Proximal Algorithms 4 Algorithms
这一节介绍了一些利用proximal的算法.
Proximal minimization
这个相当的简单, 之前也提过,就是一个依赖不动点的迭代方法:
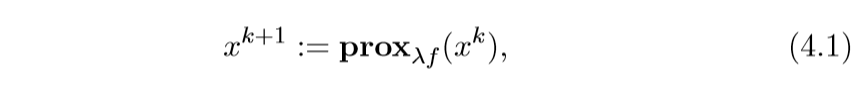
有些时候\(\lambda\)不是固定的:
\]
import numpy as np
import matplotlib.pyplot as plt
以\(f(x,y) = x^2 + 50y\)为例
f = lambda x: x[0] ** 2 + 50 * x[1] ** 2
x = np.linspace(-40, 40, 1000)
y = np.linspace(-20, 20, 500)
X, Y = np.meshgrid(x, y) #获取坐标
fig, ax = plt.subplots()
ax.contour(X, Y, f([X, Y]), colors="black")
plt.show()

求解proximal可得:
y = \frac{v_2}{100\lambda + 1}
\]
def prox(v1, v2, lam):
x = v1 / (2 * lam + 1)
y = v2 / (100 * lam + 1)
return x, y
times = 50
x = 30
y = 15
lam = 0.1
process = [(x, y)]
for i in range(times):
x, y = prox(x, y, 0.1)
process.append((x, y))
process = np.array(process)
x = np.linspace(-40, 40, 1000)
y = np.linspace(-20, 20, 500)
X, Y = np.meshgrid(x, y) #获取坐标
fig, ax = plt.subplots()
ax.contour(X, Y, f([X, Y]), colors="black")
ax.scatter(process[:, 0], process[:, 1])
ax.plot(process[:, 0], process[:, 1])
plt.show()

解释
除了之前已经提到过的一些解释:
Gradient flow
考虑下面的微分方程:
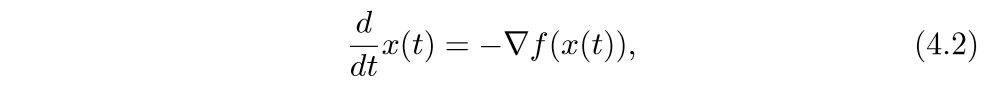
\(t \rightarrow \infty\)时\(f(x(t))\rightarrow p^*\),其中\(p^*\)是最小值.
我们来看其离散的情形:
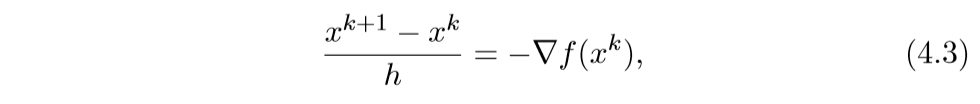
于是就有:
\]
还有一种后退的形式:
\]
此时,为了找到\(x^{k+1}\), 我们需要求解一个方程:
\Rightarrow x^{k+1} = (I+ h \nabla f)^{-1}x^k = \mathbf{prox}_{hf}(x^k)
\]
还有一种特殊的解释,这里不提了.
\(f(x) + g(x)\)
考虑下面的问题:
\]
其中\(f\)是可微的.
我们可以通过下列proximal gradient method来求解:
\]
可以证明(虽然我不会),当\(\nabla f\) Lipschitz连续,常数为\(L\),那么,如果\(\lambda^k = \lambda \in (0, 1/L]\),这个方法会以\(O(1/k)\)的速度收敛.
还有一些直线搜素算法:

