结构,如下图所示:
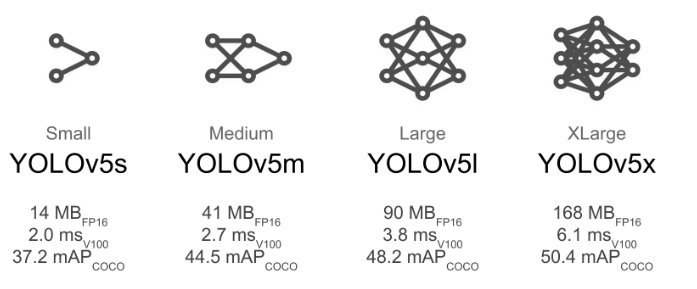
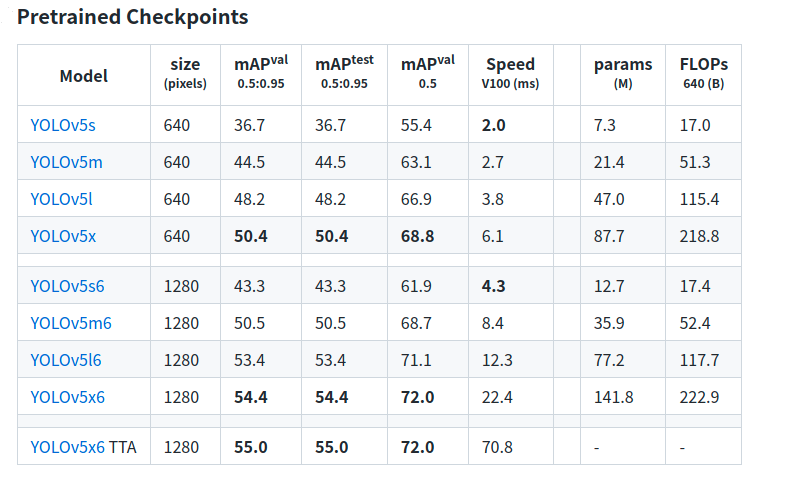
2.4 选择模型型号
选择一个预训练模型开始训练。这里我们选择YOLOv5s,这是可用的最小和最快的模型。有关所有模型的完整比较,请参阅 README表。
2.5 train训练
通过指定数据集、批量大小、图像大小以及预训练--weights yolov5s.pt(推荐)或随机初始化--weights '' --cfg yolov5s.yaml(不推荐),在 COCO128 上训练 YOLOv5s 模型。预训练权重是从最新的 YOLOv5 版本自动下载的。
# 在COCO128 上训练
YOLOv5s 3 epochs $ python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt
所有训练结果都保存在runs/train/递增的运行目录中,即runs/train/exp2,runs/train/exp3等。有关更多详细信息,请参阅我们的 Google Colab Notebook 的训练部分。
三、可视化
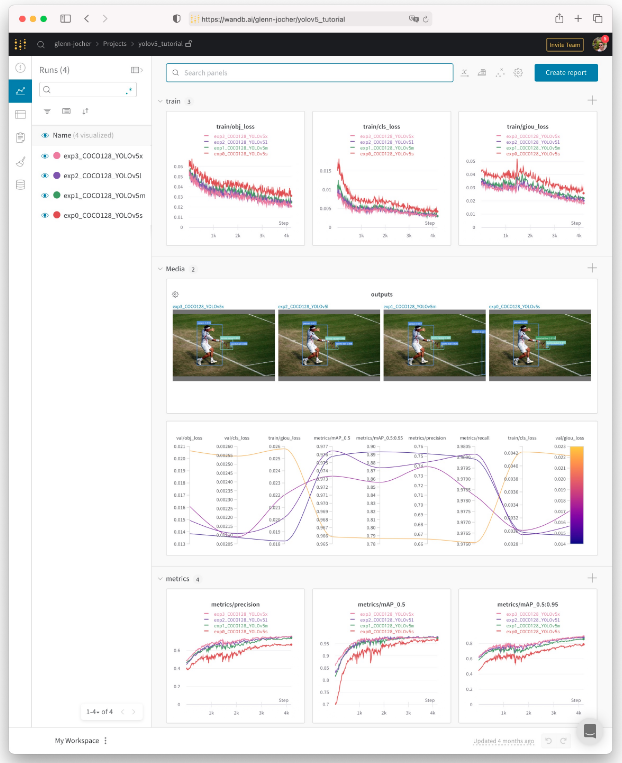
权重和偏差记录( 新)
权重和偏差(W&B) 现在与 YOLOv5 集成,用于训练运行的实时可视化和云记录。这允许更好地运行比较和内省,以及提高团队成员之间的可见性和协作。要启用 W&B 日志记录,请安装wandb,然后正常训练(首次使用时将指导您进行设置)。
pip install wandb
在训练过程期间,你将在https://wandb.ai看到实时更新,并且您可以使用 W&B 报告工具创建结果的详细报告。
四、本地日志
