第12篇-认识CodeletMark
InterpreterCodelet依赖CodeletMark完成自动创建和初始化。CodeletMark继承自ResourceMark,允许自动析构,执行的主要操作就是,会按照InterpreterCodelet中存储的实际机器指令片段分配内存并提交。这个类的定义如下:
class CodeletMark: ResourceMark {
private:
InterpreterCodelet* _clet; // InterpreterCodelet继承自Stub
InterpreterMacroAssembler** _masm;
CodeBuffer _cb;
public:
// 构造函数
CodeletMark(
InterpreterMacroAssembler*& masm,
const char* description,
Bytecodes::Code bytecode = Bytecodes::_illegal):
// AbstractInterpreter::code()获取的是StubQueue*类型的值,调用request()方法获取的
// 是Stub*类型的值,调用的request()方法实现在vm/code/stubs.cpp文件中
_clet( (InterpreterCodelet*)AbstractInterpreter::code()->request(codelet_size()) ),
_cb(_clet->code_begin(), _clet->code_size())
{
// 初始化InterpreterCodelet中的_description和_bytecode属性
_clet->initialize(description, bytecode);
// InterpreterMacroAssembler->MacroAssembler->Assembler->AbstractAssembler
// 通过传入的cb.insts属性的值来初始化AbstractAssembler的_code_section与_oop_recorder属性的值
// create assembler for code generation
masm = new InterpreterMacroAssembler(&_cb); // 在构造函数中,初始化r13指向bcp、r14指向本地局部变量表
_masm = &masm;
}
// ... 省略析构函数
};
在构造函数中主要完成2个任务:
(1)初始化InterpreterCodelet类型的变量_clet。对InterpreterCodelet实例中的3个属性赋值;
(2)创建一个InterpreterMacroAssembler实例并赋值给masm与_masm,此实例会通过CodeBuffer向InterpreterCodelet实例写入机器指令。
在析构函数中,通常在代码块结束时会自动调用析构函数,在析构函数中完成InterpreterCodelet使用的内存的提交并清理相关变量的值。
1、CodeletMark构造函数
在CodeletMark构造函数会从StubQueue中为InterpreterCodelet分配内存并初始化相关变量
在初始化_clet变量时,调用AbstractInterpreter::code()方法返回AbstractInterpreter类的_code属性的值,这个值在之前TemplateInterpreter::initialize()方法中已经初始化了。继续调用StubQueue类中的request()方法,传递的就是要求分配的用来存储code的大小,通过调用codelet_size()函数来获取,如下:
int codelet_size() {
// Request the whole code buffer (minus a little for alignment).
// The commit call below trims it back for each codelet.
int codelet_size = AbstractInterpreter::code()->available_space() - 2*K;
return codelet_size;
}
需要注意,在创建InterpreterCodelet时,会将StubQueue中剩下的几乎所有可用的内存都分配给此次的InterpreterCodelet实例,这必然会有很大的浪费,不过我们在析构函数中会按照InterpreterCodelet实例的实例大小提交内存的,所以不用担心浪费这个问题。这么做的主要原因就是让各个InterpreterCodelet实例在内存中连续存放,这样有一个非常重要的应用,那就是只要简单通过pc判断就可知道栈帧是否为解释栈帧了,后面将会详细介绍。
通过调用StubQueue::request()函数从StubQueue中分配内存。函数的实现如下:
Stub* StubQueue::request(int requested_code_size) {
Stub* s = current_stub();
int x = stub_code_size_to_size(requested_code_size);
int requested_size = round_to( x , CodeEntryAlignment); // CodeEntryAlignment=32
// 比较需要为新的InterpreterCodelet分配的内存和可用内存的大小情况
if (requested_size <= available_space()) {
if (is_contiguous()) { // 判断_queue_begin小于等于_queue_end时,函数返回true
// Queue: |...|XXXXXXX|.............|
// ^0 ^begin ^end ^size = limit
assert(_buffer_limit == _buffer_size, "buffer must be fully usable");
if (_queue_end + requested_size <= _buffer_size) {
// code fits in(适应) at the end => nothing to do
CodeStrings strings;
stub_initialize(s, requested_size, strings);
return s; // 如果够的话就直接返回
} else {
// stub doesn't fit in at the queue end
// => reduce buffer limit & wrap around
assert(!is_empty(), "just checkin'");
_buffer_limit = _queue_end;
_queue_end = 0;
}
}
}
// ...
