Hadoop完全分布式的配置
选取机器sam01作为主节点,并进行分布式文件的配置
1.进入Hadoop配置文件路径/usr/local/hadoop/etc/hadoop(这里我把Hadoop安装在/usr/local目录下)
2.配置core-site.xml文件
<configuration>
<!-- hdfs的地址名称:schame,ip,port-->
<!-- 在Hadoop1.x的版本中,默认使用的端口是9000。在Hadoop2.x的版本中,默认使>用端口是8020 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://sam01:8020</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
3.配置hdfs-site.xml文件
<configuration>
<!-- namenode守护进程管理的元数据文件fsimage存储的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<!-- 块的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 块的大小(128M),下面的单位是字节-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>sam02:50090</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.http-address</name>
<value>sam01:50070</value>
</property>
</configuration>
4.配置mapred-site.xml
这里初始为mapred-site.xml.template文件,需要复制为mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml
<configuration>
<!-- namenode守护进程管理的元数据文件fsimage存储的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<!-- 块的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 块的大小(128M),下面的单位是字节-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>sam02:50090</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.http-address</name>
<value>sam01:50070</value>
</property>
</configuration>
6.配置yarn-site.xml
<configuration>
<!-- 指定yarn的shuffle技术-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager的主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>sam01</value>
</property>
<!--下面的可选-->
<!--指定shuffle对应的类 -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--配置resourcemanager的内部通讯地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>sam01:8032</value>
</property>
<!--配置resourcemanager的scheduler的内部通讯地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>sam01:8030</value>
</property>
<!--配置resoucemanager的资源调度的内部通讯地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>sam01:8031</value>
</property>
<!--配置resourcemanager的管理员的内部通讯地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>sam01:8033</value>
</property>
<!--配置resourcemanager的web ui 的监控页面-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>sam01:8088</value>
</property>
</configuration>
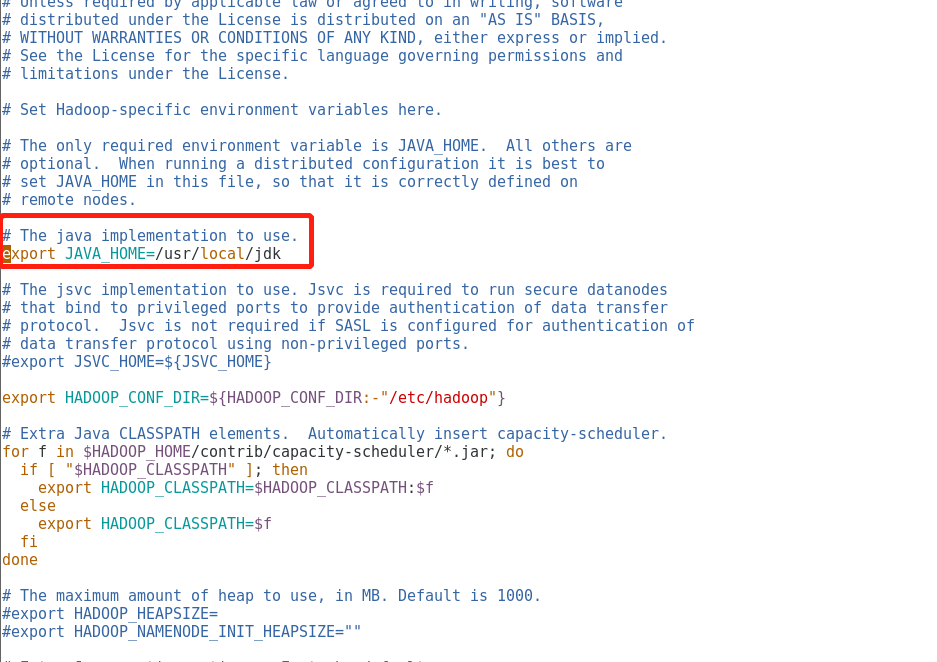
7.配置hadoop-env.sh文件
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk
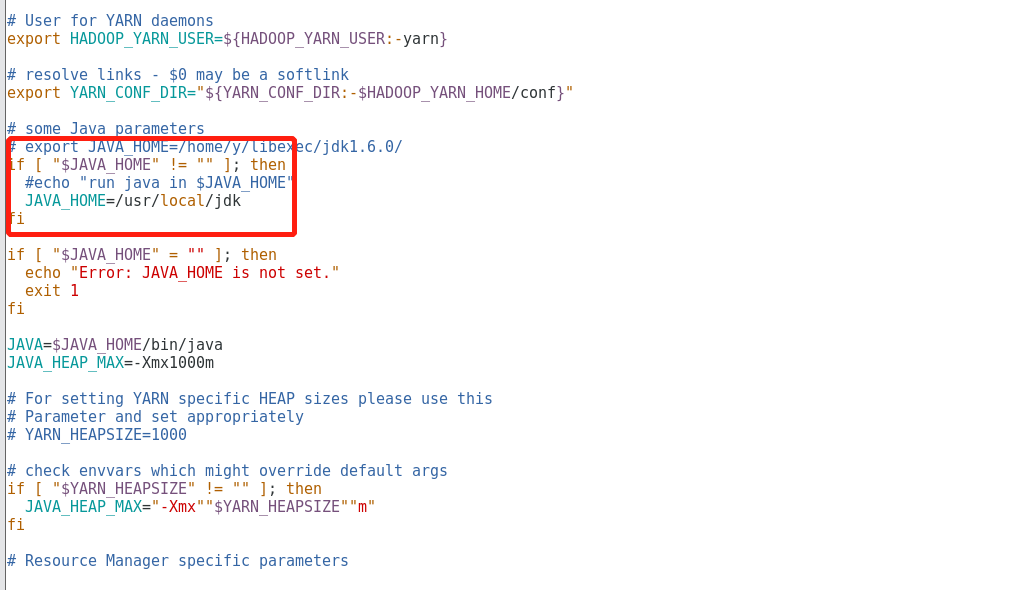
8.配置yarn-env.sh文件
#echo "run java in $JAVA_HOME"
JAVA_HOME=/usr/local/jdk