所有的结果都在默认情况下记录runs/train,为每个新的培训作为创建一个新的实验目录runs/train/exp2,runs/train/exp3等查看火车和Val JPG文件看马赛克,标签,预测和增强效果。请注意,使用 Ultralytics Mosaic Dataloader进行训练(如下所示),它在训练期间将 4 个图像组合成 1 个马赛克。
train_batch0.jpg 显示训练批次 0 马赛克和标签:

val_batch0_labels.jpg 显示 val 批次 0 标签:

val_batch0_pred.jpg显示 val 批次 0预测:

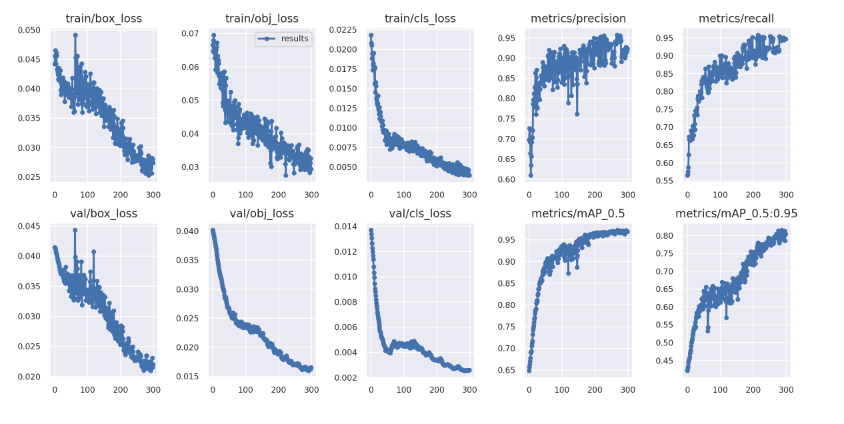
训练结果自动记录到Tensorboard和CSV中results.csv,results.png训练完成后绘制为(下图)。您还可以results.csv手动绘制任何文件:
from utils.plots import plot_results
plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'
[炼丹术]YOLOv5训练自定义数据集的更多相关文章
- yolov5训练自定义数据集
yolov5训练自定义数据 step1:参考文献及代码 博客 https://blog.csdn.net/weixin_41868104/article/details/107339535 githu ...
- Scaled-YOLOv4 快速开始,训练自定义数据集
代码: https://github.com/ikuokuo/start-scaled-yolov4 Scaled-YOLOv4 代码: https://github.com/WongKinYiu/S ...
- MMDetection 快速开始,训练自定义数据集
本文将快速引导使用 MMDetection ,记录了实践中需注意的一些问题. 环境准备 基础环境 Nvidia 显卡的主机 Ubuntu 18.04 系统安装,可见 制作 USB 启动盘,及系统安装 ...
