1.深入TiDB:初见TiDB
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/584
本篇文章应该是我研究的 TiDB 的第一篇文章,主要是介绍整个 TiDB 架构以及它能支持哪些功能为主。至于其中的细节,我也是很好奇,所以不妨关注一下,由我慢慢讲述。
为什么要研究 TiDB ?
其实 TiDB 我想要了解已经很久了,但是一直都有点不想去面对这么大一滩代码。由于在项目组当中一直用的是 Mysql,但是数据量越来越大,有些表的数据量已达上亿,数据量在这个数量级其实对 Mysql 来说已经是非常吃力了,所以想找个分布式的数据库。
于是找到了腾讯主推的一款金融级别数据库 TDSQL。TDSQL 是基于 MariaDB 内核 ,结合 mysql-proxy、ZooKeeper 等开源组件实现的数据库集群系统,并且基于 MySQL 半同步的机制,在内核层面做了大量优化,在性能和数据一致性方面都有大幅的提升,同时完全兼容 MySQL 语法,支持 Shard 模式(中间件分库分表)和 NoShard 模式(单机实例)。
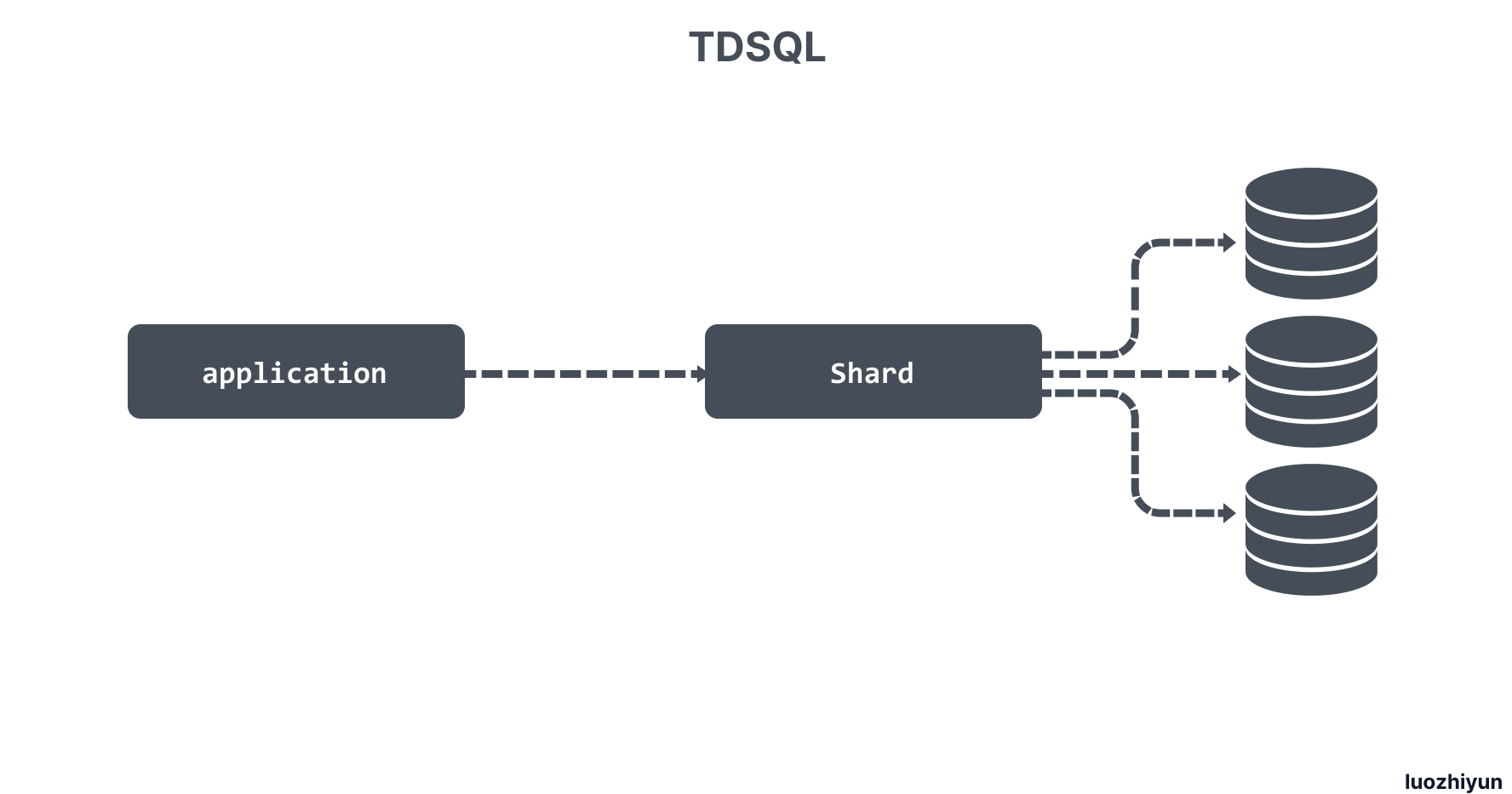
通过 TDSQL 的 Shard 模式把一个表 Shard 之后再处理其实需要在功能上做一些牺牲,并且对应用的侵入性比较大,比如所有的表必须定义 shard-key ,对有些分布式事务的场景可能会有瓶颈。
所以在这个背景下我开始研究 NewSQL 数据库,而 TiDB 是 NewSQL 行业中的代表性产品 。