return NULL;
}
通过如上的函数,我们能够清楚看到如何从StubQueue中分配InterpreterCodelet内存的逻辑。
首先计算此次需要从StubQueue中分配的内存大小,调用的相关函数如下:
调用的stub_code_size_to_size()函数的实现如下:
// StubQueue类中定义的函数
int stub_code_size_to_size(int code_size) const {
return _stub_interface->code_size_to_size(code_size);
} // InterpreterCodeletInterface类中定义的函数
virtual int code_size_to_size(int code_size) const {
return InterpreterCodelet::code_size_to_size(code_size);
} // InterpreterCodelet类中定义的函数
static int code_size_to_size(int code_size) {
// CodeEntryAlignment = 32
// sizeof(InterpreterCodelet) = 32
return round_to(sizeof(InterpreterCodelet), CodeEntryAlignment) + code_size;
}
通过如上的分配内存大小的方式可知内存结构如下:
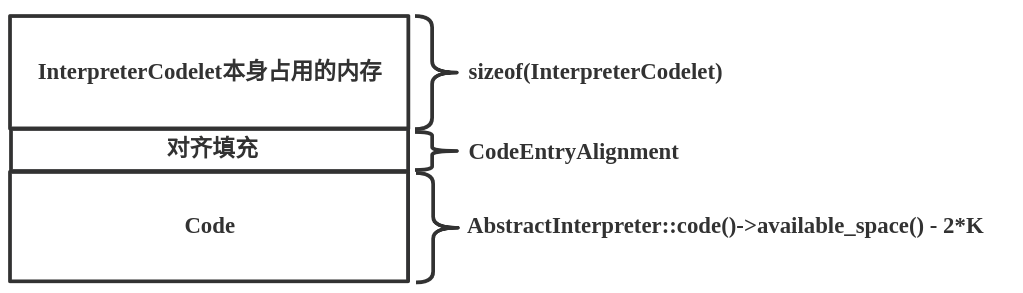
在StubQueue::request()函数中计算出需要从StubQueue中分配的内存大小后,下面进行内存分配。StubQueue::request()函数只给出了最一般的情况,也就是假设所有的InterpreterCodelet实例都是从StubQueue的_stub_buffer地址开始连续分配的。is_contiguous()函数用来判断区域是否连续,实现如下:
bool is_contiguous() const {
return _queue_begin <= _queue_end;
}
调用的available_space()函数得到StubQueue可用区域的大小,实现如下:
// StubQueue类中定义的方法
int available_space() const {
int d = _queue_begin - _queue_end - 1;
return d < 0 ? d + _buffer_size : d;
}
调用如上函数后得到的大小为下图的黄色区域部分。

继续看StubQueue::request()函数,当能满足此次InterpreterCodelet实例要求的内存大小时,会调用stub_initialize()函数,此函数的实现如下:
// 下面都是通过stubInterface来操作Stub的
void stub_initialize(Stub* s, int size,CodeStrings& strings) {
// 通过_stub_interface来操作Stub,会调用s的initialize()函数
_stub_interface->initialize(s, size, strings);
} // 定义在InterpreterCodeletInterface类中函数
virtual void initialize(Stub* self, int size,CodeStrings& strings){
cast(self)->initialize(size, strings);
} // 定义在InterpreterCodelet类中的函数
void initialize(int size,CodeStrings& strings) {
_size = size;
}
我们通过StubInterface类中定义的函数来操作Stub,至于为什么要通过StubInterface来操作Stub,就是因为Stub实例很多,所以为了避免在Stub中写虚函数(C++中对含有虚函数的类需要分配一个指针的空间指向虚函数表)浪费内存空间而采取的办法。
如上3个函数最终只完成了一件事儿,就是将此次分配到的内存大小记录在InterpreterCodelet的_size属性中。前面在介绍函数codelet_size()时提到过,这个值在存储了机器指令片段后通常还会空余很多空间,不过不要着急,下面要介绍的析构函数会根据InterpreterCodelet实例中实际生成的机器指令的大小更新这个属性值。
2、CodeletMark析构函数
析构函数的实现如下:
// 析构函数
~CodeletMark() {
// 对齐InterpreterCodelet
(*_masm)->align(wordSize); // 确保生成的所有机器指令片段都存储到了InterpreterCodelet实例中
(*_masm)->flush(); // 更新InterpreterCodelet实例的相关属性值
AbstractInterpreter::code()->commit((*_masm)->code()->pure_insts_size(), (*_masm)->code()->strings()); // 设置_masm,这样就无法通过这个值继续向此InterpreterCodelet实例中生成机器指令了
*_masm = NULL;
}
调用AbstractInterpreter::code()函数获取StubQueue。调用(*_masm)->code()->pure_insts_size()获取的就是InterpreterCodelet实例的机器指令片段实际需要的内存大小。
StubQueue::commit()函数的实现如下:
void StubQueue::commit(int committed_code_size, CodeStrings& strings) {
int x = stub_code_size_to_size(committed_code_size);
int committed_size = round_to(x, CodeEntryAlignment);
Stub* s = current_stub();
assert(committed_size <= stub_size(s), "committed size must not exceed requested size");
stub_initialize(s, committed_size, strings);
_queue_end += committed_size;
_number_of_stubs++;
}
调用stub_initialize()函数通过InterpreterCodelet实例的_size属性记录此实例中机器指令片段实际内存大小。同时更新StubQueue的_queue_end和_number_of_stubs属性的值,这样就可以为下次InterpreterCodelet实例继续分配内存了。
推荐阅读:
第2篇-JVM虚拟机这样来调用Java主类的main()方法
如果有问题可直接评论留言或加作者微信mazhimazh
关注公众号,有HotSpot VM源码剖析系列文章!

