python 爬虫新手入门教程
python 爬虫新手教程
一、什么是爬虫
爬虫就是把一个网站里的内容读取下来
这里我们就要学习一个知识
我们看到的网页是有一种叫HTML的语言编写的
他可以给文字显示不同的样式
如:<p>hello</p> 就会显示段落:hello
二、如何获取网页的内容
一般爬虫不会把网页内容爬下来
而是把网页源代码爬下来
就好比说:hello 会爬到 <p>hello</p>
如果要在浏览器上看源代码
只需在网页上右键点击 选择查看网页源代码即可
那么怎么用python把源代码爬下来呢?
这是要下载一个模块
在cmd里输入:
pip install requests
然后就可以用模块requests爬网页了
import requests # 导入模块 url = 'https://sina.com.cn' # 要爬的网址
html = requests.get(url) # 获取网页源代码
print(html.text) # 输出 注:需要text函数来返回源代码
输出:
细心的人可以看到后面的代码有编码问题

要把代码转成utf-8中文编码
import requests url = 'https://sina.com.cn'
html = requests.get(url)
html.encoding = 'utf-8' # 将编码设为utf-8中文编码
print(html.text)
输出

三、分析源代码
最后要在源代码中筛选出我们要的数据
需要用到模块 lxml
在cmd里输入:
pip install lxml
然后就要使用lxml来筛选数据
import requests
from lxml import etree url = 'https://sina.com.cn'
html = requests.get(url)
html.encoding = 'utf-8'
element = etree.HTML(html.text) # 获取html
result = element.xpath('//a/text()') # 进行筛选 for i in result:
print(i) # 输出
输出:

其中核心语句是
result = element.xpath('//a/text()')
而 //a/text() 的意思是获取所以的a标签的值
而常用的xpath语法如下
nodename 选取此节点的所有子节点
/ 从当前节点选取直接子节点
// 从当前节点选取子孙节点
. 选取当前节点
.. 选取当前节点的父节点
@ 选取属性
* 通配符,选择所有元素节点与元素名
@* 选取所有属性
[@attrib] 选取具有给定属性的所有元素
[@attrib='value'] 选取给定属性具有给定值的所有元素
[tag] 选取所有具有指定元素的直接子节点
[tag='text'] 选取所有具有指定元素并且文本内容是text节点
四、筛选实例
如果要在sina.com.cn读取部分新闻
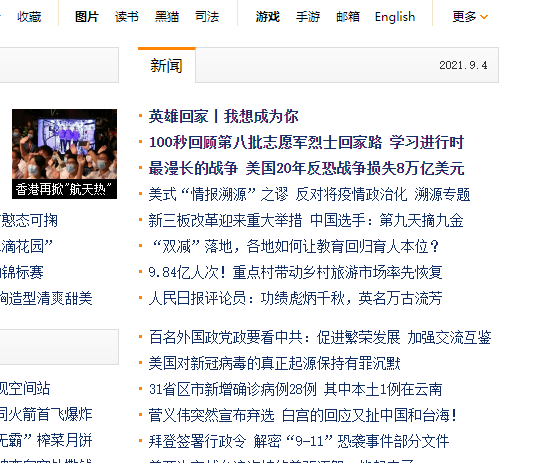
那么要在键盘上按下F12
点左上角的按钮
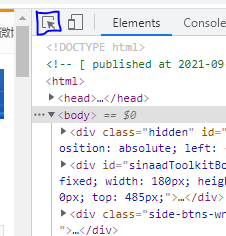
鼠标悬停在新闻上再点击
在代码栏中找新闻
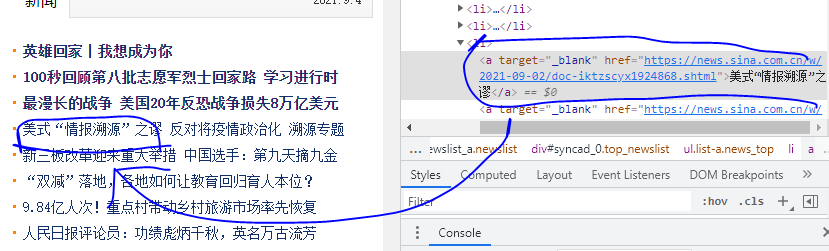
再找到所有新闻的父元素
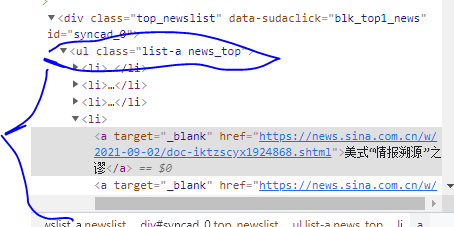
这里可以看到ul的class为list-a news_top
在python中写:
import requests
from lxml import etree url = 'https://sina.com.cn'
html = requests.get(url)
html.encoding = 'utf-8'
element = etree.HTML(html.text)
result = element.xpath('//ul[@class="list-a news_top"]//a/text()') # 进行筛选 for i in result:
print(i)
输出