对于 NewSQL 数据库可能很多人都没听过,这里说一下 。NewSQL 比较通用的定义是:一个能兼容类似 MySQL 的传统单机数据库、可水平扩展、数据强一致性同步、支持分布式事务、存储与计算分离的关系型数据库。
TiDB 介绍
根据官方的介绍 TiDB 具有以下优势:
- 支持弹性的扩缩容;
- 支持 SQL,兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL;
- 默认支持高可用,自动进行数据修复和故障转移;
- 支持 ACID 事务;
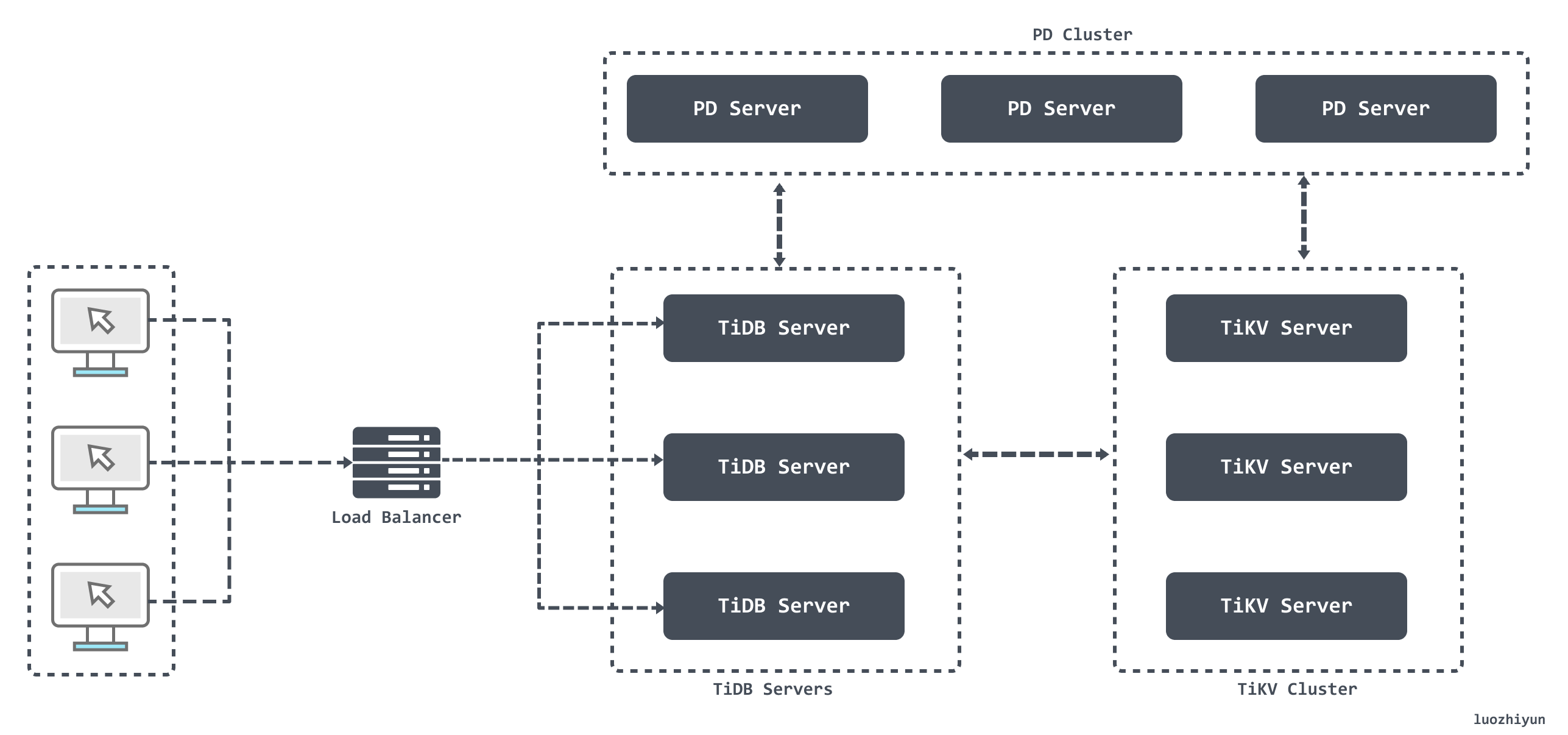
从图上我们可以看出主要分为:TiDB Server 、PD (Placement Driver) Server、存储节点。
- TiDB Server:TiDB Server 本身并不存储数据,负责接受客户端的连接,解析 SQL,将实际的数据读取请求转发给底层的存储节点;
- PD (Placement Driver) Server:负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,并为分布式事务分配事务 ID。同时它还负责下发数据调度命令给具体的 TiKV 节点;
- 存储节点:存储节点主要有两部分构成 TiKV Server 和 TiFlash
- TiKV :一个分布式的提供事务的 Key-Value 存储引擎;
- TiFlash:专门解决OLAP场景。借助ClickHouse实现高效的列式计算
TiDB 存储
这里主要介绍 TiKV 。TiKV 其实可以把它想像成一个巨大的 Map,用来专门存储 Key-Value 数据。但是数据都会通过 RocksDB 保存在磁盘上。