9.配置slaves文件,此文件用于指定datanode守护进程所在的机器节点主机名
sam01
sam02
sam03
10.同步Hadoop配置文件到其余的节点
cd /usr/local
scp -r hadoop/ sam02:$PWD
scp -r hadoop/ sam03:$PWD
Hadoop完全分布式的配置的更多相关文章
- Hadoop完全分布式安装配置完整过程
一. 硬件.软件准备 1. 硬件设备 为了方便学习Hadoop,我采用了云服务器来配置Hadoop集群.集群使用三个节点,一个阿里云节点.一个腾讯云节点.一个华为云节点,其中阿里云和腾讯云都是通过使用 ...
- Hadoop 伪分布式安装配置
- 基于Centos搭建 Hadoop 伪分布式环境
软硬件环境: CentOS 7.2 64 位, OpenJDK- 1.8,Hadoop- 2.7 关于本教程的说明 云实验室云主机自动使用 root 账户登录系统,因此本教程中所有的操作都是以 roo ...
- Hadoop学习笔记(一):ubuntu虚拟机下的hadoop伪分布式集群搭建
hadoop百度百科:https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin hadoop官网:http://hadoop.apache.org/ ...
- hadoop的安装和配置(三)完全分布式模式
博主会用三篇文章为大家详细说明hadoop的三种模式: 本地模式 伪分布模式 完全分布模式 完全分布式模式: 前面已经说了本地模式和伪分布模式,这两种在hadoop的应用中并不用于实际,因为几乎没人会 ...
- 在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例
在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例 ...
- Hadoop伪分布式配置
一步一步来: 安装VMWARE简单,安装CentOS也简单 但是,碰到了一个问题:安装的虚拟机没有图形化界面 最后,我选择了CentOS-7-x86_64-DVD-1503-01.iso镜像 配置用户 ...
- Data - Hadoop伪分布式配置 - 使用Hadoop2.8.0和Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- 使用docker搭建hadoop环境,并配置伪分布式模式
docker 1.下载docker镜像 docker pull registry.cn-hangzhou.aliyuncs.com/kaibb/hadoop:latest 注:此镜像为阿里云个人上传镜 ...
随机推荐
- VirtualBox虚拟机安装win8/10
你可能会遇到过,需要win8来做一些操作,不过自己的本机是win7,难道要重装系统吗?操作好了后,想用回win7怎么办?这个时候,如果旁边有人的系统刚好符合你对系统的要求,那可以借用,如果使用时间太长 ...
- Appium安装部署
一.安装JDK 下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html JD ...
- 关于vue部署到nginx服务下,非根目录,刷新页面404的问题
如果在根目录则添加 try_files $uri $uri/ /index.html; 如果不在根目录则添加,格式如下 location /xxxx { try_files $uri $uri/ ...
- js- float类型相减 出现无限小数的问题
6.3 -1.1 是不是应该等于5.2? 但是js 会导致得出 5.19999999999的结果 怎么办?可以先先乘100 后相减,然是用方法 舍入为最接近的整数,然后再除于100, Math.rou ...
- Centos6.9虚拟机环境搭建
原文链接:https://www.toutiao.com/i6481534700216123918/ 一.准备工具 VMware Workstation CentOS-6.9-x86_64-minim ...
- 使用 Json Schema 定义 API
本文地址:使用 Json Schema 定义 API 前面我们介绍了 Json Schema 的基本内容,这篇文章我们结合 jsonschema2pojo 工具深入分析如何使用 Json Schema ...
- 《剑指offer》面试题32 - III. 从上到下打印二叉树 III
问题描述 请实现一个函数按照之字形顺序打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右到左的顺序打印,第三行再按照从左到右的顺序打印,其他行以此类推. 例如: 给定二叉树: [3,9,20, ...
- bom中的offset,client,scroll
简单明了
- POSIX之消息队列
my_semqueue_send.c: #include<stdio.h> #include<errno.h> #include<mqueue.h> #includ ...
- Docker+etcd+flanneld+kubernets 构建容器编排系统(1)
Docker: Docker Engine, 一个client-server 结构的应用, 包含Docker daemon,一个 用来和daemon 交互的REST API, 一个命令行应用CLI. ...