python 爬虫新手入门教程的更多相关文章
- Python爬虫框架Scrapy教程(1)—入门
最近实验室的项目中有一个需求是这样的,需要爬取若干个(数目不小)网站发布的文章元数据(标题.时间.正文等).问题是这些网站都很老旧和小众,当然也不可能遵守 Microdata 这类标准.这时候所有网页 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- python爬虫如何入门
学爬虫是循序渐进的过程,作为零基础小白,大体上可分为三个阶段,第一阶段是入门,掌握必备的基础知识,第二阶段是模仿,跟着别人的爬虫代码学,弄懂每一行代码,第三阶段是自己动手,这个阶段你开始有自己的解题思 ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- 安卓自动化测试(2)Robotium环境搭建与新手入门教程
Robotium环境搭建与新手入门教程 准备工具:Robotium资料下载 知识准备: java基础知识,如基本的数据结构.语法结构.类.继承等 对Android系统较为熟悉,了解四大组件,会编写简单 ...
- Xorboot-UEFI新手入门教程
Xorboot-UEFI新手入门教程 Xorboot-UEFI是一款UEFI下轻量级的图形化多系统引导程序,pauly于2014年国庆节期间发布了预览版.搜了下论坛,关于Xorboot- ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
随机推荐
- 文件流FileStream技术出现的理由漫谈
输入输出的重要性: 输入和输出功能是Java对程序处理数据能力的提高,Java以流的形式处理数据.流是一组有序的数据序列,根据操作的类型,分为输入流和输出流. 程序从输入流读取数据,向输出流 ...
- 【Java】jeesite使用学习
初始配置环境及软件: 名称 版本 作用 Tomcat 7.0 微小型服务器,版本无所谓,装个Tomcat 9估计也没事 IntelliJ IDEA 2021.1.3 x64 2021.1.3 编译器, ...
- S3C2440—11.und异常
文章目录 1 未定义指令 2 中断向量表 3 设置一个未定义指令 4 调用C函数 5 UND异常处理程序 6 汇编源码 7 注意点 lr与pc 保存现场 中断向量表的跳转 程序执行顺序 问题 1 未定 ...
- 谈谈ARM运行C程序的内部机制
文章目录 一.代码 二.知识储备 1.ARM汇编指令 2.寄存器知识 三.代码解析 1.指令分析 第一条指令: 第二条指令: 第三条指令: 第四条指令: 第五.六条指令: 第七条指令: 第八.九.十条 ...
- STM32—SPI详解
目录 一.什么是SPI 二.SPI协议 物理层 协议层 1.通讯时序图 2.起始和停止信号 3.数据有效性 4.通讯模式 三.STM32中的SPI 简介 功能框图 1.通讯引脚 2.时钟控制逻辑 3. ...
- STM32—IIC通信(软件实现底层函数)
使用GPIO引脚模拟SDA和SCL总线实现软件模拟IIC通信,IIC的具体通信协议层和物理层链接:IIC #ifndef __BSP_IIC_H #define __BSP_IIC_H #includ ...
- 使用docker-compose部署Sentry(附Sentry数据清理)
Ubuntu下Sentry部署 Sentry作为一款常见以及使用人数较多的监控服务,在接口监控.错误捕捉.错误报警等方面是非常不错的,在此之前我也用过Prometheus监控,各有各的好处,有兴趣的同 ...
- RabbitMQ 的使用
MiaoshaMessage 类 ---------------------------------------------------------------- import com.imooc. ...
- uwp 动画之圆的放大与缩小
xml code --------------------------------------------------- <Page x:Class="MyApp.MainPage&q ...
- Quartz任务调度(4)JobListener分版本超详细解析
JobListener 我们的jobListener实现类必须实现其以下方法: 方法 说明 getName() getName() 方法返回一个字符串用以说明 JobListener 的名称.对于注册 ...