TiKV 存放的数据也是分布式的,它会通过 Raft 协议(关于 Raft 可以看这篇:https://www.luozhiyun.com/archives/287)把数据复制到多台机器上。
TiKV 每个数据变更都会落地为一条 Raft 日志,通过 Raft 的日志复制功能,将数据安全可靠地同步到复制组的每一个节点中。少数几台机器宕机也能通过原生的 Raft 协议自动把副本补全,可以做到对业务无感知。
TiKV 将整个 Key-Value 空间分成很多段,每一段是一系列连续的 Key,将每一段叫做一个 Region。每个 Region 中保存的数据默认是 144MB,我这里还是引用官方的一张图:
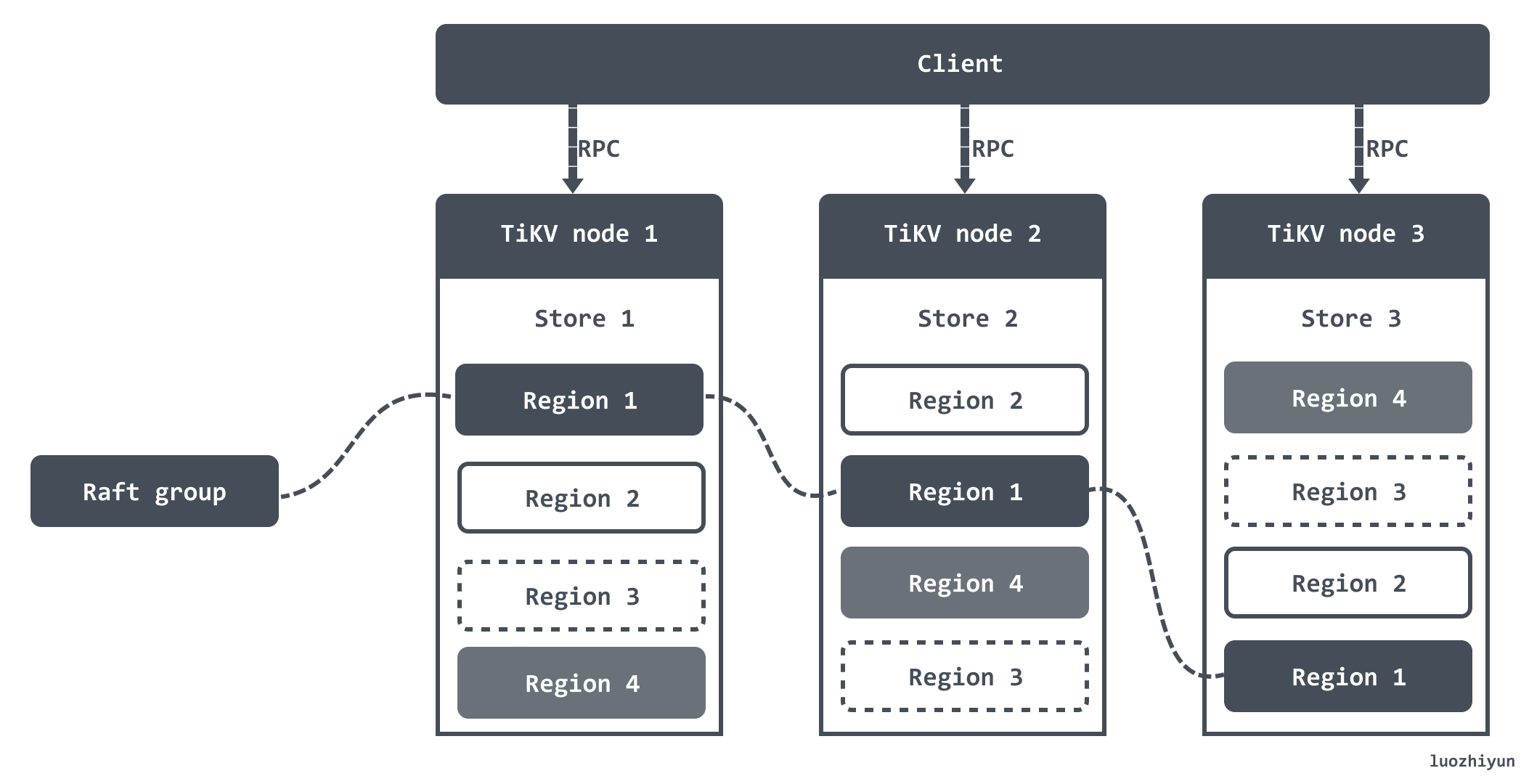
当某个 Region 的大小超过一定限制(默认是 144MB),TiKV 会将它分裂为两个或者更多个 Region,以保证各个 Region 的大小是大致接近的,同样,当某个 Region 因为大量的删除请求导致 Region 的大小变得更小时,TiKV 会将比较小的两个相邻 Region 合并为一个。
将数据划分成 Region 后,TiKV 会尽量保证每个节点上服务的 Region 数量差不多,并以 Region 为单位做 Raft 的复制和成员管理。
Key-Value 映射数据
由于 TiDB 是通过 TiKV 来存储的,但是关系型数据库中,一个表可能有很多列,这就需要将一行中各列数据映射成一个 (Key, Value) 键值对。
比如有这样一张表:
CREATE TABLE User (
ID int,
Name varchar(20),
Role varchar(20),
Age int,
PRIMARY KEY (ID),