第12篇-认识CodeletMark的更多相关文章
- 《JavaScript高级程序设计》学习笔记12篇
写在前面: 这12篇博文不是给人看的,而是用来查的,忘记了什么基础知识,点开页面Ctrl + F关键字就好了 P.S.如果在对应分类里没有找到,麻烦告诉我,以便尽快添上.当然,我也会时不时地添点遗漏的 ...
- Spring第12篇—— Spring对Hibernate的SessionFactory的集成功能
由于Spring和Hibernate处于不同的层次,Spring关心的是业务逻辑之间的组合关系,Spring提供了对他们的强大的管理能力, 而Hibernate完成了OR的映射,使开发人员不用再去关心 ...
- Yeslab 华为安全HCIE七门之-防火墙基础(12篇)
Yeslab 华为安全HCIE七门之-防火墙基础(12篇) Yeslab 全套华为安全HCIE七门之第二门防火墙基础(12篇),第一门课论坛很早就有了,可自行下载,后面的陆续分享给大家. 华为安全HC ...
- Mysql高手系列 - 第12篇:子查询详解
这是Mysql系列第12篇. 环境:mysql5.7.25,cmd命令中进行演示. 本章节非常重要. 子查询 出现在select语句中的select语句,称为子查询或内查询. 外部的select查询语 ...
- CVPR2020文章汇总 | 点云处理、三维重建、姿态估计、SLAM、3D数据集等(12篇)
作者:Tom Hardy Date:2020-04-15 来源:CVPR2020文章汇总 | 点云处理.三维重建.姿态估计.SLAM.3D数据集等(12篇) 1.PVN3D: A Deep Point ...
- [转]12篇学通C#网络编程——第二篇 HTTP应用编程(上)
本文转自:http://www.cnblogs.com/huangxincheng/archive/2012/01/09/2316745.html 我们学习网络编程最熟悉的莫过于Http,好,我们就从 ...
- 12篇学通C#网络编程
转自:http://www.cnblogs.com/huangxincheng/archive/2012/01/03/2310779.html 在C#的网络编程中,进程和线程是必备的基础知识,同时也是 ...
- spring 5.x 系列第12篇 —— 整合memcached (代码配置方式)
文章目录 一.说明 1.1 XMemcached客户端说明 1.2 项目结构说明 1.3 依赖说明 二.spring 整合 memcached 2.1 单机配置 2.2 集群配置 2.3 存储基本类型 ...
- #第 12 篇:解锁博客侧栏,GoGoGo!
作者:HelloGitHub-追梦人物 文中涉及的示例代码,已同步更新到 HelloGitHub-Team 仓库 我们的博客侧边栏有四项内容:最新文章.归档.分类和标签云.这些内容相对比较固定和独立, ...
随机推荐
- XSS一些总结
XSS一些总结 除了script以外大多标签自动加载触发JS代码大多用的都是on事件,以下标签都可以用下面的方法去打Cookie以及url等 常见标签 <img><input> ...
- java集合(4)-Set集合
Set集合,类似于一个罐子,程序可以把多个对象"丢进"Set集合,而Set集合通常不能记住每个元素的添加顺序.Set集合与Collection基本相同,没有提供任何额外的方法.实际 ...
- Flyway使用说明
Flyway简介 Flyway是源自Google的数据库版本控制插件.项目开发中,数据库往往需要随着软件版本进行变化,相比起手动执行SQL脚本,flyway可以实现自动化的数据库版本修改,让开发/测试 ...
- 前端开发入门到进阶附录一【JQuery中parent(),parents(),parentsUntil()区别和使用技巧】
JQuery中parent(),parents(),parentsUntil()区别和使用技巧:https://blog.csdn.net/china1223/article/details/5193 ...
- bash对一个目录中文件名的遍历
for var in * 对当前目录中文件名的遍历 for var in /xx/xx/* 对绝对路径目录的遍历 ${var##*/} 变量扩展取文件名的基名 $var =~ ^[0-9] ...
- Python语言对Json对象进行新增替换操作
# Json字符串进行新增操作import jsonimport os# os.path.dirname(__file__):表示当前目录path = os.path.join(os.path.dir ...
- 为了让她学画画——熬夜用canvas实现了一个画板
前言 大家好,我是Fly, canvas真是个强大的东西,每天沉迷这个无法自拔, 可以做游戏,可以对图片处理,后面会给大家分享一篇,canvas实现两张图片找不同的功能, 听着是不是挺有意思的, 有点 ...
- python解析excel
import xlrd, base64excel_obj = xlrd.open_workbook(file_contents=base64.decodestring(filename)).#打开要解 ...
- mysql中的with rollup得到group by的汇总信息
使用mysql中的with rollup可以得到每个分组的汇总级别的数据: 表如下: CREATE TABLE `test3` ( `id` int(5) unsigned NOT NULL AUT ...
- 如何在windows 11中安装WSLG(WSL2)
什么是 WSL WSL(Windows Subsystem for Linux):Windows 系统中的一个子系统,在这个子系统上可以运行 Linux 操作系统. 可以让开发人员直接在 Window ...