一般取\(\beta=1/2\),\(\widehat{f}_{\lambda}\)是\(f\)的一个上界,在后面的解释中在具体探讨.
解释1 最大最小算法
最大最小算法, 最小化函数\(\varphi: \mathbb{R}^n \rightarrow \mathbb{R}\):
\]
其中\(\widehat{\varphi}(\cdot, x^k)\)是\(\varphi\)的凸上界:\(\widehat{\varphi}(x, x^k) \ge \varphi(x)\), \(\widehat{\varphi}(x, x)=\varphi(x)\).
我们可以这么构造一个上界:
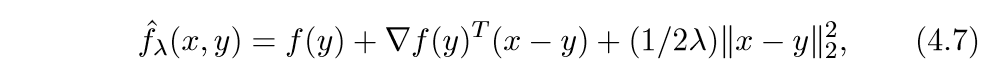
上面的式子很像泰勒二阶展开,首先这个函数符合第二个条件,下面我们证明,当\(\lambda \in (0, 1/L]\),那么它也符合第一个条件.
\]
其中\(z = x + \theta (y-x), \theta \in [0, 1]\), 又Lipschitz连续,所以:
\]
考虑\(f(x+t\Delta x)\)关于\(t\)的二阶泰勒展式:
\]
令\(t=1\):
\]
\]
由当\(t \rightarrow 0\)时,左边为\(\|\nabla^2 f(x) \Delta x\|\), 所以\(\nabla^2 f(x)\)的最大特征值必小于\(L\), 所以:
\]
完蛋,好像只能证明在局部成立,能证明在全局成立吗?
\]
再令:
\]
那么:
\]
上面的等式,可以利用第二节中的性质推出.
不动点解释
最小化\(f(x)+g(x)\)的点\(x^*\)应当满足:
\]
更一般地:

这便说明了一种迭代方式.
Forward-backward 迭代解释
考虑下列微分方程系统:
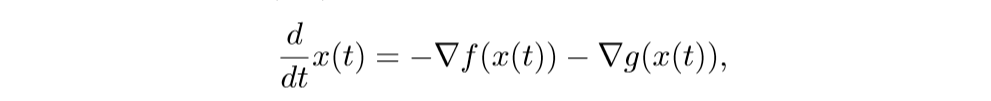
离散化后得:
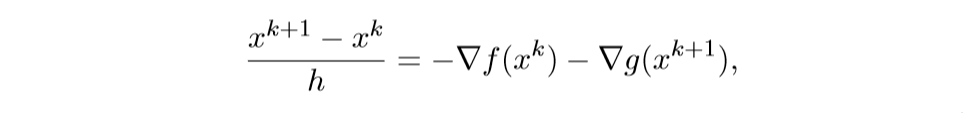
注意,等式右边\(x^k\)和\(x^{k+1}\),这正是巧妙之处.
解此方程可得:
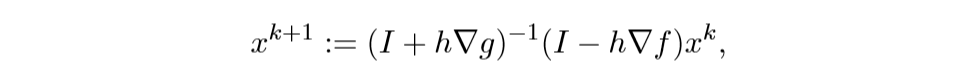
这就是之前的那个迭代方法.
加速 proximal gradient method
其迭代方式为:
x^{k+1} := \mathbf{prox}_{\lambda^k g}(y^{k+1}-\lambda^k \nabla f(y^{k+1}))
\]
\(w^k \in [0,1)\)
这个方法有点类似Momentum的感觉.
一个选择是:
\]
也有类似的直线搜索算法:

交替方向方法 ADMM
alternating direction method of multipliers (ADMM), 怎么说呢,久闻大名,不过还没看过类似的文章.
同样是考虑这个问题:
\]
但是呢,这时\(f,g\)都不一定是可微的, ADMM采取的策略是:
z^{k+1} := \mathbf{prox}_{\lambda g} (x^{k+1} + u^k)\\
u^{k+1} := u^k + x^{k+1} -z^{k+1}
\]
特殊的情况是, \(f\)或\(g\)是指示函数,不妨设\(f\)是闭凸集\(\mathcal{C}\)的指示函数,而\(g\)是闭凸集\(\mathcal{D}\)的指示函数, 即:
\]
这个时候,更新公式变为:
z^{k+1} := \Pi_{\mathcal{C}} (x^{k+1} + u^k) \\
u^{k+1} := u^k + x^{k+1} -z^{k+1}
\]
解释1 自动控制
可以这么理解,\(z\)为状态,而\(u\)为控制,前俩步时离散时间动态系统(不懂啊...), 第三步的目标是选择\(u\)使得\(x=z\),所以\(x^{k+1}-z^{k+1}\)可以认为是一个信号误差,所以第三步就会把这些误差累计起来.
解释2 Augmented Largranians
我们可以将问题转化为:
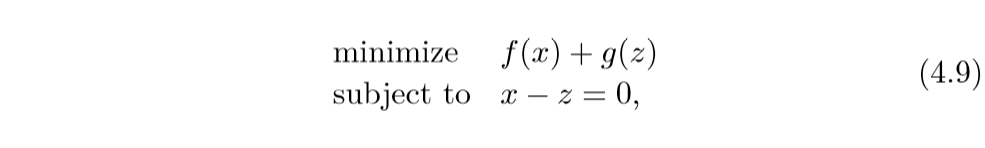
augmented Largranian:
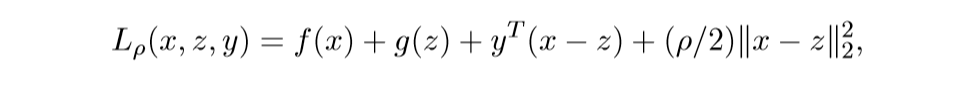
其中\(y\)为对偶变量.
在\(z, y\)已知的条件下,最小化\(L\), 即:
\]
在\(x, y\)已知的条件下,最小化\(L\), 即:
\]
最后一步:
\]
如果依照对偶问题的知识,关于\(y\)应该是取最大,但是呢,关于\(y\)是一个仿射函数,所以没有最值,所以就简单地取那个?
注意到:


让\(u^k = (1/\rho)y^k\), \(\lambda = 1/\rho\)就是最开始的结果.
解释3 Flow interpretation
问题(4.9)的最优条件(KKT条件):
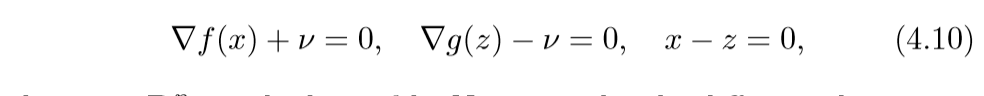
其中\(v\)是对偶变量.考虑微分方程:
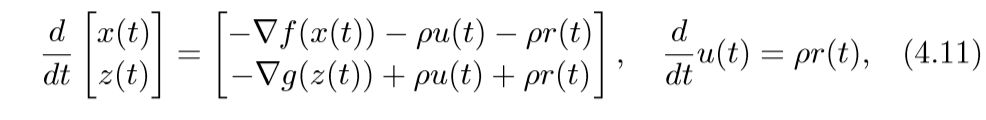
(4.11)取得稳定点的条件即为(4.10)(\(v=\rho)\)(这部分没怎么弄明白).
离散化情形为:

取\(h = \lambda, \rho = 1/\lambda\)即可得ADMM.
解释4 不动点
原问题的最优条件为:
\]
ADMM的不动点满足:
\]
从最后一个等式,我们可以知道:
\]
, 于是
\]
等价于:
\]
等价于:
\]
俩个式子相加,说明\(x\)即为最优解.
再来说明一下,为什么可以相加,根据次梯度的定义:
\lambda g(z) \ge \lambda g(x) + (+u)^T(z-x), \quad \forall z\in \mathbf{dom}g \\
\]
相加可得:
\]
需要注意的是,我证明的时候也困扰了,
\]
并不是指(x-u)是函数\(x^2/2 + \lambda f(x)\)的次梯度, 而是\(x-u\)在\(\lambda f(x)\)的次梯度集合加上\(x\)的集合内,也就是\(-u\)是其次梯度.
对不起!又想当然了,其实没问题, 如果
\]
而\(\partial f_2(x)=h(x)\)则:
\]
证:
已知:
f_2(z) \ge f_2(x)+h(x)^T(z-x) \\
\]
俩式相加可得:
\]
所以\(g \in \partial (f_1+f_2)(x)\), 注意\(g=g(x)\)也是无妨的.
特别的情况 \(f(x) + g(Ax)\)
考虑下面的问题:
\]
上面的求解,也可以让\(\widetilde{g}(x) = g(Ax)\),这样子就可以用普通的ADMM来求解了, 但是有更加简便的方法.
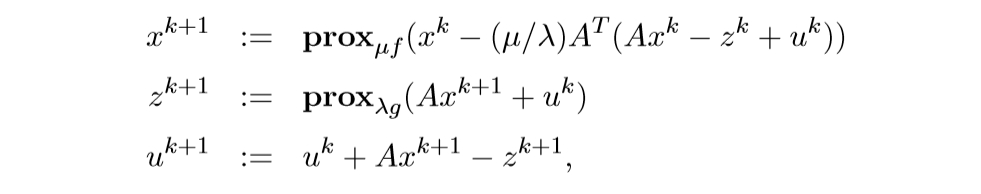
这个的来源为:

再利用和之前一样的推导,不过,我要存疑的一点是最后的替代,我觉得应该是:
\]
否则推不出来啊.
Proximal Algorithms 4 Algorithms的更多相关文章
- [Algorithms] Sorting Algorithms (Insertion Sort, Bubble Sort, Merge Sort and Quicksort)
Recently I systematicall review some sorting algorithms, including insertion sort, bubble sort, merg ...
- Matrix Factorization, Algorithms, Applications, and Avaliable packages
矩阵分解 来源:http://www.cvchina.info/2011/09/05/matrix-factorization-jungle/ 美帝的有心人士收集了市面上的矩阵分解的差点儿全部算法和应 ...
- [zt]Which are the 10 algorithms every computer science student must implement at least once in life?
More important than algorithms(just problems #$!%), the techniques/concepts residing at the base of ...
- Awesome Algorithms
Awesome Algorithms A curated list of awesome places to learn and/or practice algorithms. Inspired by ...
- 海量数据挖掘MMDS week3:流算法Stream Algorithms
http://blog.csdn.net/pipisorry/article/details/49183379 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 基音检测算法的性能:Performance Evaluation of Pitch Detection Algorithms
http://access.feld.cvut.cz/view.php?cisloclanku=2009060001 Vydáno dne 02. 06. 2009 (15123 přečtení) ...
- 机器学习算法之旅A Tour of Machine Learning Algorithms
In this post we take a tour of the most popular machine learning algorithms. It is useful to tour th ...
- 深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)
深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO) 2018-07-17 16:54:51 Reference: https://b ...
- Proximal Algorithms
1. Introduction Much like Newton's method is a standard tool for solving unconstrained smooth minimi ...
随机推荐
- 《Scala编程》课程作业
第一题.百元喝酒 作业要求:每瓶啤酒2元,3个空酒瓶或者5个瓶盖可换1瓶啤酒.100元最多可喝多少瓶啤酒?(不允许借啤酒) 思路:利用递归算法,一次性买完,然后递归算出瓶盖和空瓶能换的啤酒数 /** ...
- Servlet(2):通过servletContext对象实现数据共享
一,ServletContext介绍 web容器在启动时,它会为每一个web应用程序都创建一个ServletContext对象,它代表当前web应用 多个Servlet通过ServletContext ...
- SpringBoot的定时任务
springBoot定时任务可分为多线程和单线程,而单线程又分为注解形式,接口形式 1.基于注解形式 基于注解@Scheduled默认为单线程,开启多个任务时,任务的执行时机会受上一个任务执行时间的影 ...
- Springboot,SSM及SSH的概念、优点、区别及缺点
Springboot的概念: 是提供的全新框架,使用来简化Spring的初始搭建和开发过程,使用了特定的方式来进行配置,让开发人员不在需要定义样板化的配置.此框架不需要配置xml,依赖于像MAVEN这 ...
- Leetcode 78题-子集
LeetCode 78 网上已经又很多解这题的博客了,在这只是我自己的解题思路和自己的代码: 先贴上原题: 我的思路: 我做题的喜欢在本子或别处做写几个示例,以此来总结规律:下图就是我从空数组到数组长 ...
- 【C/C++】贪心/算法笔记4.4/PAT B1020月饼/PAT B1023组内最小数
简单贪心 所谓简单贪心,就是每步都取最优的一种方法. 月饼问题:有N种月饼,市场最大需求量D,给出每种月饼的库存量和总售价. 思路:从贵的往便宜的卖.如果当前的已经卖完了,就卖下一个.如果剩余D不足, ...
- [云原生]Docker - 容器
目录 Docker容器 启动容器 新建并启动 启动已终止容器 守护态运行容器 终止容器 进入容器 attach命令 exec命令 导出和导入容器 导出容器 导入容器 删除容器 Docker容器 容器是 ...
- Java 将Word转为OFD
通常在工作中比较常用到的Microsoft Word是属于国外的文档内容编辑软件,其编译技术均属国外.而OFD是一种我国的自主文档格式,在某些特定行业或企业的文档存储技术上是一种更为安全的选择.下面将 ...
- 从一次解决Nancy参数绑定“bug”开始发布自己的第一个nuget包(上篇)
起因 最近,同事跟我说,他们负责的一个Api程序出现了一些很奇怪的事情.这个Api是为环保局做的一个扬尘质控大屏提供数据的,底层是基于Nancy做的.因为发现有些接口的数据出现异常,他就去调试了一下, ...
- C#中继承和多态
1.继承的概念 继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用已存在的类的功能. 为了提高软件模块的可复用性和可扩充性,以便提高软件的开发效率,我们总 ...