KEY idxAge (Age)
);
表中有三行数据:
1, "TiDB", "SQL Layer", 10
2, "TiKV", "KV Engine", 20
3, "PD", "Manager", 30
那么这些数据在 TiKV 上存储的时候会构建 key。对于主键和唯一索引会在每条数据带上表的唯一 ID,以及表中数据的 RowID。如上面的三行数据会构建成:
t10_r1 --> ["TiDB", "SQL Layer", 10]
t10_r2 --> ["TiKV", "KV Engine", 20]
t10_r3 --> ["PD", "Manager", 30]
其中 key 中 t 是表示 TableID 前缀,t10 表示表的唯一ID 是 10;key 中 r 表示 RowID 前缀,r1 表示这条数据 RowID 值是1,r2 表示 RowID 值是2 等等。
对于不需要满足唯一性约束的普通二级索引,一个键值可能对应多行,需要根据键值范围查询对应的 RowID。上面的数据中 idxAge 这个索引会映射成:
t10_i1_10_1 --> null
t10_i1_20_2 --> null
t10_i1_30_3 --> null
上面的 key 对应的意思就是:t表ID_i索引ID_索引值_RowID 。
可以看到无论是唯一索引还是二级索引,都是构建 key 的映射规则来查找数据,比如这样的一个 SQL:
select count(*) from user where name = "TiDB"
where 条件没有走索引,那么需要读取表中所有的数据,然后检查 name 字段是否是 TiDB,执行流程就是:
- 构造出 Key Range ,也就是需要被扫描的数据范围,这个例子中是全表,所以 Key Range 就是
[0, MaxInt64); - 扫描 Key Range 读取数据;
- 对读取到的数据进行过滤,计算
name = "TiDB"这个表达式,如果为真,则向上返回这一行,否则丢弃这一行数据; - 计算
Count(*):对符合要求的每一行,累计到Count(*)的结果上面。
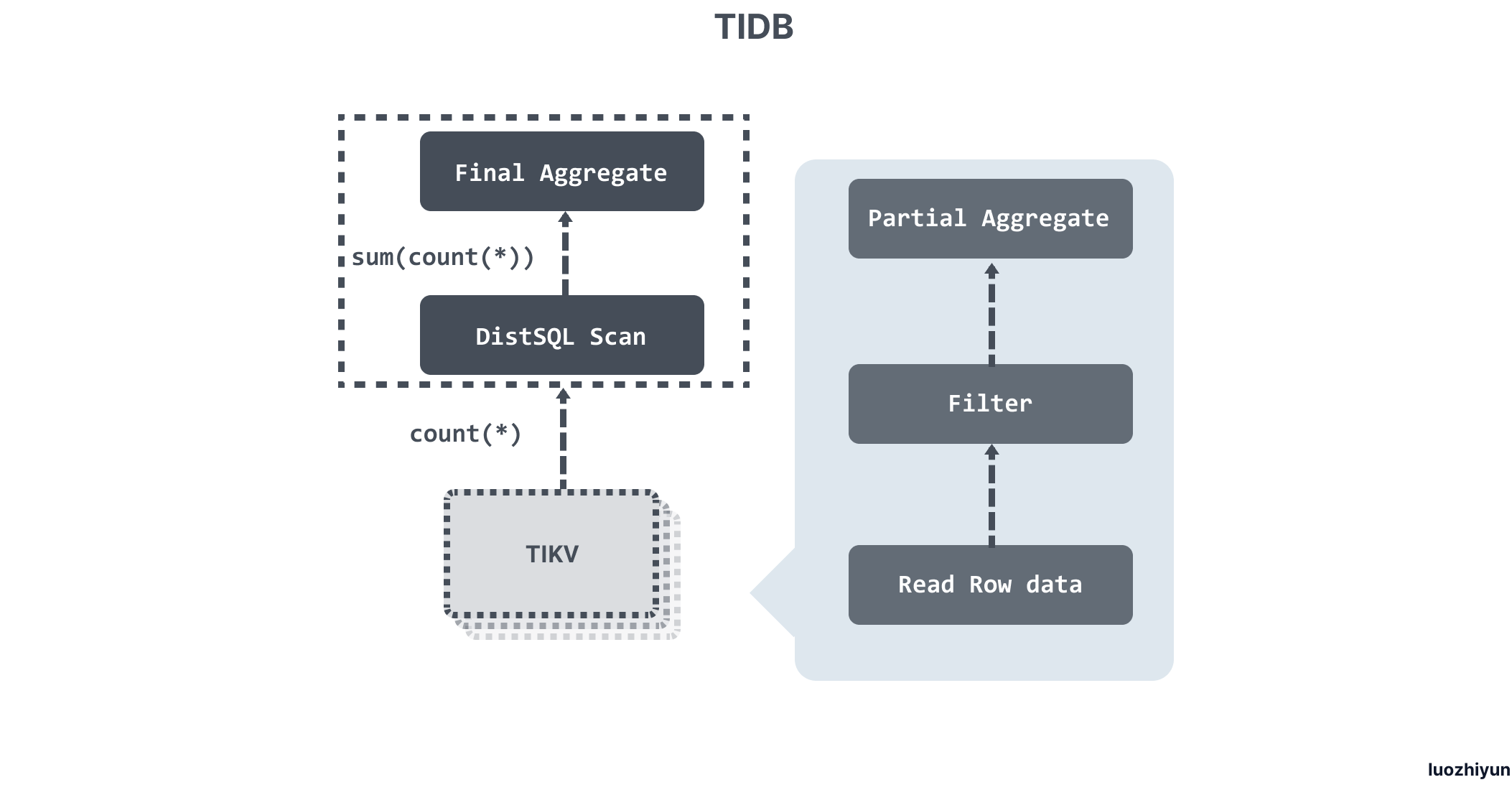
SQL 执行过程

- Parser & validator:将文本解析成结构化数据,也就是抽象语法树 (AST),然后对 AST 进行合法性验证;
- Logical Optimize 逻辑优化:对输入的逻辑执行计划按顺序应用一些优化规则,从而使整个逻辑执行计划变得更好。例如:关联子查询去关联、Max/Min 消除、谓词下推、Join 重排序等;
- Physical Optimize 物理优化:用来为上一阶段产生的逻辑执行计划制定物理执行计划。优化器会为逻辑执行计划中的每个算子选择具体的物理实现。对于同一个逻辑算子,可能有多个物理算子实现,比如
LogicalAggregate,它的实现可以是采用哈希算法的HashAggregate,也可以是流式的StreamAggregate; - Coprocessor :在 TiDB 中,计算是以 Region 为单位进行,SQL 层会分析出要处理的数据的 Key Range,再将这些 Key Range 根据 PD 中拿到的 Region 信息划分成若干个 Key Range,最后将这些请求发往对应的 Region,各自 Region 对应的 TiKV 数据并计算的模块称为 Coprocessor ;