- PyTorch 自定义数据集
准备数据 准备 COCO128 数据集,其是 COCO train2017 前 128 个数据.按 YOLOv5 组织的目录: $ tree ~/datasets/coco128 -L 2 /home ...
- torch_13_自定义数据集实战
1.将图片的路径和标签写入csv文件并实现读取 # 创建一个文件,包含image,存放方式:label pokemeon\\mew\\0001.jpg,0 def load_csv(self,file ...
- tensorflow从训练自定义CNN网络模型到Android端部署tflite
网上有很多关于tensorflow lite在安卓端部署的教程,但是大多只讲如何把训练好的模型部署到安卓端,不讲如何训练,而实际上在部署的时候,需要知道训练模型时预处理的细节,这就导致了自己训练的模型 ...
- Tensorflow2 自定义数据集图片完成图片分类任务
对于自定义数据集的图片任务,通用流程一般分为以下几个步骤: Load data Train-Val-Test Build model Transfer Learning 其中大部分精力会花在数据的准备 ...
- Yolo训练自定义目标检测
Yolo训练自定义目标检测 参考darknet:https://pjreddie.com/darknet/yolo/ 1. 下载darknet 在 https://github.com/pjreddi ...
- pytorch加载语音类自定义数据集
pytorch对一下常用的公开数据集有很方便的API接口,但是当我们需要使用自己的数据集训练神经网络时,就需要自定义数据集,在pytorch中,提供了一些类,方便我们定义自己的数据集合 torch.u ...
随机推荐
- Elasticsearch【基础入门】
目录 一.操作index 1.查看index 2.增加index 3.删除index 二.操作index 1.新增document 2.查询type 全部数据 3.查找指定 id 的 document ...
- 大数据学习day35----flume01-------1 agent(关于agent的一些问题),2 event,3 有关agent和event的一些问题,4 transaction(事务控制机制),5 flume安装 6.Flume入门案例
具体见文档,以下只是简单笔记(内容不全) 1.agent Flume中最核心的角色是agent,flume采集系统就是由一个个agent连接起来所形成的一个或简单或复杂的数据传输通道.对于每一个Age ...
- tomcat在eclipse上发布,Perference下的server找不到解决办法
help--->Install New software得到如下所示 下面work with选项的内容与你的eclipse版本有关 我的eclipse版本为eclipse-java-2019-0 ...
- javaAPI2
---------------------------------------------------------------------------------------------------- ...
- vue-cli 如何配置assetsPublicPath; vue.config.js如何更改assetsPublicPath配置;
问题: vue项目完成打包上线的时候遇到静态资源找不到的问题,网上很多解决办法都是基于vue-cli 2.x 来解决的,但从vue-cli 3.0以后,便舍弃了配置文件夹(便没有了config这个文件 ...
- 1.ElasticSearch相关概念
1.为ElasticSearch设置跨域访问 http.cors.enabled: truehttp.cors.allow-origin: "*" 2.什么是ElasticSear ...
- 30个类手写Spring核心原理之AOP代码织入(5)
本文节选自<Spring 5核心原理> 前面我们已经完成了Spring IoC.DI.MVC三大核心模块的功能,并保证了功能可用.接下来要完成Spring的另一个核心模块-AOP,这也是最 ...
- CF433B Kuriyama Mirai's Stones 题解
Content 有一个长度为 \(n\) 的数组 \(a_1,a_2,a_3,...,a_n\).有 \(m\) 次询问,询问有以下两种: \(1~l~r\),求 \(\sum\limits_{i=l ...
- lvm 扩容
总体思路: 逻辑卷要扩容,先扩容对应卷组, 扩容卷组的方式: 添加新的物理卷(磁盘已有分区,扩容后新建分区:或者新加了一块硬盘创建了新的物理卷),vgextend myvg /dev/vdb 扩容,/ ...
- logging模块学习
logging模块: https://docs.python.org/3/howto/logging.html#logging-basic-tutorial 本记录教程 日志记录是一种跟踪某些软件运行 ...