- TiDB Executor:TiDB 会将 Region 返回的数据进行合并汇总结算;
事务
作为分布式数据库,分布式事务是既是重要特性之一。TiDB 实现了快照隔离级别的分布式事务,支持悲观事务和乐观事务。
- 乐观事务:事务间没有冲突或允许事务因数据冲突而失败;追求极致的性能。
- 悲观事务:事务间有冲突且对事务提交成功率有要求;因为加锁操作的存在,性能会比乐观事务差。
乐观事务
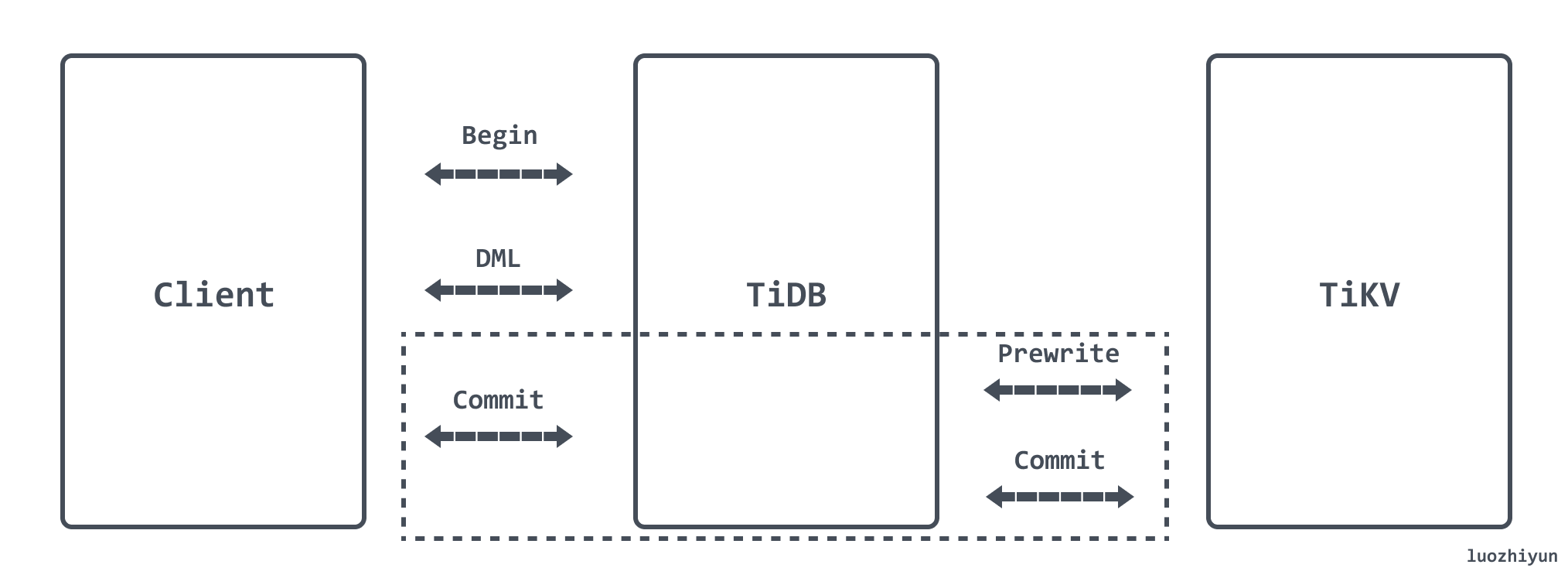
TiDB 使用两阶段提交(Two-Phase Commit)来保证分布式事务的原子性,分为 Prewrite 和 Commit 两个阶段:
- Prewrite
- TiDB 从当前要写入的数据中选择一个 Key 作为当前事务的 Primary Key;
- TiDB 并发地向所有涉及的 TiKV 发起 Prewrite 请求;
- TiKV 检查数据版本信息是否存在冲突,符合条件的数据会被加锁;
- TiDB 收到所有 Prewrite 响应且所有 Prewrite 都成功;
- Commit
- TiDB 向 TiKV 发起第二阶段提交;
- TiKV 收到 Commit 操作后,检查锁是否存在并清理 Prewrite 阶段留下的锁;
使用乐观事务模型时,在高冲突率的场景中,事务很容易提交失败。
悲观事务
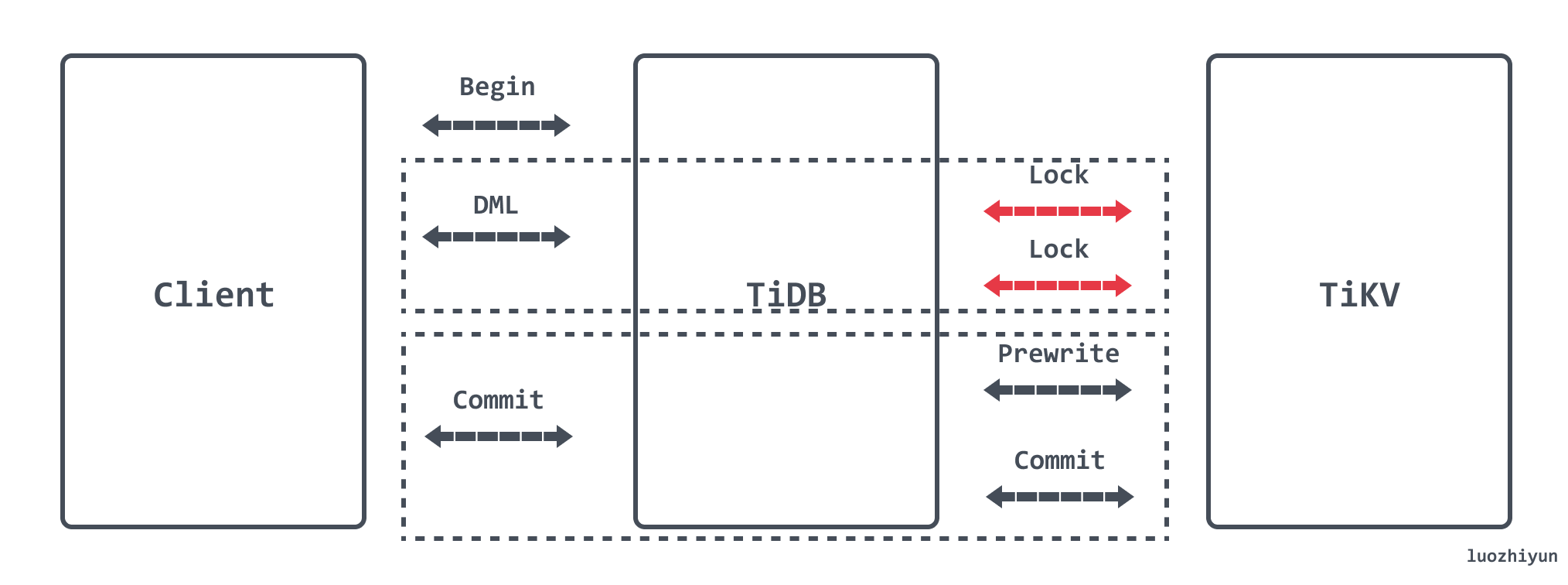
悲观事务在 Prewrite 之前增加了 Acquire Pessimistic Lock 阶段用于避免 Prewrite 时发生冲突:
- 每个 DML 都会加悲观锁,锁写到 TiKV 里;
- 悲观事务在加悲观锁时检查各种约束;
- 悲观锁不包含数据,只有锁,只用于防止其他事务修改相同的 Key,不会阻塞读;
- 提交时悲观锁的存在保证了 Prewrite 不会发生 Write Conflict,保证了提交一定成功;
总结
这篇文章当中我们大致了解到了,作为一个分布式的关系型数据库 TiDB 它的整体架构是怎样的。如何通过 Key-Value 的形式存储数据,它的 SQL 是如何执行的,以及作为关系型数据库的事务支持度怎么样。
Reference
https://www.infoq.cn/article/mfttecc4y3qc1egnnfym
https://pingcap.com/cases-cn/user-case-webank/
https://docs.pingcap.com/zh/tidb/stable/tidb-architecture
https://pingcap.com/blog-cn/tidb-internal-1/
https://pingcap.com/blog-cn/tidb-internal-2/
https://pingcap.com/blog-cn/tidb-internal-3/
https://docs.pingcap.com/zh/tidb/stable/tidb-best-practices

1.深入TiDB:初见TiDB的更多相关文章
- tidb 架构 ~Tidb学习系列(5)
一 简介:今天我们继续学习tidb的增量传输 二 说明: tidb高度兼容mysql,可以仿照mysql的主从同步复制机制实现mysql->tidb的增量传输 三 实验: 1 下载tidb官方工 ...
- tidb 架构 ~Tidb学习系列(4)
一 简介:今天我们继续学习tidb 二 集群管理 0 集群配置 验证 4台一组 3个kv 一个pd+server 上线 6台一组 1 动态添加kv服务 nohu ...
- tidb 架构 ~Tidb学习系列(3)
tidb集群安装测试1 环境 3台机器2 配置 server1 pd服务+tidb-server server2 tidb-kv server3 tidb-kv3 环境配置命令 ser ...
- tidb 架构 ~Tidb学习系列(2)
一 简介:咱们今天来学习导入数据篇 二 导入数据测试 1 工具 mysqldumper loader 2 下载tidb企业版工具 wget http://download.ping ...
- tidb 架构~tidb 理论学习(1)
一 简介:介绍新型NEW SQL数据库tidb 二 目的: tidb出现的目的,就是代替mysql+中间件,实现横向水平扩展 三 核心理论观点 1 MySQL 是单机数据库,只能通过 XA 来满足跨数 ...
- tidb 架构 ~Tidb学习系列(1)
一 简介:今天来研究Tidb 二 安装测试: 0 下载Tidb wget http://download.pingcap.org/tidb-latest-linux-amd64.tar.gz 按如 ...
- TiDB 作为 MySQL Slave 实现实时数据同步
由于 TiDB 本身兼容绝大多数的 MySQL 语法,所以对于绝大多数业务来说,最安全的切换数据库方式就是将 TiDB 作为现有数据库的从库接在主 MySQL 库的后方,这样对业务方实现完全没有侵入性 ...
- 分布式数据库TiDB的部署
转自:https://my.oschina.net/Kenyon/blog/908370 一.环境 CentOS Linux release 7.3.1611 (Core)172.26.11.91 ...
- TiDB 架构及设计实现
一. TiDB的核心特性 高度兼容 MySQL 大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移. 水平弹性扩展 ...
随机推荐
- 自学linux——6.安全外壳协议(ssh服务)
ssh服务 ssh(secure shell)安全外壳协议:远程连接协议,远程文件传输协议 1.协议使用端口号默认:22 若要修改,则修改ssh服务的配置文件/etc/ssh/ssh_config a ...
- CF427B
没人用ST表么?他比线段树快. 考虑先把ST表跑下来,然后循环一遍区间的起点,看一下这个区间的最大值,和 \(t\) 比较一下即可. 然后这题就做完了.ST表裸题. int f[2000010][21 ...
- 如何不耍流氓的做运维之-SHELL脚本
前言 大家都是文明人,尤其是做运维的,那叫一个斯文啊.怎么能耍流氓呢?赶紧看看,编写SHELL脚本如何能够不耍流氓. 下面的案例,我们以MySQL数据库备份SHELL脚本的案例来进行阐述: 不记录日志 ...
- GO语言安装以及国内镜像
首先,下载GO语言,国内的话用 Go下载 - Go语言中文网 - Golang中文社区 (studygolang.com) 可能会快一点 然后根据自己的系统选择下载的包,我是win10,就选go1.1 ...
- 文件上传 安鸾 Writeup
目录 Nginx解析漏洞 文件上传 01 文件上传 02 可以先学习一下文件上传相关漏洞文章: https://www.geekby.site/2021/01/文件上传漏洞/ https://xz.a ...
- Android系统编程入门系列之服务Service中的进程间通信
在上篇文章以线程间的通信方式Handler类结尾,服务Service还支持的进程间通信,又是具体怎么实现的呢?这就要用到加载服务一文中提到的AIDL语言规范了. AIDL是 Android Inter ...
- kvm虚拟化的qcow2磁盘格式的扩容方法
第一种:增加一块磁盘而另磁盘空间增大 1).先进入kvm环境,创建一块硬盘:qemu-img create -f qcow2 /home/tianke/test.qcow2 40G 2).再给增加的硬 ...
- noip模拟16
T1 是我早就忘干净的最小生成树...(特殊生成树,欧几里得生成树) 用一手prim算法一直连最小距离边 连到\(k+1\)(边界)退出即可. Code #include<cstring> ...
- [转]C# 互操作性入门系列(三):平台调用中的数据封送处理
参考网址:https://www.cnblogs.com/FongLuo/p/4512738.html C#互操作系列文章: C# 互操作性入门系列(一):C#中互操作性介绍 C# 互操作性入门系列( ...
- Aspen.net core 身份认证